K-means算法是一种聚类算法。
分类:事先知道数据的类别,使用已知的数据训练出分类器,再对未分类的数据进行分类,属于监督学习。
聚类:事先不知道数据的类别,根据特征的相似度对数据进行聚类,属于非监督学习。
K-means算法的基本思路:
- 随机选取K个初始点为质心(类别)
- 遍历每一条数据,计算其与K个质心的距离
- 选择与之距离最近的质心作为该数据所属的类别
- 每个簇的质心更新为该簇所有点的平均值
- 重复2、3、4步骤,直到代价函数收敛到最小值
上述过程的伪代码表示如下:
创建k个点作为起始质心(经常是随机选择)
当任意一个点的簇分配结果发生改变时:
对数据集中的每个数据点:
对每个质心:
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
K-means的代价函数(又称畸变函数 Distortion function)为:
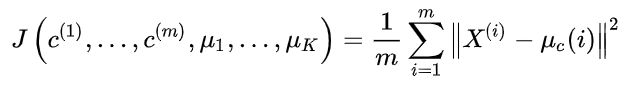
SSE(误差平方和)
对误差取了平方,因此更加重视那些远离中心的点。
其中μ_c(i)代表与x^(i)最近的聚类中心点。我们的优化目标是找出使得代价函数最小的
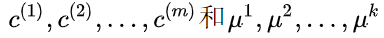
迭代的过程一定会是每一次迭代都在减小代价函数,不然便是出现了错误。
K-Means的主要优点有:
- 容易实现。
- 原理简单,收敛速度快。
- 处理大数据集较为高效。
空间复杂度为O(N),时间复杂度为O(IKN) ——N为样本点个数,K为中心点个数,I为迭代次数 - 需要调参的只有簇数K。
K-Means的主要缺点有:
-
对初值敏感,对于不同的初始值,可能会导致不同结果。
-
在簇的平均值被定义的情况下才能使用,这对于处理符号属性的数据不适用。
-
对于不是凸的数据集比较难收敛
-
对于不平衡的数据,聚类效果不佳。
-
对噪音和异常点比较敏感。
参考资料:吴恩达机器学习教程、《机器学习实战》
