在爬虫运行的时候,有时候会出现403 Forbidden的情况,也就是我们的访问次数超过了目标网站设置的阈值,这样它就会直接拒绝服务,返回一些错误信息,也就是所谓的封IP。
接下来我们尝试基于requests的代理的设置:
requests 的代理设置比 urllib 简单很多,它只需要构造代理字典,然后通过 proxies 参数即可,而不需要重新构建 Opener。
代码如下:
import requests
proxy = '113.194.28.190:9999'
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
Output:
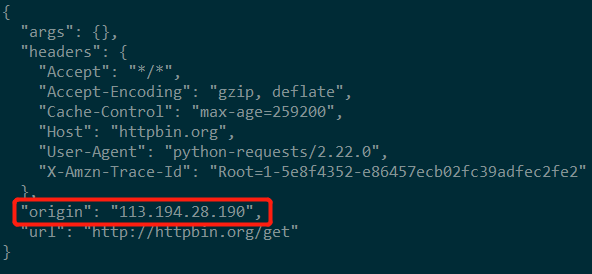
我们可以看到运行结果的 origin 是代理的IP,这证明代理已经设置成功。
如果代理需要认证,在代理的前面加上用户名和密码即可,即代理的写法变成如下所示:
proxy = 'username:[email protected]:9999'
参考资料:《Python3网络爬虫开发实战》——崔庆才
