此处准备实现线性回归中的梯度下降法。
一、构造数据:
import numpy as np
import matplotlib.pyplot as plt
x = 2 * np.random.random(size=100) # 在[0,1)范围内返回随机生成的实数
y = x * 3. + 4. + np.random.normal(size=100) # 添加噪声
X = x.reshape(-1, 1) # 变成只有一列
plt.scatter(x, y)
plt.show()
Output:

二、使用梯度下降法训练:
回顾一下梯度下降法:
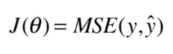
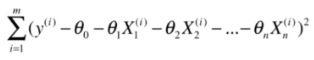

import numpy as np
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta))**2) / len(X_b)
except:
return float('inf')
def dJ(theta, X_b, y):
res = np.empty(len(theta))
res[0] = np.sum(X_b.dot(theta) - y)
for i in range(1, len(theta)):
res[i] = (X_b.dot(theta) - y).dot(X_b[:,i])
return res * 2 / len(X_b)
def gradient_descent(X_b, y, initial_theta, eta, n_iters = 1e4, epsilon = 1e-8):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if(abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_iter += 1
return theta
X_b = np.hstack([np.ones((len(x), 1)), x.reshape(-1, 1)])
initial_theta = np.zeros(X_b.shape[1])
eta = 0.01
theta = gradient_descent(X_b, y, initial_theta, eta)
print(theta)
Output:

最初的theta从0开始,theta0是截距、theta1是斜率。
三、封装梯度下降法:
在playML文件夹中写入LinearRegression模块如下:
import numpy as np
from .metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化Linear Regression模型"""
self.coef_ = None
self.intercept_ = None
self._theta = None
def fit_gd(self, X_train, y_train, eta=0.01, n_iters=1e4):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Linear Regression模型"""
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta)) ** 2) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
res = np.empty(len(theta))
res[0] = np.sum(X_b.dot(theta) - y)
for i in range(1, len(theta)):
res[i] = (X_b.dot(theta) - y).dot(X_b[:, i])
return res * 2 / len(X_b)
# return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(X_b)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y) # 计算当前点的梯度
last_theta = theta # 记录移动前的位置
theta = theta - eta * gradient # 往代价函数小的方向移动
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
四、使用封装之后的梯度下降法:
from playML.LinearRegression import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit_gd(X, y)
print(lin_reg.coef_)
print(lin_reg.intercept_)

感觉代码没问题,但是输出的斜率和截距和封装前的就是不一样……
参考资料:bobo老师机器学习教程
