Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks
1. 论文地址:
Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks
发表年份:2015年
被引量:691
这是一篇 CNN 在语音识别任务中应用的经典;
2. 摘要:
卷积神经网络(CNN)和长短期记忆(LSTM)都已在各种语音识别任务中显示出对深度神经网络(DNN)的改进,并且 CNN,LSTM 和 DNN 在建模能力上是互补的,因为 CNN 擅长减少频率变化,LSTM 擅长时间建模,而 DNN 适合将要素映射到更可分离的空间;
在本文中,作者通过将 CNN,LSTM 和 DNN 组合成一个统一的架构来利用它们的互补性,由此搭建并优化 的体系结构,被称为称为 CLDNN,用于各种词汇连续识别任务,相对于 LSTM(三个模型中最强的模型)的WER 提高了 ;
3. 核心思想:
- LSTM 的一个问题是时间建模是在输入特征 (如倒谱系数特征)上完成的,而 的高级建模可以帮助 LSTM 更容易理解输入中变化的潜在特征,从而更容易学习连续时间步长之间的时序结构; 例如,已经有研究表明,CNN 可以学习不同个体自适应或区别的训练特征,从而消除输入中的变化;
- 在 LSTM 中, 和 输出 之间的映射也不深,即没有中间的非线性隐藏层;如果可以减少隐藏状态的变化因素,那么模型的隐藏状态可以更有效地总结先前输入的上下文信息,从而使输出更容易预测;因此可以通过在 LSTM 层之后放置 DNN 层来模拟减少隐藏状态的变化;
作者提出的模型主要结构是:
- 将输入要素(由时间上下文包围)输入到几个 CNN 层以减少频谱变化;
- 将 CNN 层的输出输入到几个 LSTM 层中,以减少时间变化;
- 将最后一个 LSTM 层的输出输入到几个完全连接的 DNN 层,这些层将要素转换为一个空间,使该输出易于分类;
这篇论文的贡献之处在于,作者将 CNN,LSTM 和 CNN 合并到一个联合训练的统一框架中,从而改善LSTM性能,并通过使隐藏单元和输出之间的更深层次的映射(DNN 层提供)来输出预测;
4. CLDNN 的网络结构:
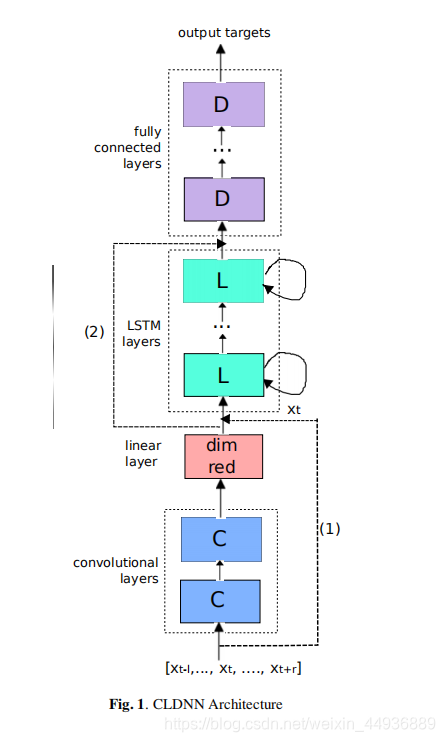
(虽然作者画的图比较草率,,,但是研究还是非常有意义的)
4.1 输入:
对于时刻 ,它的输入包括左边的 个上下文向量和右边的 个上下文向量,记为 ,并且每个向量都是 维的 log-mel 特征;
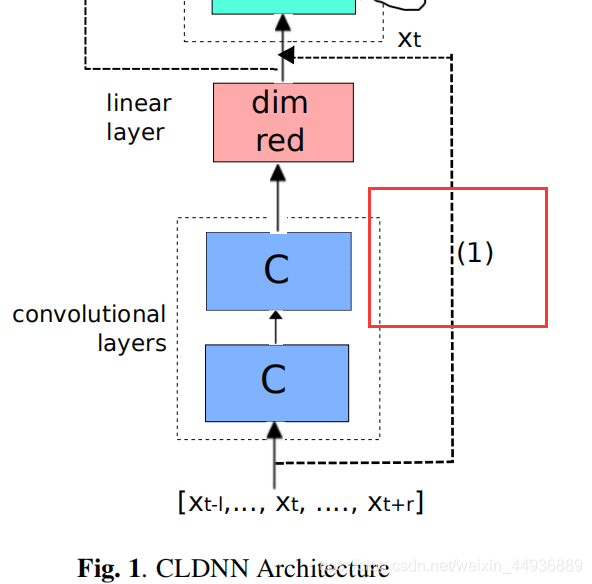
4.2 卷积层:
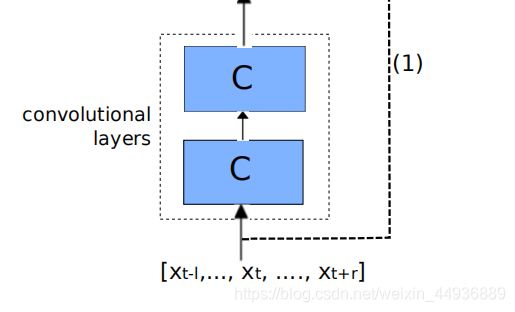
卷积层的作用是减少输入信号的频率变化;
具体来说,使用 2 个卷积层,每个卷积层具有 256 个特征图;
- 第一个卷积层使用 9x9 频率-时间滤波器;
- 第二个卷积层使用 4x3 滤波器;
这些滤波器在整个时频空间中共享;
池化使用不重叠的最大池化,并且仅按频率进行池化,第一层的池化层大小为3,第二层未进行池化;
4.2 线性层:
由于 CNN 输出大小为 特征图数×时间×频率 尺寸很大,因此作者通过添加线性层以减小特征尺寸,而不会造成精度丢失;
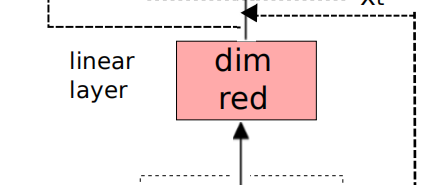
在实验中,作者发现减小维数以使线性层有 256 个输出是合适的;
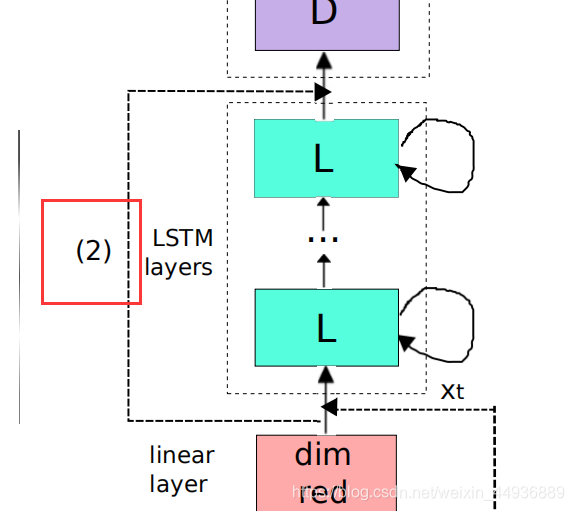
4.3 LSTM 层:
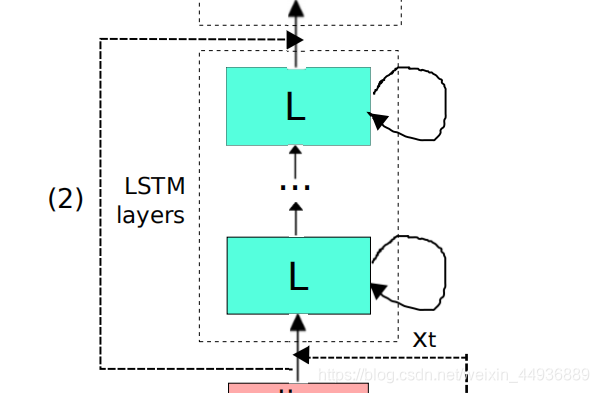
进行频率建模后,将 CNN 的输出传递到LSTM层,从而对信号进行建模;
作者使用了 2 个 LSTM 层,其中每个 LSTM 层具有 832 个单元,以及一个 512 单位的用于降维的投影层;
注意文中默认 LSTM 将展开 20 个时间步,并通过进行截断的反向传播(BPTT)训练;
此外,输出状态标签会延迟 5 帧有助于更好地预测当前帧;
为了确保 LSTM 不会看到超过 5 个未来上下文的帧从而避免解码延迟,作者为 CLDNN 设置 ;
4.4 DNN 层:
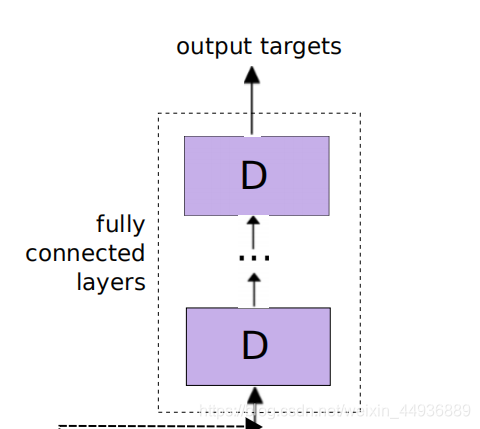
在进行频率和时间建模之后,将 LSTM 的输出传递到几个完全连接的 DNN 层,适合于生成更易于分为我们要区分的不同类别的高阶特征;
每个完全连接的层都有 1024 个隐藏单元;
4.5 多尺度叠加:
作者发现将 CNN 的输入 同时传入到 LSTM 中可以增加额外的补充信息,因此设计了虚线 (1) 的结构:
同时受计算机视觉的残差结构的启发,作者探索了在使用 LSTM 在时间上以及使用 DNN 在判别上对 CNN 输出进行建模之间是否存在互补性,并将 CNN 的输入传递到 DNN 中,如 (2) 所示:
5. 实验参数:
所有模型的输入都是 40 维的 log-mel 滤波器组特征,每 10ms 计算一次;
除非另有说明,否则所有神经网络均使用异步随机梯度下降(ASGD)优化策略并以交叉熵准则进行训练;
所有网络都有 13,522 个 CD 输出目标,并使用 Glorot-Bengio 策略初始化所有 CNN 和 DNN 层的权重;
所有 LSTM 层都将随机初始化为高斯分布,方差为1/(#inputs);
另外,学习速率是针对每个网络选择的,并且选择为最大值,以使训练保持稳定。;
学习率呈指数下降;
6. 消融实验:
作者分别在一个中等大小英语口语数据集(200 小时)、一个较大英语口语数据集(2000 小时)和一个人工添加环境噪声的数据集(2000 小时)上进行训练和评估,并采用 WER(词错率)作为评判指标;
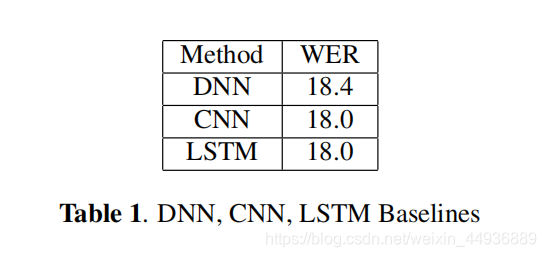
6.1 基准线:
基准模型的参数设置为:
- CNN包括 2 个具有256个特征图的卷积层和 4 个包括 1,024 个隐藏单元的全连接层;
- DNN包括 6 层,每层共有 1,024 个隐藏单元;
CNN 和 DNN 的输入都是 40 维的 log-mel 滤波器组特征,周围有 20 个过去帧和 5 个将来帧;
- LSTM 由 2 层 832 个单元的 LSTM 层和 512 个单元的维投影层训练,输入是一个 40 维 log-mel 特征,在时间上展开为 20 步,并且输出延迟了 5 帧;
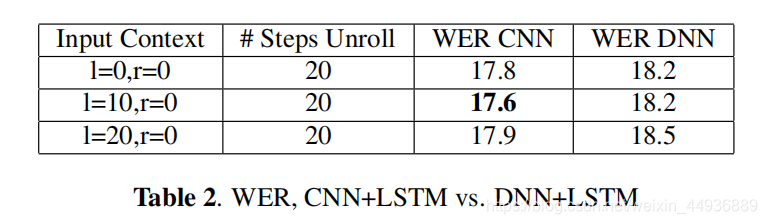
6.2 CNN+LSTM:
为确保 CLDNN 的改进不是归因于CNN(以及LSTM)的额外上下文功能,作者还探索了具有不同时间上下文的 LSTM 的行为,结果如下:
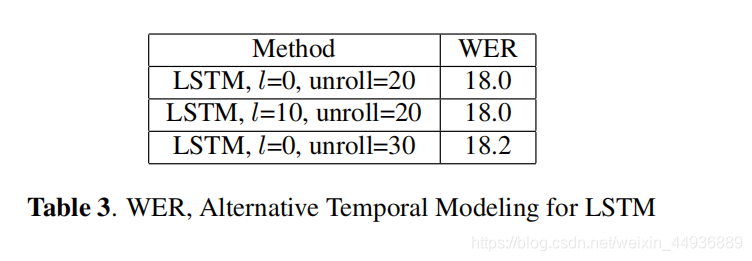
6.3 LSTM+DNN:
这里作者还探讨了在 LSTM 输出之后添加完全连接的层的效果:
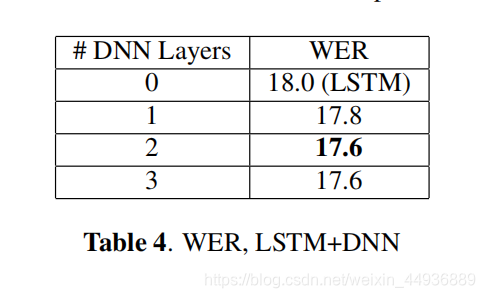
实验结果表明在完成时间建模之后,使用 DNN 层将 LSTM 层的输出转换为更具区分性和更容易预测输出目标的空间是有益的;
6.4 CNN+LSTM+DNN:
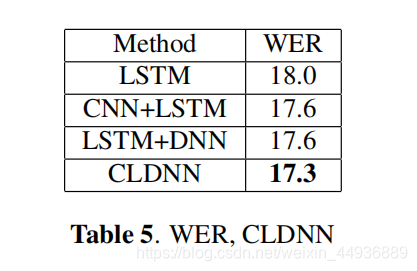
该表表明,将 CNN 和 DNN 层与 LSTM 组合在一起所获得的收益是互补的;
6.5 权重初始化:
通过适当的权重初始化,可以提高模型性能:
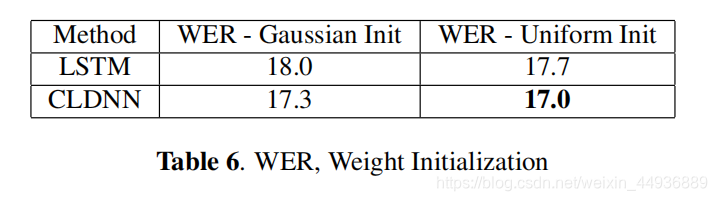
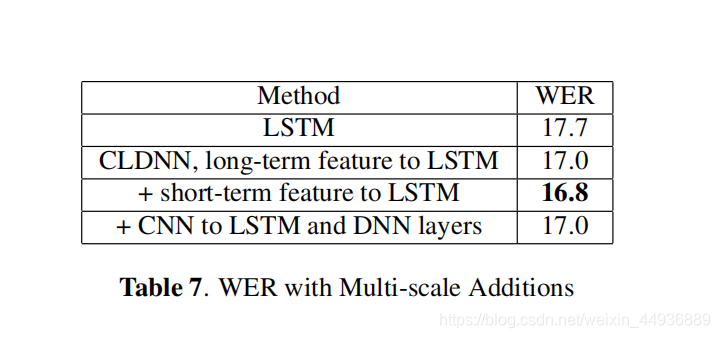
6.6 多尺度特征:

7. 实验结果:
本节在更大的数据集上比较 CLDNN 和 LSTM,以及多尺度相加模块的性能:
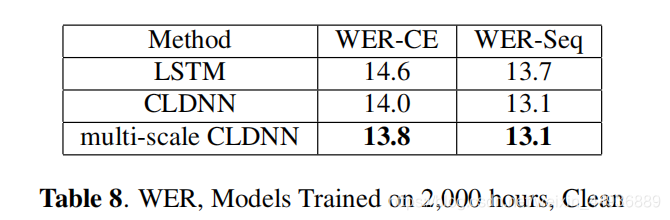
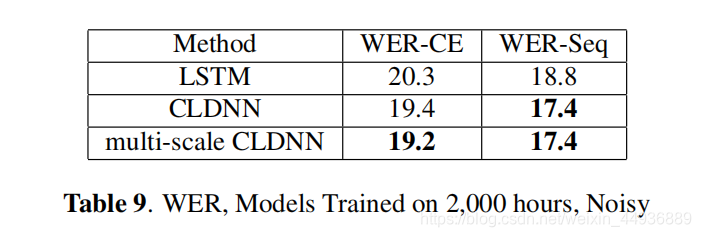
8. 结论:
在本文中,作者提出了 CNN,LSTM 和 DNN 的组合架构,称之为 CLDNN;
该体系结构使用 CNN 来减少输入特征的光谱变化,然后将其传递到 LSTM 层以执行时间建模,最后将其输出到 DNN 层,从而产生更易于分离的特征表示;
作者还为该体系结构添加了多尺度的补充,以捕获不同分辨率的信息;
各种 LVCSR 语音搜索任务的结果表明,与 LSTM 相比,CLDNN 体系结构可将 WER 相对降低 ;
