在先前的文章《Unix之IO模型》已经讲述到5种IO模型以及对应的同步异步和阻塞非阻塞相关核心概念,接下来看下Java的IO模型在服务端的网络编程中是如何演进,注意这里用启动Java程序表示一个JVM进程,而JVM进程中以多线程方式进行协作,这里讲述以线程为主展开
Java中的BIO演进
BIO 概述
- 在上篇文章中讲述到阻塞式IO是应用进程等待内核系统接收到数据报并将数据报复制到内核再返回的处理过程
- 在Java中的阻塞式IO模型(Blocking IO)网络编程中,服务端
accept&read都需要等待客户端建立连接和发起请求才能够进行让服务端程序进行响应,也就是上述的方法在服务端的编程中会让服务端的主线程产生阻塞,当其他客户端与Java服务端尝试建立连接和发请求的时候会被阻塞,等待前面一个客户端处理完之后才会处理下一个客户端的连接和请求,以上是Java的BIO体现
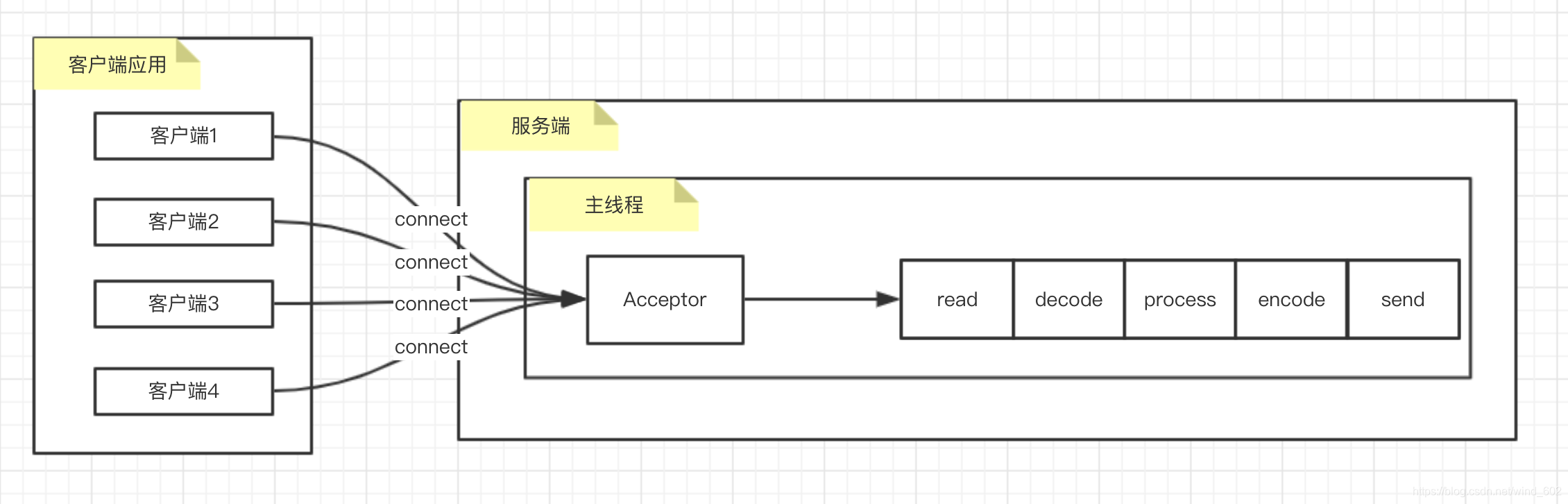
服务端单线程BIO模型
- 单线程图解
- 代码演示
// server.java
// 仅写部分服务端核心代码
ServerSocket server = new ServerSocket(ip, port);
while(true){
Socket socket = server.accept(); // 接收客户端的连接,会阻塞
out.put("收到新连接:" + socket.toString());
// client have connected
// start read
BufferedReader br = new BuufferedReader(new InputstreamReader(socket.getInputStream));
String line = br.readLine(); // 等待客户端发起请求进行读取操作,会阻塞
// decode ..
// process ..
// encode ..
// send ..
}
- 运行结果(启动两个客户端)

- 分析
- 上述代码accept方法以及read方法需要等待客户端发送数据过来,服务端才能从操作系统的底层网卡获取数据,在没有获取数据之前将处于阻塞状态
- 其次,可以看到上述的服务端程序只能处理一个客户端的连接和请求操作,只有当前的客户端连接以及请求执行完之后才能接收下一个客户端的连接以及请求处理操作
- 不足: 上述代码压根无法满足服务端处理多客户端的连接和请求,同时造成CPU空闲,尤其是在接收客户端读取的时候,如果没有客户端读取其他客户端建立的连接请求根本无法处理,因此对上述进行改进为多线程处理方式
基于1:1的多线程BIO模型
- 根据上述的BIO模型,现优化为主线程接收accept以及通过创建多线程方式处理IO的读写操作
- 一个客户端的请求处理交由服务端新创建的一个线程进行处理,主线程仍然处理接收客户端连接的操作
- 如下图

- 代码演示
// thread-task.java
public class IOTask implements Runnable{
private Socket client;
public IOTask(Socket client){
this.client = client;
}
run(){
while(!Thread.isInterrupt()){
// read from socket inputstream
// encode reading text
// process
// decode sent text
// send
}
}
}
// server.java
ServerSocket server = new ServerSocket(ip, port);
while(true){
Socket client = server.accept();
out.put(“收到新连接:” + client.toString());
new Thread(new IOTask(client)),start();
}
- 运行效果(客户端启动服务端就接收到客户端的连接)
- 分析
- 通过多线程的方式将Accept与IO读写操作的阻塞方式进行分离,主线程处理accept接收客户端的连接,新开线程接收客户端的请求进行请求处理操作
- 上述的方式仅仅是将阻塞的方式进行分离,但是如果处理的客户端数量越来越多的时候,上述服务器创建线程会越来越多,容易造成机器CPU出现100%情况,那么我们可以如何控制线程的方式,在并发编程中,一般通过管理并发处理任务的多线程技术是采用线程池的方式,于是就有了以下的M:N的多线程网络编程的BIO模型
基于M:N的线程池实现的BIO模式
- M:N的线程池实现的图解如下
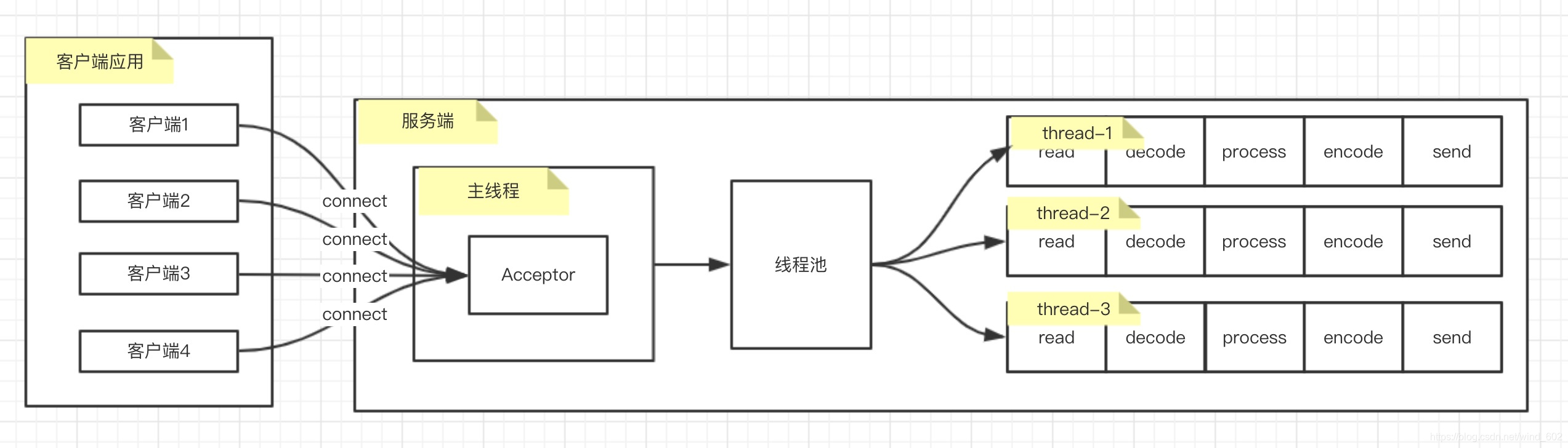
- 示例代码
// server.java
ExecutorService executors = Executros.newFixedThreadPool(MAX_THREAD_NUM);
ServerSocket server = new ServerSocket(ip,port);
while(true){
Socket client = server.accept();
out.put(“收到新连接:” + client.toString());
threadPool.submit(new IOTask(ckient));
}
- 分析
- 上述运行结果与1:1的线程模型是一致的,但是相比1:1创建线程的方式,充分利用池化技术重复利用线程资源,有助于降低CPU占用的资源
- 其次,上述的BIO都是属于阻塞式IO处理,每一次的accept操作以及read操作都需要等待客户端的操作才能给予响应,如果客户端不发生操作,那么新创建的线程将一直处于阻塞状态,将占用资源迟迟没有释放,也容易造成CPU发生瓶颈,于是我们想到能否等到客户端有发起相应的操作的时候线程才进行处理呢,在客户端还没有发生请求操作的时候,服务端线程资源是否可以优先处理其他任务,提升CPU利用率呢,这也就是接下来的非阻塞式IO,即Non-Blocking IO
Java中的NIO演进
NIO概述
- 在《Unix的IO模型》中的NIO模型有非阻塞式IO,IO复用模型以及信号驱动的IO模型,在Java中的NIO模型主要是以非阻塞式IO以及IO复用模型为主
- 从上述的BIO可知,服务端会在accept方法以及read方法调用中导致当前线程处于阻塞状态,结合Unix中的非阻塞式IO可知,NIO本质上是将上述的方法设置为非阻塞,然后通过轮询的方式来检查当前的状态是否就绪,如果是Accept就处理客户端连接事件,如果是READ就处理客户端的请求事件
- Java实现NIO的方式注意依赖于以下三个核心组件
- Channel通道:服务端与客户端建立连接以及进行数据传输的通道,分为ServerSocketChannel(接收客户端的TCP连接通道)以及SocketChannel(建立与服务端的连接通道)
- Buffer缓存区: 客户端与服务端在channel中建立一个连续数组的内存空间,用于在channel中接收和发送数据数据实现两端的数据通信
- Selector选择注册器,对比IO复用模型,Selector中包含select函数,用于向系统内核注册网络编程中的Aceept,Read以及Write等事件,相对于从Java而言,是指channel(不论是服务端还是客户端通道)可以向注册器selector发起注册事件,底层交由
select()向操作系统进行事件注册
- 简要的NIO模型图
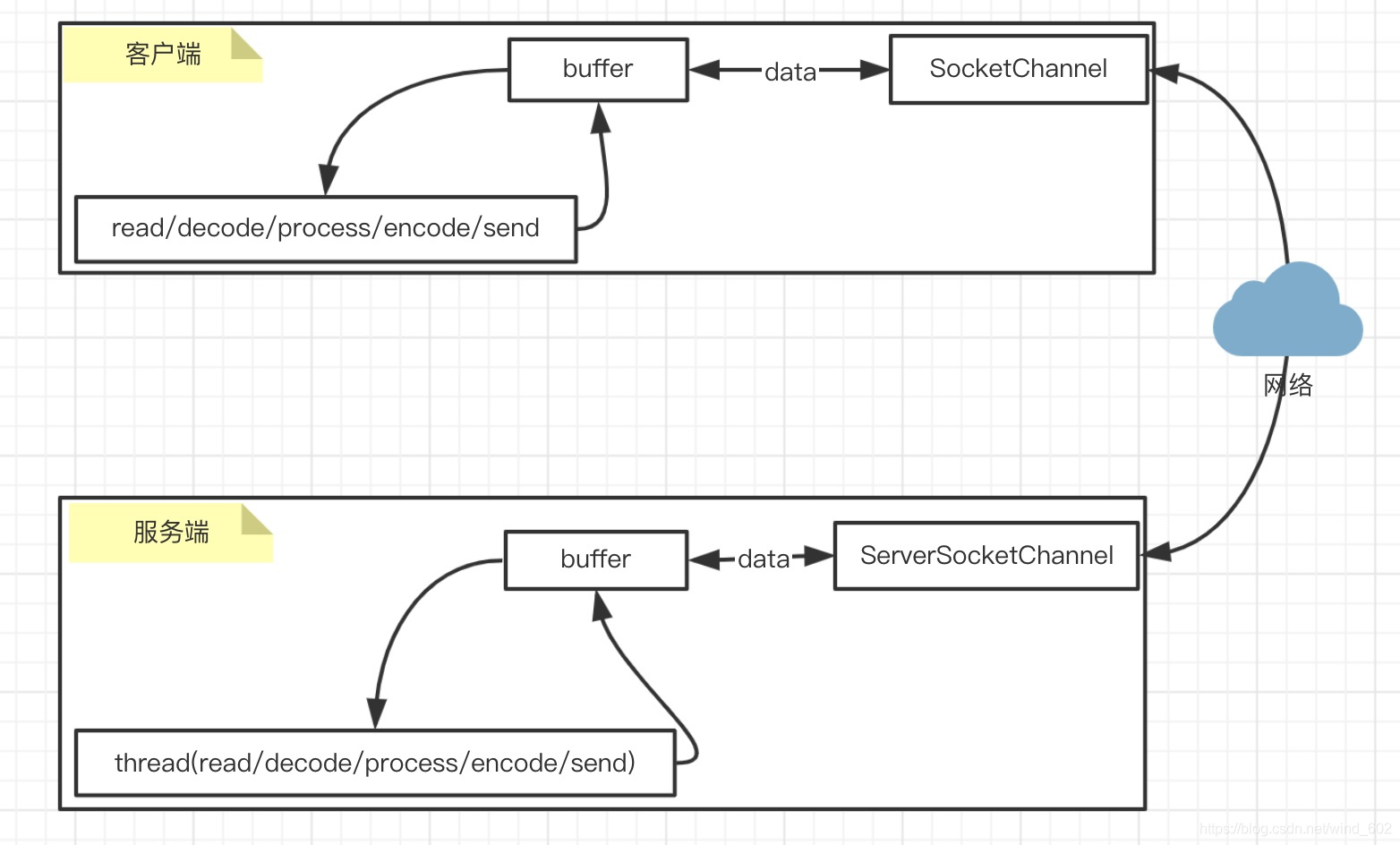
基于单线程通道轮询的NIO模式(NIO模型)
- 这类IO模型与unix下的NIO模型是一致的,就是服务端不断地检查当前的连接状态信息,如果状态信息就绪那么就开始执行相应的处理逻辑
- NIO图解模型如下
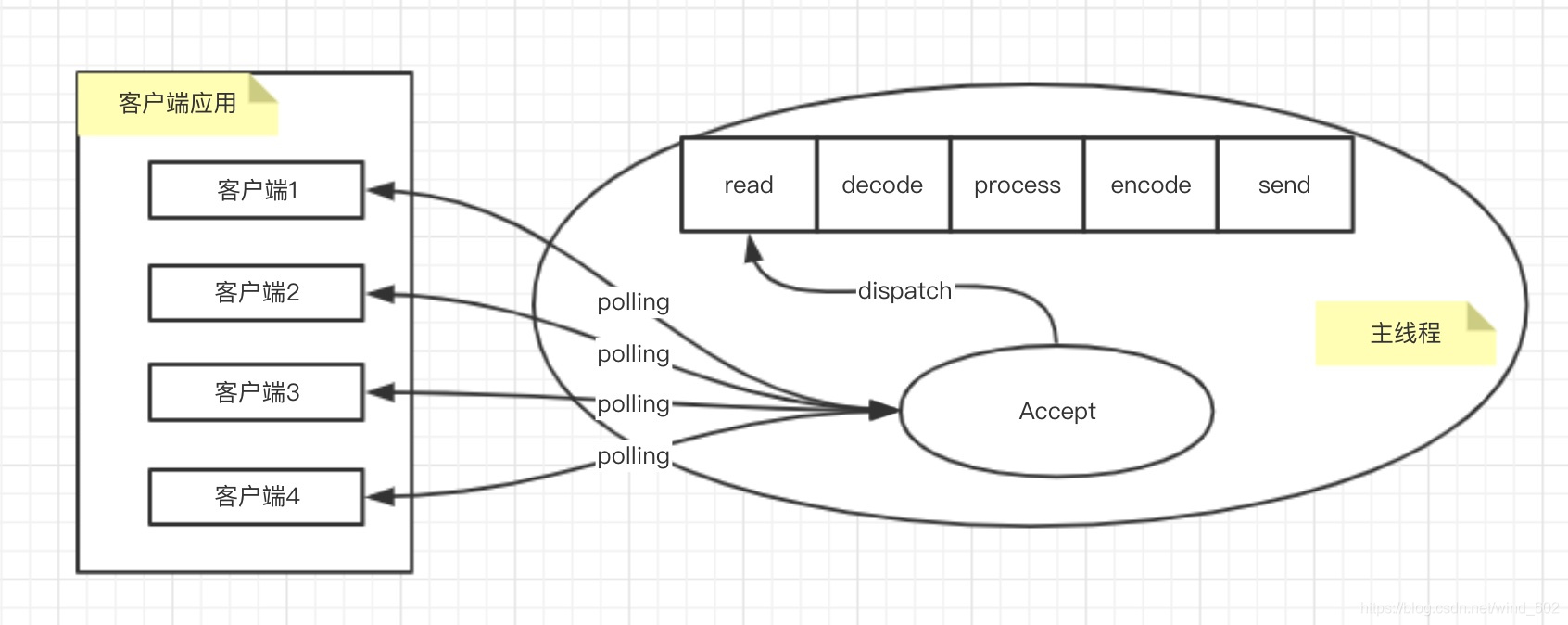
- 在NIO模型图中,accept不断polling客户端是否有建立连接,如果有客户端连接到服务端,这个时候就会将其转发进行IO操作
- 部分java示例伪代码
// server.java
ServerSocketChannel server = ServerSocketChannel.open();
// 设置所有的socket默认伪阻塞,必须设置服务端的通道为非阻塞模式
server.configureBlocking(false);
// 绑定端口以及最大可接收的连接数backlog
server.socket().bind(new InetSocketAddress(PORT), MAX_BACKLOG_NUM);
while(true){
SocketChannel client = server.accept();
// 非阻塞获取,所以client可能为null
if(null != client){
// 设置客户端的通道为非阻塞
client.configureBlocking(false);
// 进行IO操作
// read
ByteBuffer req = ByteBuffer.allocate(MAX_SIZE);
while(client.isOpen() &/& client.read(req)!= -1){
// BufferCoding是自己封装的一个解码工具类,结合ByteBuffer与Charset使用,这里不演示代码实现
// decode
byte[] data = BufferCoding.decode(req);
if(data != null){
break;
}
}
// prepared data to send
sentData = process(data);
// encode
ByteBuffer sent = BufferCoding.encode(sentData);
// write
client.writeAndFlush(sent);
}
}
- 分析
- 上述的代码与BIO的设计基本无差,只是在原有的基础上设置为非阻塞的操作,然后通过不断轮询的方式不断监控连接和读取操作,与BIO的多线程设计差别不大,只是BIO是多线程方式实现,这里是单线程实现
- 小结:上述代码使用BIO的API方式,也就是说不断polling的过程都是调用阻塞的API去检查是否就绪的状态,结合先前的Unix的IO模型,非阻塞可以继续改进为给予select的方式来实现,而select不是属于调用阻塞式API而是通过事件轮询的方式等待套接字中的描述符变为就绪状态再进行业务处理操作
基于单线程的select事件轮询IO模式(IO多路复用模型)
- IO复用模型是通过调用select函数不断轮询获取当前socket的描述符是否就绪,是基于事件的方式实现非阻塞
- 客户端与服务端都需要注册到selector上,告诉selector当前对哪个描述符感兴趣,再由selector将感兴趣的描述符注册到系统内核中,内核收到一份描述符的数组表,根据网络传输过来的事件告知selector当前对应的描述符的状态信息
- 其简要的示例图如下
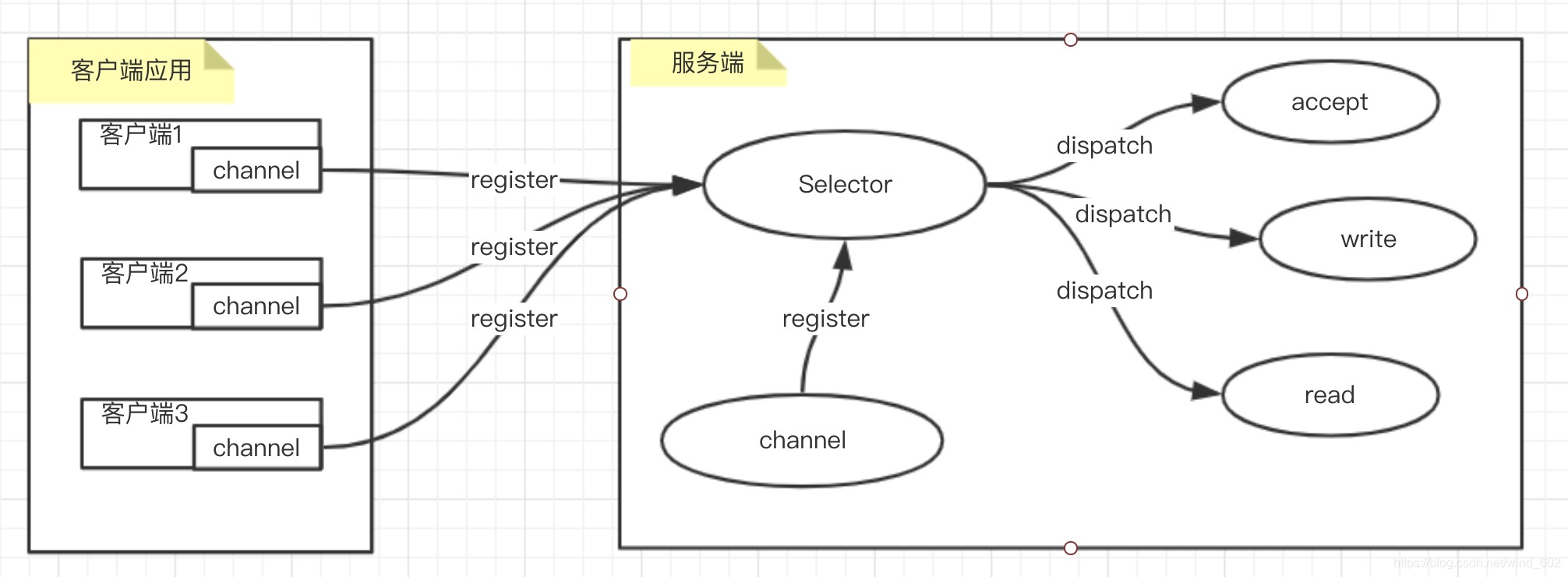
- 从上述模型可以看出
- 服务端启动的时候,首先需要创建channel并注册到selector上才能够监听到客户端建立的连接
- 其次客户端要与服务端建立通信,也需要在客户端自己创建channel并注册到selector上
- 当selector监听到客户端的连接就会转发给服务端的Accept事件进行处理
- 当selector监听到客户端发起请求的操作,就会转发给处理READ事件进行处理,并且如果需要将数据通知客户端,并且在指定的事件上添加写操作
- 此时selector监听到写操作的时候,就会转发给处理WRITE事件进行处理,并且当前在进行写操作之后取消写操作的事件
- java实现的伪代码
// server.java
ServerSocketChannel server = ServerSocketChannel,open();
server.configureBlocking(false);
Selector selector = Selector.open();
// 服务端只注册ACCEPT,作为接入客户端的连接
// DataWrap封装读写缓存ByteBuffer
server.register(selector, SelectionKey.OP_ACCEPT, server);
server.socket().bind(new InetSocketAddress(PORT), MAX_BACKLOG_NUM);
while(true){
int key = selector.select();
if(key == 0) continue;
// 获取注册到selecor所有感兴趣的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> it = keys.iterator();
while(it.hasNext()){
SelectionKey key = it.next();
it.remove();
if(key.isAcceptable()){
// 接收accept事件
ServerSocketChannel serverChannel = (ServerSocketChannel)key.attachment();
SocketChannel client = server.accept();
client.configureBlocking(false);
// 客户端已经获取到连接,告诉客户端的channel可以开始进行读写操作
client.register(selector, SelectionKey.OP_READ | SelectionKey.OP_WRITE, new DataWrap(256, 256));
}
// read
if(key.isReadable()){
//...
// 在事件中添加写操作
key.interestOps(key.interestOps() | SelectionKey.OP_WRITE);
}
if(key.isWriteable()){
// ...
// 成功完成写操作,这个时候取消写操作
key.interestOps(key.interestOps() & (~SelectionKey.OP_WRITE));
}
}
}
- 分析
- 上述代码相比第一种方案的实现,主要是采用select函数调用获取注册的事件,阻塞于select事件
- 另外上述的代码相比第一种稍微更为复杂,操作也更为繁琐
- 同时两种方式存在的不足都是单线程的方式,在接入层支撑的连接并发量大的时候,并且如果处理的业务复杂且耗时,那么无疑也将会影响到程序的性能,无法快速响应给客户端,同时也会出现短暂的阻塞
基于多线程实现的NIO(Reactor模型)
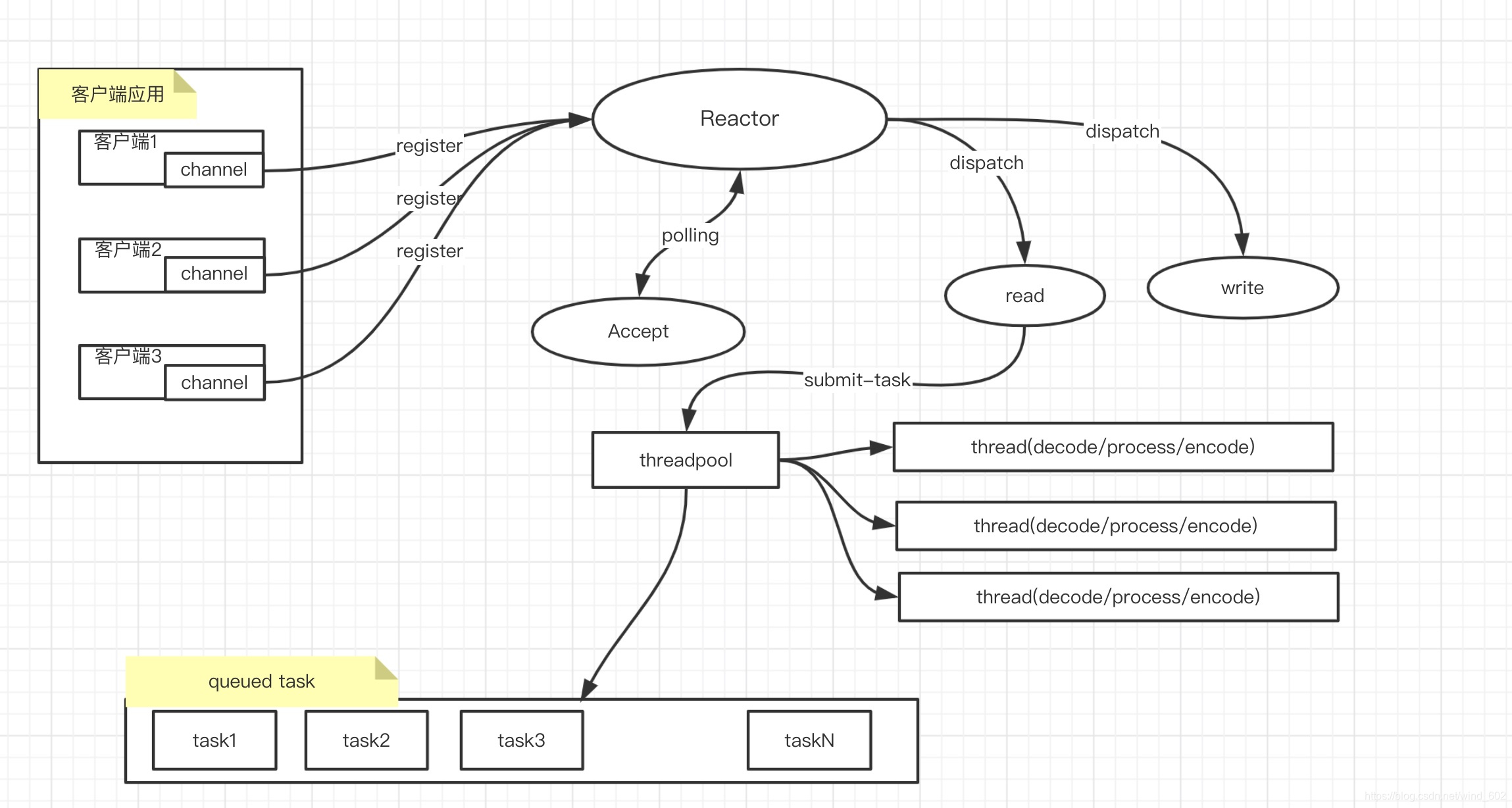
- Reactor模型是参考《Scalable in Java》的文章,目的是为了更好地利用CPU资源将selector监听到事件分别进行相应的分发提高用户响应
- Reactor中主要包含selector, channel以及事件SelectionKey,通过不断polling的方式监听客户端的连接,如果有连接进来就将连接转发给Accept,将服务端channel与客户端的channel连接起来,并告知客户端可以进行读写操作
- 后面在服务端接收到读取事件的时候,就会利用线程池的方式提交任务来处理客户端发过来的请求事件,并准备写数据到缓冲区,并再通知并注册写事件
- 接收到写事件之后,从缓存区中获取数据并刷新到客户端
- Reactor简要图如下
- 分析
- (Main)Reactor模型中主要接收服务端以及客户端的注册,其中服务端在启动的时候就注册到Reactor上,而客户端建立连接之前也需要现注册到Reactor中,再由监听到客户端连接的Reactor转发给处理Accept的事件操作,将客户端通道设置非阻塞且建立其可以进行读写的事件监听操作,对于单个而言仍然是在Reactor线程中,而多个Reactor模型中会将当前的客户端连接以及通道转给另一个Reactor进行网络IO操作
- 对于单个Reactor模型,接收到客户端的请求之后,进行读取然后向线程池提交任务去处理实际业务,在发送给客户端之前向事件注册写事件然后交由Reactor执行写数据到客户端
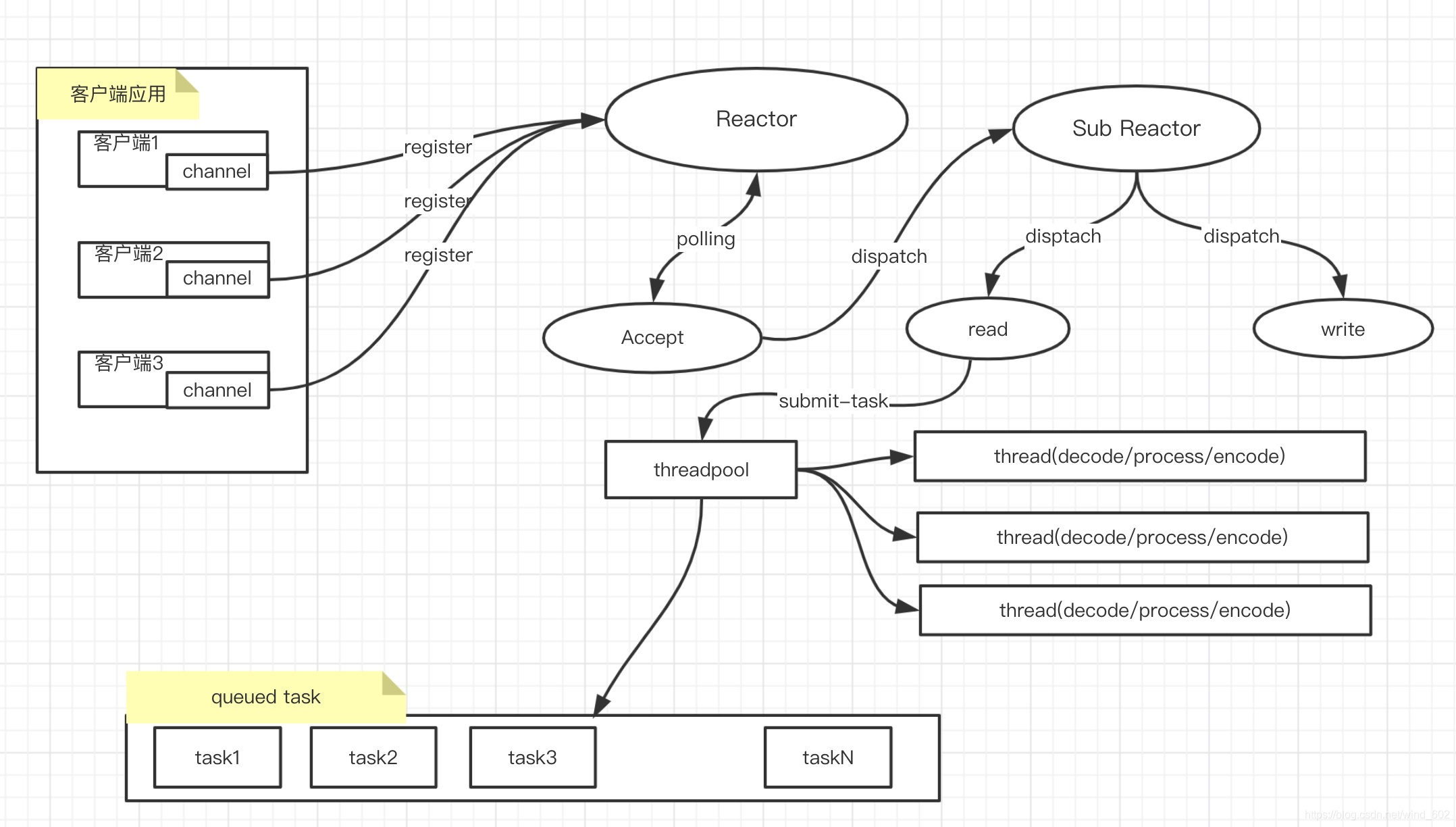
- 对于多个Reactor模型.接收到客户端的请求之后,将通过SubReactor读取数据,之后的操作与上述单个Reactor模型流程一致的
后面会详细写高性能IO编程模型,会再详细讲Reactor以及对应的实现
