过拟合、欠拟合机器解决方案
1、过拟合、欠拟合的概念
2、权重衰减
3、丢弃法
模型选择、过拟合和欠拟合
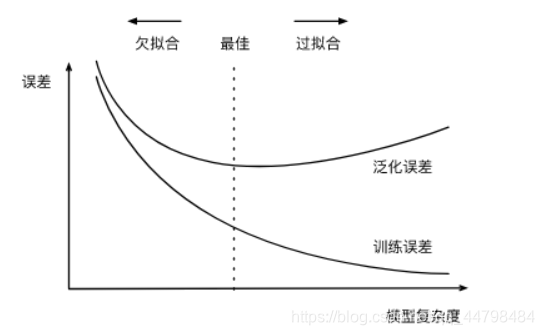
训练误差:训练集上表现得误差
泛化误差:模型在任意一个测试数据样本上表现的误差
过拟合:测试数据集上的误差远大于训练误差,在训练时,模型表现的很好,但在测试时,模型表现的非常不好,学习了很多不必要的特征。通常是模型学习能力太强
欠拟合:训练误差较高。通常是模型学习能力较差,数据复杂度高,导致学习能力不足。
模型选择
验证数据集:
测试集只能在所有超参数和模型参数选定后使用,不可以使用测试数据集选择模型,验证数据集是基于训练集和测试集之外的数据集,
K折交叉验证:将原始数据分为k分
选取第一份中的最后一个作为验证数据
选取第二份中的倒数第二个作为验证数据以此类推
模型复杂度
import torch
import numpy as np
import matplotlib.pyplot as plt
# initialize the model parameter
n_train, n_test, true_w, true_b = 100, 100, [1.2, -3.4, 5.6], 5
features = torch.randn((n_train + n_test, 1))
poly_features = torch.cat((features, torch.pow(features, 2),
torch.pow(features, 3)), 1)
labels = (true_w[0] * poly_features[:, 0] + true_w[1] * poly_features[:, 1] + true_w[2] * poly_features[:, 2] + true_b)
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
# define training and test model
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None,
y2_vals=None, legend=None):
plt.xlabel(x_label)
plt.ylabel(y_label)
# plt.semilogy 对y取对数
plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
plt.semilogy(x2_vals, y2_vals, linestyle=':')
plt.legend(legend)
# define super_paramter
epochs, loss=100, torch.nn.MSELoss()
def fit_and_plot(train_features, test_features, train_labels, test_labels):
# initial net model
net = torch.nn.Linear(train_features.shape[-1], 1)
batch_size = min(10, train_labels.shape[0])
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
train_ls, test_ls = [], []
for _ in range(epochs):
for x, y in train_iter:
l = loss(net(x), y.view(-1, 1))
optimizer.zero_grad()
l.backward()
optimizer.step()
train_labels = train_labels.view(-1, 1)
test_labels = test_labels.view(-1, 1)
train_ls.append(loss(net(train_features), train_labels).item())
test_ls.append(loss(net(test_features), test_labels).item())
print('final epoch: train loss', train_ls[-1], 'test loss', test_ls[-1])
semilogy(range(1, epochs + 1), train_ls, 'epochs', 'loss',
range(1, epochs+1), test_ls, ['train', 'test'])
print('weight:', net.weight.data,
'\nbias:', net.bias.data)
fit_and_plot(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:])
梯度消失
随机初始化模型参数:为了解决只有1个隐藏单元在发挥作用
