文章目录
一、前言
2020-04-08日爬虫练习
每日一个爬虫小练习,学习爬虫的记得关注哦!
学习编程就像学习骑自行车一样,对新手来说最重要的是持之以恒的练习。
在《汲取地下水》这一章节中看见的一句话:“别担心自己的才华或能力不足。持之以恒地练习,才华便会有所增长”,现在想来,真是如此。
二、需求

具体参考我昨日爬虫:【每日爬虫】:给自己打造一个温馨的家,面朝大海,春暖花开
三、技术路线
import requests
import random, os, sys
from bs4 import BeautifulSoup # 数据解析之BeautifulSoup4库
import re,time # 正则表达式
from concurrent.futures import ThreadPoolExecutor # 线程池
关于 线程池 可以参考我免费专栏:python多线程与多进程编程
关于 requests 和 BeautifulSoup模块可以关注我免费专栏:爬虫学习笔记
四、线程池爬取2万张装修效果图
'''
线程池爬土巴兔装修效果图,按分类爬取
version:02
author:金鞍少年
Blog:https://jasn67.blog.csdn.net/
date:2020-04-08
可以按照这个思路将所有涉及到网络请求,添加到异步线程池中,这样速度更快,但是对目标网站不友好,高频请求可能会导致被封IP
'''
import requests
import random, os, sys
from bs4 import BeautifulSoup
import re,time
from concurrent.futures import ThreadPoolExecutor
class House_renderings():
def __init__(self):
self.pool = ThreadPoolExecutor(10) # 开10个线程的线程池
self.is_running = True # 当is_running为True时,说明程序还在运行
# 户型
self.house_lis = '''
------- 请选择户型 ---------
1:一居室
2:两居室
3:三居室
4:四居室及以上
5:复式
6:别墅豪宅
7:其他
8:退出
'''
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Referer': 'https://xiaoguotu.to8to.com/'
}
# 代理ip
self.all_proxies = [
{'http': '183.166.20.179:9999'}, {'http': '125.108.124.168:9000'},
{'http': '182.92.113.148:8118'}, {'http': '163.204.243.51:9999'},
{'http': '175.42.158.45:9999'}] # 需要自行去找一些免费的代理,参考我其他博客案例
self.path = './res/' # 本地存储目录
# 获取HTMl
def get_html(self, url):
try:
result = requests.get(url=url, headers=self.headers, proxies=random.choice(self.all_proxies))
result.raise_for_status() # 主动抛出一个异常
html = BeautifulSoup(result.text, 'lxml')
return html
except:
print('链接失败!')
# 获取分页url
def get_page_urls(self, url, html):
try:
Pages = list(html.find('div', class_="pages").find_all('a'))[-2].string
for page in range(1, int(Pages) + 1):
page_url = url+'p{}'.format(page)
yield page_url
except AttributeError:
yield url
# 获取详情页面url
def get_detail_urls(self, page_html):
try:
page_html = page_html.result()
a_tag = page_html.find('div', class_="xmp_container").find_all('a', class_="item_img")
for a in a_tag:
detail_urls = 'https:' + a['href']
self.pool.submit(self.get_html, detail_urls).add_done_callback(self.Save_detail_page)
except Exception as e:
print(e)
# 获取详情页内容,并保存到本地
def Save_detail_page(self, detail_html):
detail_html = detail_html.result()
try:
house_style = detail_html.find('ul', class_="tag_list xg_tag").find('a').string # 装修风格
house_type = detail_html.find('ul', class_="tag_list xg_tag").find_all('a')[1].string # 户型
atlas_name = detail_html.find('strong', id="fine_n").get_text() # 图集名
atlas_name = re.sub(r"[\/\\\:\*\?\"\<\>\|]", "_", atlas_name) # 转义 Windows文件名中的非法字符方法
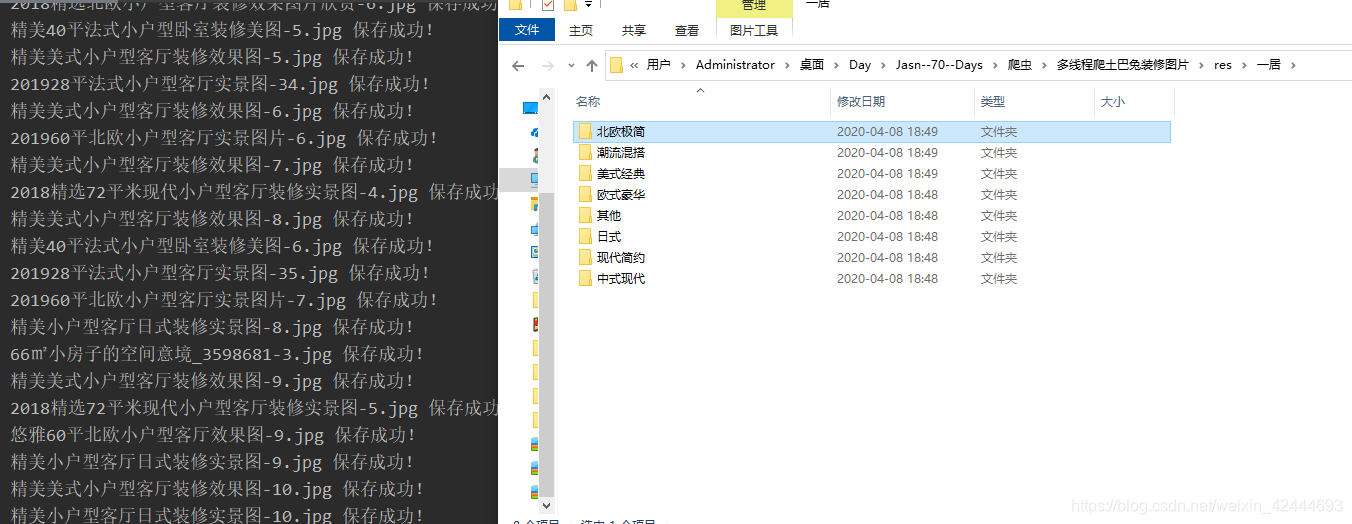
file_path = self.path + house_type + '/' + house_style + '/' + atlas_name + '/' # 拼接文件存储路径
# 递归创建文件夹
if not os.path.exists(file_path):
os.makedirs(file_path)
imgs = detail_html.find('div', class_="display-none").find_all('img')
for index, img in enumerate(imgs):
jpg = requests.get(img['src'], headers=self.headers, proxies=random.choice(self.all_proxies))
with open(file_path + '%s.jpg' % (index + 1), 'wb')as f:
f.write(jpg.content)
print('{}-{}.jpg 保存成功!'.format(atlas_name, index))
self.is_running = False # 告诉主进程任务结束
except Exception as e:
if hasattr(e, 'reason'):
print(f'抓取失败,失败原因:{e.reason}')
# 选择户型
def choice_house(self):
while True:
print(self.house_lis)
choice = input("请选择输入序号选择户型 :").strip()
if choice == "1":
return 'https://xiaoguotu.to8to.com/list-h2s7i0'
elif choice == "2":
return 'https://xiaoguotu.to8to.com/list-h2s2i0'
elif choice == "3":
return 'https://xiaoguotu.to8to.com/list-h2s3i0'
elif choice == "4":
return 'https://xiaoguotu.to8to.com/list-h2s4i0'
elif choice == "5":
return 'https://xiaoguotu.to8to.com/list-h2s5i0'
elif choice == "6":
return 'https://xiaoguotu.to8to.com/list-h2s6i0'
elif choice == "7":
return 'https://xiaoguotu.to8to.com/list-h2s8i0'
elif choice == "8":
print('退出成功!')
sys.exit()
else:
print('输入错误,重新输入!')
# 逻辑功能
def func(self):
house_classify_url = self.choice_house()
html = self.get_html(house_classify_url)
for url in self.get_page_urls(house_classify_url, html):
self.pool.submit(self.get_html, url).add_done_callback(self.get_detail_urls)
# 防止主线程结束,如果主进程结束,线程池也就关闭了
while True:
time.sleep(0.000001) # 避免cpu空转,浪费资源
if not self.is_running:
break
self.pool.shutdown() # 关闭线程池,不再接收新任务,但池内已有任务会继续执行,所有任务执行完后该线程池中的所有线程都会死亡。
if __name__ == '__main__':
# 开启线程池
h = House_renderings()
h.func()


五、其他
1、可以按照这个思路将所有涉及到网络请求,添加到异步线程池中,这样速度更快,但是对目标网站不友好,高频请求可能会导致被封IP,我只将部分网络请求添加到线程池中,有需要的小伙伴可以自己修改。
2、有没有想学python的小伙伴一起组队战拖延症啊,我感觉我的拖延症犯了,总是喜欢把任务拖到下午或者晚上,然后草草的解决。
3、不是广告,也不卖课程,就是单纯的想组队战拖,有愿意一起学习的小伙伴私信或者评论留言,一起加个好友相关监督学习python吧。
