D03_用例中提取数据:regex 正则方式
在 httprunner 中可以通过正则表达式进行文本内容的提取:
- 从响应的实体中进行正则提取
- 响应的实体必须是“JSON”或者“HTML文本”类型
- 格式为: <左边界>(提取内容的正则表达式)<右边界>
- 常用提取的正则: (.*) 代表边界里面可以是“任意字符出现任意次数”

\httprunner-2.5.5\httprunner\response.py:
在源码函数的注释中说明,通过正则方式提取时,可以从响应实体 JSON 或者 HTML 文本中提取

提取规则(类似LR的处理):
- 从实体文本中找到待提取的内容
- 界定其左右边界
- 将待提取内容用正则表达式方式代替并置入括号中
案例
- 目的:从返回响应的 HTML 文本中,将某图片的标签代码提取出来
- 特点:
- 该图片在一对 <td> 标签中,可以分别作为识别的左右边界(要具备唯一性)
- 左侧 <td> 标签中有宽度属性值,正好3个数字
- config:
name: 用例 - 测试进销存系统
- test:
name: 步骤 - 打开登录页面
request:
url: http://localhost/myweb/jxc/index.asp
method: GET
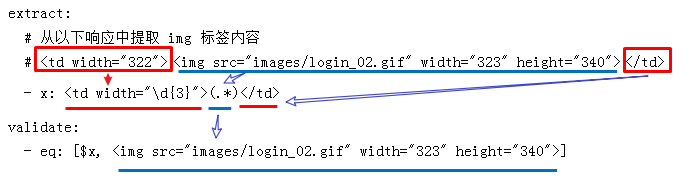
extract:
# 从以下响应 HTML 中提取 img 标签内容
# <td width="322"><img src="images/login_02.gif" width="323" height="340"></td>
- x: <td width="\d{3}">(.*)</td>
validate:
# 验证提取是否正确(判断提取和预期的编码字符串是否相等)。
- eq: [$x, <img src="images/login_02.gif" width="323" height="340">]
以上案例中提取说明:
- 前面(左边界)是:<td width="\d{3}">,其中 \d 代表数字,{3}代表出现3次,即此处需要出现3个数字
- 后面(右边界)是:</td>
- 中间括号中内容即为需要提取的字符串,其中“.”代表任意字符,“*”代表出现任意次数
运行测试用例,查看测试报告中的日志信息,可以看到提取成功。

