Reading Wikipedia to Answer Open-Domain Questions
D. Q. Chen, A. Fisch, J. Weston, A. Bordes, Reading Wikipedia to Answer Open-Domain Questions, ACL (2017)
摘要
开放域问题回答(open domain question answering)
知识来源(knowledge source):维基百科、且唯一(unique)
任意事实性问题(factoid question)的答案:维基百科文章的文本张成(a text span in a Wikipedia article)。
大规模机器阅读(machine reading at scale):(1)文档检索(document retrieval),即相关文章查找(relevant articles);(2)机器阅读理解(machine comprehension of text),即根据文章内容识别答案。
本文从维基百科(Wikipedia)的文章段落中查找问题答案,包含两个模块:(1)基于bigram哈希(bigram hashing)和TF-IDF匹配(matching)的搜索(search)组件;(2)多层递归神经网络(a multi-layer recurrent neural network)。(combines a search component based on bigram hashing and TF-IDF matching with a multi-layer recurrent neural network model trained to detect answers in Wikipedia paragraphs)
1 引言
本文以维基百科作为唯一知识源(unique knowledge source),回答开放域(an open-domain setting)事实性问题(factoid questions)
知识库(knowledge bases,KBs):易处理、但过于稀疏,不适合开放域问题(easier for computers to process but too sparsely populated for open-domain question answering)。
以以维基百科作为知识源的问答(question answering,QA)系统需要解决:(1)大规模开放域问答(large-scale
open-domain QA);(2)机器文本阅读(machine comprehension of text)。前者检索相关文档(retrieve the few relevant articles),后者从相关文档中标识答案(identify the answer)。本文将其称为大规模机器阅读(machine reading at scale,MRS)。

2 相关工作
开放域问答定义:从非结构化文档集合中查找答案(open-domain QA was originally defined as finding answers in collections of unstructured documents)。
知识库的局限性:不完整(incompleteness)、架构固定(fixed schemas)。
机器文本理解(machine comprehension of text):通过阅读短文、故事回答问题(answering questions after reading a short text or story)。
3 DrQA系统
DrQA系统组件:(1)文档检索(Document Retriever),查找相关文章;(2)文档阅读(Document Reader),机器理解(machine comprehension)模型,从单个文档或文档集中抽取答案(extracting answers from a single document or a small collection of documents)。
3.1 文档检索(Document Retriever)
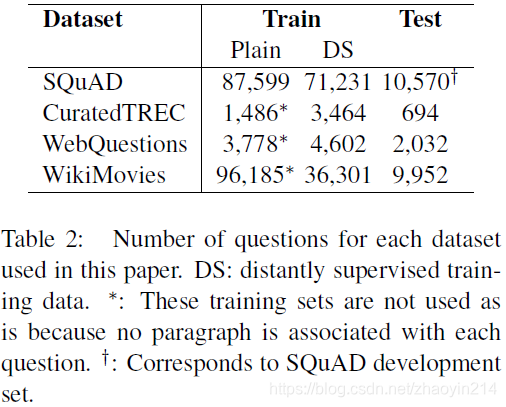
非学习(non-machine learning)类文档检索(document retrieval system):比较文章与问题的二元模型计数(bigram counts);通过无符号murmur3哈希(an unsigned murmur3 hash)将二元模型映射到 个区间上(bins);对每个问题返回5篇维百文章。
3.2 文档阅读(Document Reader)
给定 个词条(token)的问题(question), ;及 个词条的段落(paragraph) ,本文将各个段落依次输入RNN模型,并将预测结果汇总(aggregate the predicted answers)
段落编码(paragraph encoding)
将段落 中的词条 表示为特征向量 的序列(a sequence of feature vectors),并输入递归神经网络(recurrent neural network):
其中, 表示词条 有效上下文信息的编码(expected to encode useful context information around token )。本文采用多层双向LSTM(a multi-layer bidirectional long short-term memory network)网络,并将各层隐含单元最终输出的串联记为 (the concatenation of each layer’s hidden units in the end)。
特征向量(feature vector) 为如下特征的组合:
-
词嵌入(word embeddings): ,本文使用300维Glove词嵌入,并对其中词频最高的1000个疑问词的词嵌入微调,其余保持不变(keep most of the pre-trained word embeddings fixed and only fine-tune the 1000 most frequent question words because the representations of some key words such as what, how, which, many could be crucial for QA systems)。
-
精确匹配(exact match): ,若 与问题 中任意单词的原形(original)、小写形式(lowercase)或词根(lemma)相同,则称 、 完全匹配,用三个二值特征(binary features)表示(use three simple binary features, indicating whether can be exactly matched to one question word in , either in its original, lowercase or lemma form)。
-
词条特征(token features): ,引入少量表示词条 属性(properties)的人工特征(manual features),如词性(part-of-speech,POS)、命名实体识别(named entity recognition tag,NER)标签、归一化词频(normalized term frequency,TF)
-
问题对齐嵌入(aligned question embedding): ,其中注意力评分(attention score) 表示 与 的相似度(the attention score captures the similarity between and each question words )。
其中, 表示激活为ReLU的单层感知器(a single dense layer with ReLU nonlinearity)。
问题编码(question encoding)
将 的词嵌入作为另一个RNN网络的输入,并将隐含单元状态合并成向量(apply another recurrent neural network on top of the word embeddings of and combine the resulting hidden units into one single vector), 。计算 ,其中 对问题中各词的重要性编码(encodes the importance of each question word):
为待学习权值向量(a weight vector to learn)。
预测(prediction)
4 数据(Data)
本文采用3类数据:
-
维基百科(Wikipedia):答案查找知识源(knowledge source for finding answers)
-
SQuAD数据集:训练文档阅读器
-
其它QA数据集(CuratedTREC、WebQuestions、WikiMovies):测试本系统开放域问答性能

5 实验
5.1 相关文档查找(Finding Relevant Articles)
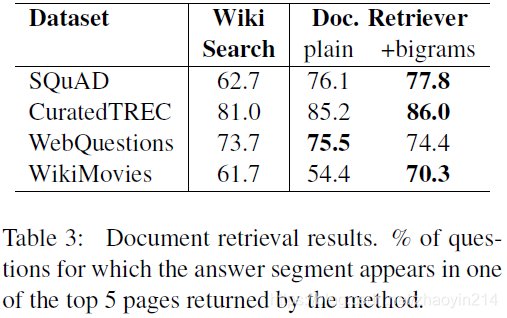
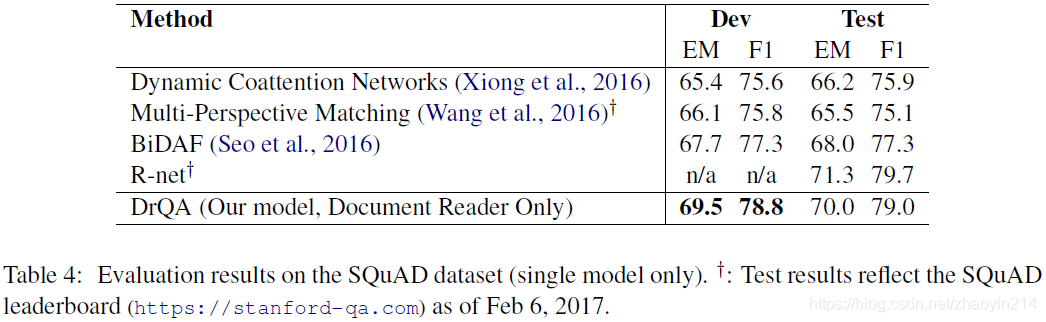
5.2 阅读评估(Reader Evaluation on SQuAD)
5.3 维百问题(Full Wikipedia Question Answering)
特征组合有效性验证(表5)