第4章 集合框架
为什么需要集合框架
我们在存储大量的数据的时候,首先想到的是数组;但是数组存在的问题: ①大小是固定的,受限②类型是固定。但是在项目开发过程中我们存储的数据大部分情况都不是固定的数量。存储公司的ERP的会员数,不是固定的,存储公司的供应商,这些都不是固定的数量。如何存储此类数据,java提供了一整套集合框架。
java提供的集合框架
为了提高编程的效率,java在jdk中提供一个包: java.util.*,该包下提供一系列的接口和实现类。用来存储大量的数据。整体的继承关系图:
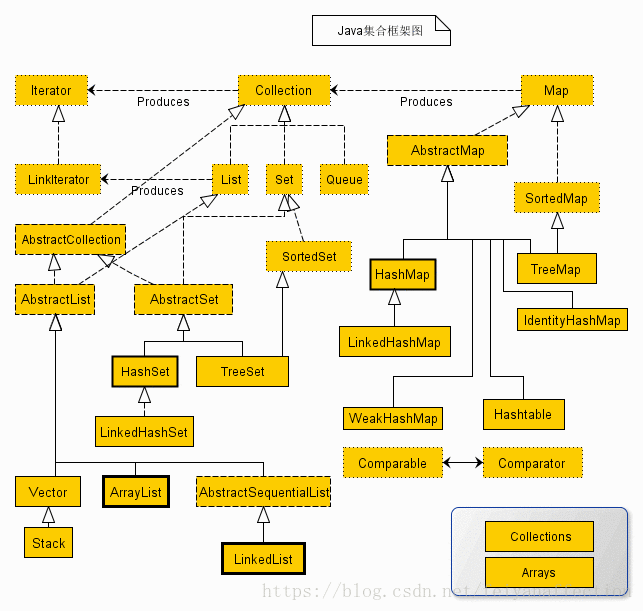
总结如下:
①Map接口产生Collection接口,Map接口可以理解为跟接口
②Map是一套体系,存储的映射关系: key—–value的映射
③Collection接口有两个直接子接口: List和Set
④List系列存储有序可以重复的数据
⑤Set系列存储的无序不允许重复的数据
⑥两个比较器: Comparable和Comparator
⑦两个工具类: Collections和Arrays
常用的集合接口和实现类
List接口
List存储的有序允许重复的数据,线性表; List的常用方法;
public interface List<E> extends Collection<E>
Collection接口常用方法
| Modifier and Type | Method and Description |
|---|---|
boolean |
add(E e) 确保此集合包含指定的元素(可选操作)。 |
boolean |
addAll(Collection c) 将指定集合中的所有元素添加到此集合(可选操作)。 |
void |
clear() 从此集合中删除所有元素(可选操作)。 |
boolean |
contains(Object o) 如果此集合包含指定的元素,则返回 true 。 |
boolean |
containsAll(Collection c) 如果此集合包含指定 集合中的所有元素,则返回true。 |
boolean |
equals(Object o) 将指定的对象与此集合进行比较以获得相等性。 |
int |
hashCode() 返回此集合的哈希码值。 |
boolean |
isEmpty() 如果此集合不包含元素,则返回 true 。 |
Iterator |
iterator() 返回此集合中的元素的迭代器。 |
default Stream |
parallelStream() 返回可能并行的 Stream与此集合作为其来源。 |
boolean |
remove(Object o) 从该集合中删除指定元素的单个实例(如果存在)(可选操作)。 |
boolean |
removeAll(Collection c) 删除指定集合中包含的所有此集合的元素(可选操作)。 |
default boolean |
removeIf(Predicate filter) 删除满足给定谓词的此集合的所有元素。 |
boolean |
retainAll(Collection c) 仅保留此集合中包含在指定集合中的元素(可选操作)。 |
int |
size() 返回此集合中的元素数。 |
default Spliterator |
spliterator() 创建一个Spliterator在这个集合中的元素。 |
default Stream |
stream() 返回以此集合作为源的顺序 Stream 。 |
Object[] |
toArray() 返回一个包含此集合中所有元素的数组。 |
T[] |
toArray(T[] a) 返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型。 |
List子接口常用方法:
| Modifier and Type | Method and Description |
|---|---|
boolean |
add(E e) 将指定的元素追加到此列表的末尾(可选操作)。 |
void |
add(int index, E element) 将指定的元素插入此列表中的指定位置(可选操作)。 |
boolean |
addAll(Collection c) 按指定集合的迭代器(可选操作)返回的顺序将指定集合中的所有元素附加到此列表的末尾。 |
boolean |
addAll(int index, Collection c) 将指定集合中的所有元素插入到此列表中的指定位置(可选操作)。 |
void |
clear() 从此列表中删除所有元素(可选操作)。 |
boolean |
contains(Object o) 如果此列表包含指定的元素,则返回 true 。 |
boolean |
containsAll(Collection c) 如果此列表包含指定 集合的所有元素,则返回true。 |
boolean |
equals(Object o) 将指定的对象与此列表进行比较以获得相等性。 |
E |
get(int index) 返回此列表中指定位置的元素。 |
int |
hashCode() 返回此列表的哈希码值。 |
int |
indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
boolean |
isEmpty() 如果此列表不包含元素,则返回 true 。 |
Iterator |
iterator() 以正确的顺序返回该列表中的元素的迭代器。 |
int |
lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。 |
ListIterator |
listIterator() 返回列表中的列表迭代器(按适当的顺序)。 |
ListIterator |
listIterator(int index) 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。 |
E |
remove(int index) 删除该列表中指定位置的元素(可选操作)。 |
boolean |
remove(Object o) 从列表中删除指定元素的第一个出现(如果存在)(可选操作)。 |
boolean |
removeAll(Collection c) 从此列表中删除包含在指定集合中的所有元素(可选操作)。 |
default void |
replaceAll(UnaryOperator operator) 将该列表的每个元素替换为将该运算符应用于该元素的结果。 |
boolean |
retainAll(Collection c) 仅保留此列表中包含在指定集合中的元素(可选操作)。 |
E |
set(int index, E element) 用指定的元素(可选操作)替换此列表中指定位置的元素。 |
int |
size() 返回此列表中的元素数。 |
default void |
sort(Comparator c) 使用随附的 Comparator排序此列表来比较元素。 |
default Spliterator |
spliterator() 在此列表中的元素上创建一个Spliterator 。 |
List |
subList(int fromIndex, int toIndex) 返回此列表中指定的 fromIndex (含)和 toIndex之间的视图。 |
Object[] |
toArray() 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。 |
T[] |
toArray(T[] a) 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。 |
总结常用方法:
添加方法: add 、 add(int index, E element)、 addAll(Collection c)
删除方法: remove(int index),remove(Object o)、removeAll(Collection c), clear()
修改方法: set(int index, E element), replaceAll(UnaryOperator operator)
查询方法: get、indexOf(Object o)、lastIndexOf(Object o)、 subList(int fromIndex, int toIndex), size()
遍历方法: iterator(), listIterator() , listIterator(int index)
判断方法: isEmpty(), contains(Object o), containsAll(Collection c)
流操作方法: stream(), parallelStream()
排序方法: sort()
转换方法: toArray() 、toArray(T[] a)
ArrayList用法
ArrayList底层是用数组存储的,默认长度10, 数组类型是Object。动态数组,可变数组。
package ch005;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Demo1 {
public static void main(String[] args) {
List list = new ArrayList();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("小昭");
list.add("殷离");
System.out.println("size:"+ list.size());
System.out.println("是否为空:"+ list.isEmpty());
System.out.println("是否包括(小昭):"+list.contains("小昭"));
System.out.println("获取所有的女生:"+list.subList(1, 5));
Object [] objs = list.toArray();
System.out.print("转换对象数组:");
for(Object o: objs) {
System.out.print(o+",");
}
System.out.println("修改元素:"+list.set(1, "灭绝师太"));
System.out.println("修改之后:"+list);
//1.通过for遍历
System.out.print("遍历元素:");
for(int i=0 ;i<list.size(); i++) {
System.out.print(list.get(i)+",");
}
System.out.println("\n使用迭代器遍历:");
Iterator it = list.iterator();
while(it.hasNext()) {
//注意的问题: 遍历的时候不允许添加或删除元素,
//否则会出现并发修改异常ConcurrentModificationException
list.add("xx");
System.out.println(it.next());
}
System.out.println("\n删除元素:"+list.remove(0));
System.out.println("删除元素:"+list.remove("周芷若"));
System.out.println("删除两个元素之后:"+list.size());
}
}
创建ArrayList的说明:
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
elementData是ArrayList存储数据的缓冲区,ArrayList的容量就是数组缓冲区的长度,当第一次添加元素的时候,空的ArrayList会被扩容到长度为10。
LinkedList
底层基于链表存储的, ArrayList是数组,连续的内存空间;而链表不是连续空间。链表的每一个节点不但要存储数据还要存储上下元素的位置。链表相当于小朋友手拉手组成一个队列,左手存储的上一个元素的位置,右手存储下一个元素的位置,小朋友本身是元素存数据。
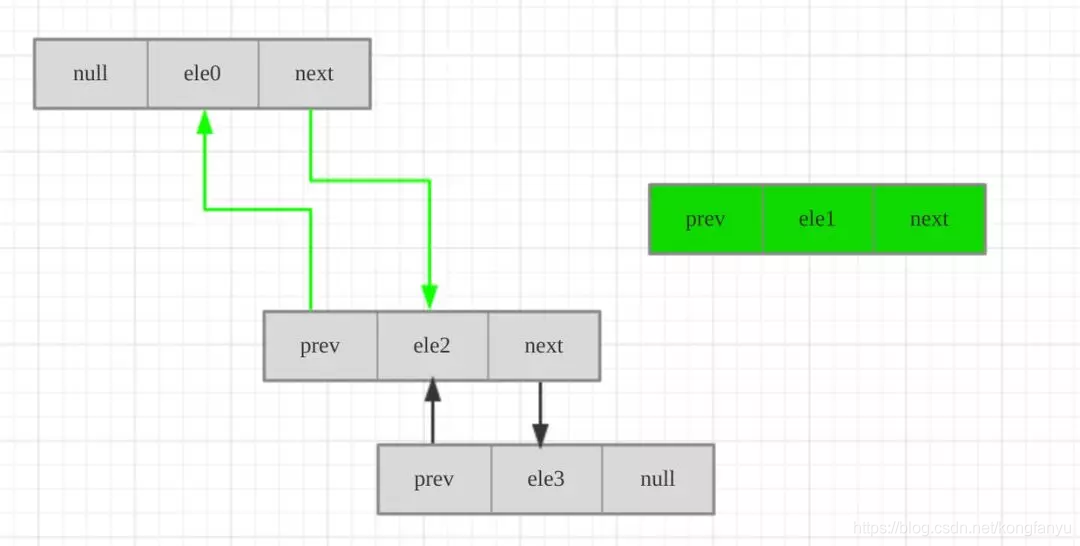
public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable
//双链表实现了List和Deque接口。 实现所有可选列表操作,并允许所有元素(包括null )。
//所有的操作都能像双向列表一样预期。 索引到列表中的操作将从开始或结束遍历列表,以更接近指定的索引为准。
常用方法:
| Modifier and Type | Method and Description |
|---|---|
boolean |
add(E e) 将指定的元素追加到此列表的末尾。 |
void |
add(int index, E element) 在此列表中的指定位置插入指定的元素。 |
boolean |
addAll(Collection c) 按照指定集合的迭代器返回的顺序将指定集合中的所有元素追加到此列表的末尾。 |
boolean |
addAll(int index, Collection c) 将指定集合中的所有元素插入到此列表中,从指定的位置开始。 |
void |
addFirst(E e) 在该列表开头插入指定的元素。 |
void |
addLast(E e) 将指定的元素追加到此列表的末尾。 |
void |
clear() 从列表中删除所有元素。 |
Object |
clone() 返回此 LinkedList的浅版本。 |
boolean |
contains(Object o) 如果此列表包含指定的元素,则返回 true 。 |
Iterator |
descendingIterator() 以相反的顺序返回此deque中的元素的迭代器。 |
E |
element() 检索但不删除此列表的头(第一个元素)。 |
E |
get(int index) 返回此列表中指定位置的元素。 |
E |
getFirst() 返回此列表中的第一个元素。 |
E |
getLast() 返回此列表中的最后一个元素。 |
int |
indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
int |
lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。 |
ListIterator |
listIterator(int index) 从列表中的指定位置开始,返回此列表中元素的列表迭代器(按适当的顺序)。 |
boolean |
offer(E e) 将指定的元素添加为此列表的尾部(最后一个元素)。 |
boolean |
offerFirst(E e) 在此列表的前面插入指定的元素。 |
boolean |
offerLast(E e) 在该列表的末尾插入指定的元素。 |
E |
peek() 检索但不删除此列表的头(第一个元素)。 |
E |
peekFirst() 检索但不删除此列表的第一个元素,如果此列表为空,则返回 null 。 |
E |
peekLast() 检索但不删除此列表的最后一个元素,如果此列表为空,则返回 null 。 |
E |
poll() 检索并删除此列表的头(第一个元素)。 |
E |
pollFirst() 检索并删除此列表的第一个元素,如果此列表为空,则返回 null 。 |
E |
pollLast() 检索并删除此列表的最后一个元素,如果此列表为空,则返回 null 。 |
E |
pop() 从此列表表示的堆栈中弹出一个元素。 |
void |
push(E e) 将元素推送到由此列表表示的堆栈上。 |
E |
remove() 检索并删除此列表的头(第一个元素)。 |
E |
remove(int index) 删除该列表中指定位置的元素。 |
boolean |
remove(Object o) 从列表中删除指定元素的第一个出现(如果存在)。 |
E |
removeFirst() 从此列表中删除并返回第一个元素。 |
boolean |
removeFirstOccurrence(Object o) 删除此列表中指定元素的第一个出现(从头到尾遍历列表时)。 |
E |
removeLast() 从此列表中删除并返回最后一个元素。 |
boolean |
removeLastOccurrence(Object o) 删除此列表中指定元素的最后一次出现(从头到尾遍历列表时)。 |
E |
set(int index, E element) 用指定的元素替换此列表中指定位置的元素。 |
int |
size() 返回此列表中的元素数。 |
Spliterator |
spliterator() 在此列表中的元素上创建*late-binding和故障快速* Spliterator 。 |
Object[] |
toArray() 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。 |
T[] |
toArray(T[] a) 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。 |
案例:
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.add(5);
list.add(6);
list.add(7);
//帖子置顶
list.addFirst(1);
list.addLast(8);
System.out.println(list);
System.out.println("First=="+list.getFirst());
System.out.println("Last==="+list.getLast());
list.removeFirst();
list.removeLast();
System.out.println("删除之后: "+list);
//Deque 队列,火车站买票排队就是一个队列
list.push(10);
list.push(11);
System.out.println("push之后:"+list);
Object first = list.poll();//检索并删除此列表的头(第一个元素) 买票之后走人
System.out.println("poll的元素:"+first);
System.out.println("poll之后:"+list);
}
LinkedList源码分析:
存储数据的对象: 静态内部类,只能在当前类使用
private static class Node<E> {
E item; //数据
Node<E> next;//下一个节点的引用
Node<E> prev;//上一个节点的引用
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
添加元素:
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
连接一个数据作为最后的元素
*/
void linkLast(E e) {
final Node<E> l = last; //获取最后的元素
final Node<E> newNode = new Node<>(l, e, null);//创建节点
last = newNode;//把新节点赋值last
if (l == null)
first = newNode; //把新节点赋值first第一个
else
l.next = newNode;//把最后一个节点的next引用,指向到新节点,组成队列
size++;//整个队列的元素加 1
modCount++;
}
上机练习代码
练习一、练习二、
①实体类:
package ch005;
public class Student {
private int no;
private String name;
private char sex;
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Student [no=" + no + ", name=" + name + ", sex=" + sex + "]";
}
public Student(int no, String name, char sex) {
super();
this.no = no;
this.name = name;
this.sex = sex;
}
public Student() {
super();
}
}
②业务类
package ch005;
import java.util.ArrayList;
import java.util.List;
public class StuMgr {
// 包,存放的钥匙,有钱包,有纸巾,有水笔,化妆品,手机,充电宝
// 包: 纸巾包,只能存储纸巾,取出比较方便
private List<Student> list = new ArrayList<>();
//添加方法
public void addStudent(Student student) {
list.add(student);
}
//查询
public Student findStudent(String name) {
Student stu = null;
for(Student s : list) {
if(s.getName().equals(name)) {
stu = s;//s是找到的对象,赋值给stu
break;
}
}
return stu;
}
//显示所有
public void showAll() {
System.out.println("学号\t姓名\t性别");
for (int i = 0; i < list.size(); i++) {
Student s = list.get(i);
System.out.println(s.getNo() + "\t" + s.getName() + "\t" + s.getSex());
}
}
}
③测试类
public static void main(String[] args) {
System.out.println("---------欢迎使用学生管理系统-------------");
Scanner input = new Scanner(System.in);
StuMgr mgr = new StuMgr();
while (true) {
System.out.println("请选择:1.添加学生 2.查询学生 3.删除学生 4.修改信息 5.退出系统");
int no = input.nextInt();
if (no == 1) {
while (true) {
System.out.print("请输入学生学号:");
int num = input.nextInt();
System.out.print("请输入学生姓名:");
String name = input.next();
System.out.print("请输入学生性别:");
char sex = input.next().charAt(0);
Student s = new Student(num, name, sex);
mgr.addStudent(s);
System.out.print("是否继续?");
String str = input.next();
if (str.equals("n")) {
break;
}
}
mgr.showAll();
} else if (no == 2) {
while(true) {
System.out.print("请输入您要查询的学生姓名:");
String name = input.next();
Student student = mgr.findStudent(name);
if (student != null) {
System.out.println("查询结果:" + student);
}else {
System.out.println(name +"不存在");
}
System.out.print("是否继续?");
String str = input.next();
if (str.equals("n")) {
break;
}
}
} else if (no == 3) {
} else if (no == 4) {
} else {
System.out.println("退出系统..");
break;
}
}
input.close();
}
练习三、
package ch005;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Task3 {
public static void main(String[] args) {
Student[] students = new Student[3];
students[0] = new Student(1001,"张无忌",'男');
students[1] = new Student(1002,"赵敏",'女');
students[2] = new Student(1002,"周芷若",'女');
List<Student> list = new ArrayList<>();
for(int i=0; i<students.length; i++) {
list.add(students[i]);
}
Student s = new Student(1003,"小昭",'女');
list.add(s);
System.out.println("查看List集合:");
Iterator<Student> it = list.iterator();
while(it.hasNext()) {
Student sss = it.next();
System.out.println(sss);
}
}
}
Set接口
set是Collection的子接口,特点是: 无序不允许重复。 List是一队人,可以重复; Set 一堆人不能重复。常用实现类HashSet, TreeSet , LinkedHashSet(按照插入的顺序排列)
HashSet用法
基于Hash算法实现的集合,Hash产生一个唯一的编码,也可以高效的查询数据; 此类实现Set接口,由哈希表(实际为HashMap实例)支持。 对集合的迭代次序不作任何保证; 特别是,它不能保证订单在一段时间内保持不变。 这个类允许null元素。
常用方法:
package ch005;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Demo2 {
public static void main(String[] args) {
Set set = new HashSet();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
set.add(s1);
set.add(s2);
set.add(s3);
System.out.println("size:"+set.size());
System.out.println("是否为空:"+set.isEmpty());
Iterator it = set.iterator();
while(it.hasNext()) {
Student s = (Student) it.next();
System.out.println(s);
}
}
}
如果指定存储类型:
package ch005;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Demo2 {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
set.add(s1);
set.add(s2);
set.add(s3);
System.out.println("size:"+set.size());
System.out.println("是否为空:"+set.isEmpty());
Iterator<Student> it = set.iterator();
while(it.hasNext()) {
Student s = it.next();
System.out.println(s);
}
}
}
HashSet的底层实现:
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{
static final long serialVersionUID = -5024744406713321676L;
//HashSet存储容器
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
* HashSet底层借助HashMap存储的,以key的方式存储,value是一个虚拟对象 PRESENT
*/
public HashSet() {
map = new HashMap<>();
}
//存储数据的实现方式
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
.......
}
TreeSet用法
有序的Set, 按照的自然顺序排列的集合,数值类型的 1,2,3,4; 字符类型的: A,B,C,D; 汉字不会排序。
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("abc");
set.add("bbc");
set.add("abb");
set.add("abd");
System.out.println(set);
Set<Integer> set1 = new TreeSet<>();
set1.add(200);
set1.add(100);
set1.add(500);
set1.add(50);
System.out.println(set1);
Iterator<Integer> it = set1.iterator();
while(it.hasNext()) {
Integer num = it.next();
System.out.println(num);
}
}
如果存储的是自定义类型,会出现什么问题?
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
set.add(s1);
set.add(s2);
set.add(s3);
System.out.println(set.size());
}
出现如下异常:
Exception in thread "main" java.lang.ClassCastException: ch005.Student cannot be cast to java.lang.Comparable
at java.util.TreeMap.compare(Unknown Source)
at java.util.TreeMap.put(Unknown Source)
at java.util.TreeSet.add(Unknown Source)
at ch005.Demo2.main(Demo2.java:15)
类型转换异常: Student对象不能转换成Comparable。为什么出现这个异常? TreeSet是有序的Set,有序是按照什么来进行排序的?
public TreeSet() {
this(new TreeMap<E,Object>());
}
要排序就要进行比较,TreeSet借助于TreeMap实现的,TreeMap的排序方式是两个接口是的
①Comparable 表示可以比较的, Closeable可关闭的,对象具备的特征;同学之间可以比较身高、体重,
②Comparator 比较器: 借助于外部的尺度,进行比较; 对象之间不好比较: 货车座位有序的,借助于车票的序号,电影院容器也是有序的;借助于座位号比较的。
使用Comparable比较器:
package ch005;
public class Student implements Comparable<Student>{
private Integer no;
private String name;
private char sex;
public Integer getNo() {
return no;
}
public void setNo(Integer no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Student [no=" + no + ", name=" + name + ", sex=" + sex + "]";
}
public Student(int no, String name, char sex) {
super();
this.no = no;
this.name = name;
this.sex = sex;
}
public Student() {
super();
}
@Override
public int compareTo(Student o) {
//用当前对象的某个属性和穿过来的参数对象的属性进行比较
//比较的结果 > 0 表示当前对象的值大于参数
//比较的结果 == 0 说明两个对象比较的属性相同
//比较的结果 < 0 当前对象小于参数的数据
int result = this.name.compareTo(o.getName());
if(result == 0) {
//如果名字相同再按照编号比较
return this.getNo().compareTo(o.getNo());
}
System.out.println(name+"和"+o.getName()+"比较的结果:"+result);
return result;
}
}
测试类:
//a=97 b=98 c=99 d=100 e=101 f=102 g=103 h=104 i=105 j=106
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
Student s1 = new Student(1001,"jack",'男');
Student s2 = new Student(1002,"rose",'女');
Student s3 = new Student(1003,"bluce",'女');
Student s4 = new Student(1004,"rose",'女');
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
System.out.println(set.size());
for(Student s: set) {
System.out.println(s);
}
}
使用Comparator外部的比较器:胡润百富榜,也称为杀猪榜,就是一个外部的比较器,土豪之间不好意思比较谁的资产更多。
创建一个实体类,不实现Comparable接口,自身不具备比较性,要借助于第三方的比较器:
package ch005;
public class Dept {
private Integer deptNo;
private String deptName;
public Dept() {
super();
}
public Dept(Integer deptNo, String deptName) {
super();
this.deptNo = deptNo;
this.deptName = deptName;
}
public Integer getDeptNo() {
return deptNo;
}
public void setDeptNo(Integer deptNo) {
this.deptNo = deptNo;
}
public String getDeptName() {
return deptName;
}
public void setDeptName(String deptName) {
this.deptName = deptName;
}
@Override
public String toString() {
return "Dept [deptNo=" + deptNo + ", deptName=" + deptName + "]";
}
}
测试类:
package ch005;
import java.util.Comparator;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
class MyComparator implements Comparator<Dept>{
@Override
public int compare(Dept o1, Dept o2) {
//1.按照名字顺序比较
//return o1.getDeptName().compareTo(o2.getDeptName());
//2.按照名字的长度进行比较
int x = o1.getDeptName().length();
int y = o2.getDeptName().length();
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
}
public class Demo2 {
//a=97 b=98 c=99 d=100 e=101 f=102 g=103 h=104 i=105 j=106
public static void main(String[] args) {
Set<Dept> set = new TreeSet<>( new MyComparator() );
set.add(new Dept(1001,"sell"));
set.add(new Dept(1002,"service"));
set.add(new Dept(1003,"abc"));
for (Dept dept : set) {
System.out.println(dept);
}
}
}
自定义的比较器核心代码只有一行: return o1.getDeptName().compareTo(o2.getDeptName()); 但是java语言是比较规范的语言,所以我们需要完整的定义一个类。就相当于自己吃饭我们要先种菜、收菜、自己加工等一整套流程。但是核心的业务是吃饭而已;如何优化整个流程: 点外卖。简化了所有的流程,只关注核心业务。在jdk1.8中提供了Lambda表达式来简化编码。
简化写法: 使用Lambda表达式,
public static void main(String[] args) {
Set<Dept> set =
new TreeSet<>( (o1,o2) -> o1.getDeptName().compareTo(o2.getDeptName()) );
set.add(new Dept(1001,"sell"));
set.add(new Dept(1002,"service"));
set.add(new Dept(1003,"abc"));
for (Dept dept : set) {
System.out.println(dept);
}
}
只关注核心的一句话: 比较部门名称,简化了创建类的格式.
Map接口
map存储的是键值对,key —value的映射关系; 所以称为双列集合,List就是单列集合; map的key不允许重复,value可以重复。Map接口的常见实现类: HashMap, TreeMap、 LinkedHashMap。需要注意的是都不是线程安全对象,线程安全的Map是Hashtable。在juc包中还有线程安全的实现类: ConcurrentHashMap.
HashMap用法
构造方法:
| Constructor and Description |
|---|
HashMap() 构造一个空的 HashMap ,默认初始容量(16)和默认负载系数(0.75)。 |
HashMap(int initialCapacity) 构造一个空的 HashMap具有指定的初始容量和默认负载因子(0.75)。 |
HashMap(int initialCapacity, float loadFactor) 构造一个空的 HashMap具有指定的初始容量和负载因子。 |
HashMap(Map m) 构造一个新的 HashMap与指定的相同的映射 Map 。 |
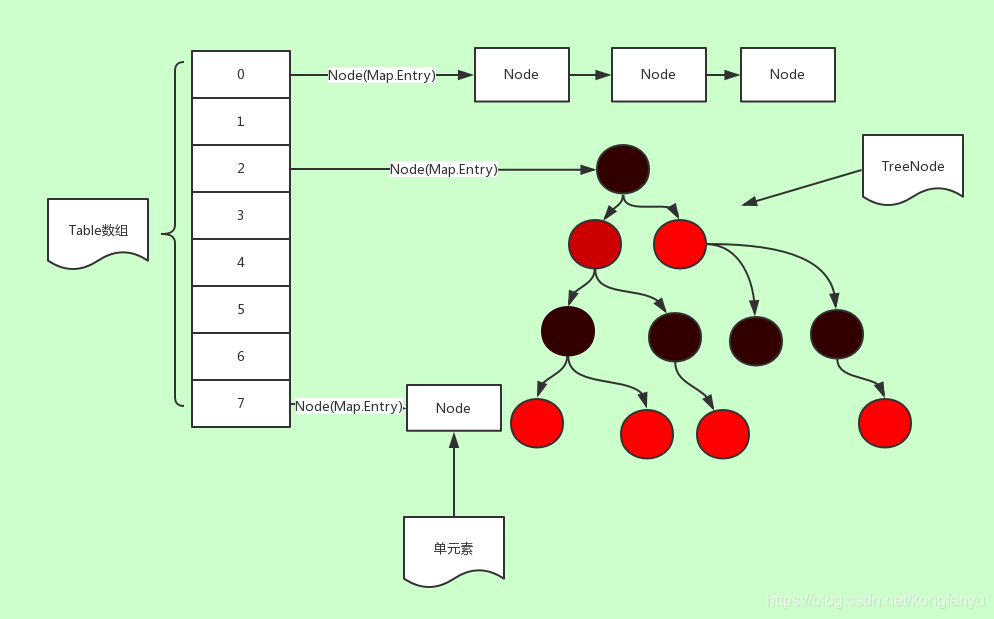
底层用的也是数组,数组的长度是16,负载因子0.75; 当容量达到75%的时候,容器要扩容。16*75%=12,意思是元素到达12的时候触发容器扩容机制。
案例:
public static void main(String[] args) {
Map<String,Student> map = new HashMap<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
//映射关系: 鹿晗-->关晓彤 黄晓明---杨颖 邓超-->孙俪 刘强东---章泽天
map.put("a", s1);
map.put("b", s2);
map.put("c", s3);
System.out.println("size:"+map.size());
System.out.println("是否包括(赵敏):"+map.containsKey("b"));
System.out.println("是否包括对象:"+map.containsValue(s2));
Student s = map.get("c");
System.out.println("根据key获取对象:"+s);
//map的遍历: 1.根据key获取value,先获取所有的key,然后再根据key获取value
Set<String> keys = map.keySet();
Iterator<String> it = keys.iterator();
while(it.hasNext()) {
String key = it.next();
Student stn = map.get(key);
System.out.println(key+"-->"+stn.getName());
}
}
LinkedList用的静态内部类Node存储的,一个Node包括三部分; 类似Map一个元素包括两部分: key-value, 如何管理方便: 可以借鉴LinkedList的存储 机制,也创建一个类存储key和value。这个类叫Entry: 取“条目”的意思。查看HashMap的源码:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
.......
HashMap使用Node节点封装key和value; 键值对,注意一个细节问题: next,表示下一个节点的引用;从中可以猜测HashMap中应该有一个单向链表结构。案例:
public static void main(String[] args) {
Map<String,Student> map = new HashMap<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
map.put("a", s1);
map.put("b", s2);
map.put("c", s3);
Set<Entry<String, Student>> entrySet = map.entrySet();
for (Entry<String, Student> entry : entrySet) {
String key = entry.getKey();
Student value = entry.getValue();
System.out.println(key+"---"+value);
}
}
TreeMap
有序的Map,自定义排序参考TreeSet实现。
public static void main(String[] args) {
Map<String,Student> map = new TreeMap<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
map.put("xxx", s1);
map.put("b34b", s2);
map.put("a12", s3);
Set<Entry<String, Student>> entrySet = map.entrySet();
for (Entry<String, Student> entry : entrySet) {
String key = entry.getKey();
Student value = entry.getValue();
System.out.println(key+"---"+value);
}
}
LinkedHashMap
按照添加的顺序存储元素,基于链表, 先放的元素作为前端节点;后续元素依次连接到前面元素。
public static void main(String[] args) {
Map<String,Student> map = new LinkedHashMap<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1002,"周芷若",'女');
map.put("a12", s3);
map.put("b34b", s2);
map.put("xxx", s1);
Set<Entry<String, Student>> entrySet = map.entrySet();
for (Entry<String, Student> entry : entrySet) {
String key = entry.getKey();
Student value = entry.getValue();
System.out.println(key+"---"+value);
}
}
jdk1.8对集合的增强
jdk 1.8对于集合各种操作简化处理的学习
- 集合转为stream
- 面向流的filter(有返回值true,false),排序sorted,map[mapToInt……,无返回值,把当前值映射成为另一个对象],distinct,distinctbyKey[重写filter参数类型的方法 Predicate distinctByKey(Function<? super T, Object> keyExtractor)]
- 处理后的stream转为集合collect collectors.toList() Collectors.toSet(),Collectors.toMap(Person::getName,Function.identity()) Collectors.groupingBy((f)->……/Person::getName)
- 处理后的流取第一个值findFirst optional类型 ispresent判断
- 多个流的连接stream.of
- 操作集合的降维(降一维)flatMap(Function.identity)
stream用法
流的意思,可以向操作文件流一样操作集合中的数据集; 也可以理解把集合中的数据当做数据库。
Stream操作的三个步骤
- 创建stream
- 中间操作(过滤、map)
- 终止操作
首先创建备用的List集合:
List<String> stringList = new ArrayList<>();
stringList.add("ddd2");
stringList.add("aaa2");
stringList.add("bbb1");
stringList.add("aaa1");
stringList.add("bbb3");
stringList.add("ccc");
stringList.add("bbb2");
stringList.add("ddd1");
Filter(过滤)
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1003,"周芷若",'女');
list.add(s1);
list.add(s2);
list.add(s3);
/*
* list.stream().filter(s -> s.getNo() == 1002) .forEach(System.out::println);
*/
List<Student> list2 = list.stream() //1.获取stream
.filter(s -> s.getNo() >= 1002)//2.过滤
.collect(Collectors.toList());//3.转换成List
for (Student student : list2) {
System.out.println(student);
}
}
查找姓名长度为2的元素
public static void main(String[] args) {
//查找姓名长度为2的元素
List<Student> list = new ArrayList<>();
Student s1 = new Student(1001,"张无忌",'男');
Student s2 = new Student(1002,"赵敏",'女');
Student s3 = new Student(1003,"周芷若",'女');
list.add(s1);
list.add(s2);
list.add(s3);
/*
for (Student student : list) {
if(student.getName().length() == 2) {
System.out.println(student);
}
}
*/
Stream<Student> filter = list.stream().filter(s -> s.getName().length() ==2);
List<Student> list2 = filter.collect(Collectors.toList());
for(Student s: list2) {
System.out.println(s);
}
}
Sorted(排序)
排序是一个 中间操作,返回的是排序好后的 Stream。如果你不指定一个自定义的 Comparator 则会使用默认排序。
// 测试 Sort (排序)
stringList
.stream()
.sorted()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);// aaa1 aaa2
需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:
System.out.println(stringList);// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
Map(映射)
中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
下面的示例展示了将字符串转换为大写字符串。你也可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
// 测试 Map 操作
stringList.stream().map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
Match(匹配)
Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是 最终操作 ,并返回一个 boolean 类型的值。
// 测试 Match (匹配)操作
boolean anyStartsWithA = stringList.stream().anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA = stringList.stream().allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ = stringList.stream().noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true
Count(计数)
计数是一个 最终操作,返回Stream中元素的个数,返回值类型是 long。
//测试 Count (计数)操作
long startsWithB = stringList.stream().filter((s) -> s.startsWith("b")).count();
System.out.println(startsWithB); // 3
Reduce(规约)
这是一个 最终操作 ,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规约后的结果是通过Optional 接口表示的:
//测试 Reduce (规约)操作
Optional<String> reduced = stringList.stream().sorted()
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于Integer sum = integers.reduce(0, (a, b) -> a+b);也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat);
上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别。更多内容查看: IBM:Java 8 中的 Streams API 详解
Parallel Streams(并行流)
前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
下面的例子展示了是如何通过并行Stream来提升性能:
首先我们创建一个没有重复元素的大表:
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}
我们分别用串行和并行两种方式对其进行排序,最后看看所用时间的对比。
Sequential Sort(串行排序)
//串行排序
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
输出结果:
1000000
sequential sort took: 709 ms//串行排序所用的时间
Parallel Sort(并行排序)
//并行排序
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
输出结果:
1000000
parallel sort took: 475 ms//串行排序所用的时间
上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 stream() 改为parallelStream()。
ream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
下面的例子展示了是如何通过并行Stream来提升性能:
首先我们创建一个没有重复元素的大表:
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}
我们分别用串行和并行两种方式对其进行排序,最后看看所用时间的对比。
Sequential Sort(串行排序)
//串行排序
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
输出结果:
1000000
sequential sort took: 709 ms//串行排序所用的时间
Parallel Sort(并行排序)
//并行排序
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
输出结果:
1000000
parallel sort took: 475 ms//串行排序所用的时间
上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 stream() 改为parallelStream()。
