绪论
在使用Tensorflow训练深层的神经网络的时候,我们希望去跟踪神经网络的整个训练过程中的信息,比如迭代的过程中每一层参数是如何变化与分布的、每次循环参数更新后模型在测试集与训练集上的准确率是如何的、损失值的变化情况,等等。在训练的过程中将一些信息加以记录并可视化得表现出来,对我们探索模型有更深的帮助与理解呢。
Tensorflow官方推出了可视化工具Tensorboard,可以帮助我们实现以上功能,它将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。
目录
1. Tensorboard介绍
1.1 Tensorboard的数据形式
Tensorboard可以记录与展示以下数据形式:
(1)标量Scalars
(2)图片Images
(3)音频Audio
(4)计算图Graph
(5)数据分布Distribution
(6)直方图Histograms
(7)嵌入向量Embeddings
1.2 Tensorboard的可视化过程
(1)首先肯定是先建立一个graph,你想从这个graph中获取某些数据的信息
(2)确定要在graph中的哪些节点放置summary operations以记录信息
- 使用tf.summary.scalar记录标量
- 使用tf.summary.histogram记录数据的直方图
- 使用tf.summary.distribution记录数据的分布图
- 使用tf.summary.image记录图像数据
….
(3)operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summary节点。但是呢,一份程序下来可能有超多这样的summary 节点,要手动一个一个去启动自然是及其繁琐的,因此我们可以使用tf.summary.merge_all去将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data。
(4)使用tf.summary.FileWriter将运行后输出的数据都保存到本地磁盘中
(5)运行整个程序,并在命令行输入运行tensorboard的指令,之后打开web端可查看可视化的结果
2. Tensorboard使用案例
我们接下来将利用我们前面所建立好的手写体识别模型进行Tensorboard可视化,从而来了解Tensorboard如何使用。
2.1 数据准备
(1)导入库和mnist数据集
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
(2)定义固定的超参数,方便待使用时直接传入。如果你问,这个超参数为啥要这样设定,如何选择最优的超参数?这个问题此处先不讨论,超参数的选择在机器学习建模中最常用的方法就是“交叉验证法”。而现在假设我们已经获得了最优的超参数,设置学利率为0.01,dropout的保留节点比例为0.6,最大循环次数为20.
另外,还要设置两个路径,第一个是数据下载下来存放的地方,一个是summary输出保存的地方。
MODEL_SAVE_PATH="model"#模型保存路径
MODEL_NAME="mnist_model" #模型保存文件名
logdir='./graphs/mnist' # 输出日志保存的路径
dropout=0.6
learning_rate=0.001
step=20
# 每个批次的大小
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
(3)定义了一个variable_summaries()函数,传递参数为var。
这个函数的作用是收录每次迭代后参数的变化:
① 将传递过来的参数var进行求均值(mean)、标准差(stddev)、最大最小值(max、min)
② 用tf.summary.scalar()函数,分别对上述的几个统计量(标量)进行记录,同时记录参数var的直方图(tf.summary.histogram()函数实现)
同时这里调用了tf.name_scope()函数,并建立了一个名叫summaries的可视化节点的层级,之后在Tensorboard中将会找到它。
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var) ##直方图
2.2 定义placeholder
同样,用tf.name_scope()函数,建立了一个名叫input的可视化节点的层级,这个节点层下包含 x_input、y_input、keep_prob、learning_rate 三个子节点。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32, [None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
lr = tf.Variable(learning_rate, dtype=tf.float32, name='learning_rate')
2.3 使用tf.summary.image保存图像信息
特征数据其实就是图像的像素数据拉升成一个1*784的向量,现在如果想在tensorboard上还原出输入的特征数据对应的图片,就需要将拉升的向量转变成28 * 28 * 1的原始像素了,于是可以用tf.reshape()直接重新调整特征数据的维度:
将输入的数据转换成[28 * 28 * 1]的shape,存储成另一个tensor,命名为image_shaped_input。
为了能使图片在tensorbord上展示出来,使用tf.summary.image将图片数据汇总给tensorbord。
tf.summary.image()中传入的第一个参数是命名,第二个是图片数据,第三个是最多展示的张数,此处为10张。
with tf.name_scope('input_image'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
2.4 初始化参数/权重,定义前传网络
对每个变量都做同样的操作,只不过这里命名了3个层级的节点:‘Input_layer’、‘Hidden_layer’、‘Output_layer’,同时对权重值W1、W2、W3,偏置值b1、b2、b3进行variable_summaries()函数的调用,从而具体了解这些参数在模型训练中是如何发生变化
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name='W1')
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries(b1)
with tf.name_scope('L1'):
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
L1_drop = tf.nn.dropout(L1, keep_prob)
with tf.name_scope('Hidden_layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1), name='W2')
variable_summaries(W2)
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
variable_summaries(b2)
with tf.name_scope('L2'):
L2 = tf.nn.tanh(tf.matmul(L1_drop, W2) + b2, name='L2')
L2_drop = tf.nn.dropout(L2, keep_prob)
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
variable_summaries(W3)
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
variable_summaries(b3)
2.5 计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2, W3) + b3)
2.6 创建损失函数
使用tf.nn.softmax_cross_entropy_with_logits来计算softmax并计算交叉熵损失,并且求均值作为最终的损失值。
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar('loss', loss )
2.7 训练,并计算准确率
(1)使用AdamOptimizer优化器训练模型,最小化交叉熵损失
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
(2)计算准确率,并用tf.summary.scalar记录准确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分别将预测和真实的标签中取出最大值的索引,若相同则返回1(true),不同则返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope('accuracy'):
# 求均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
2.8 合并summary operation, 运行初始化变量
将所有的summaries合并,并且将它们写到之前定义的log_dir路径
# summaries合并
merged = tf.summary.merge_all()
# 写到指定的磁盘路径中
train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(log_dir + '/test')
2.9 指定迭代次数,并在session执行graph
每隔2步,就进行一次merge, 并打印一次测试数据集的准确率,然后将训练和测试数据集的各种summary信息写进日志中。
每隔100步,记录原信息
其他每一步时都记录下训练集的summary信息并写到日志中。
saver=tf.train.Saver() #实例化saver对象
with tf.Session() as sess:
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data
merged = tf.summary.merge_all()
# 写到指定的磁盘路径中
train_writer = tf.summary.FileWriter(logdir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(logdir + '/test', sess.graph)
# 断点续训,如果ckpt存在,将ckpt加载到会话中,以防止突然关机所造成的训练白跑
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
for i in range(step):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
opt=sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,keep_prob: dropout})
train_sum, acc_train = sess.run([merged, accuracy],feed_dict={x: mnist.train.images, y: mnist.train.labels, keep_prob: 1.0})
train_writer.add_summary(train_sum, i)
# 记录训练集的summary
test_sum, acc_test = sess.run([merged, accuracy],feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0})
test_writer.add_summary(test_sum, i)
if i %2==0:
print("Iter" + str(i) + ", Testing accuracy:" + str(acc_test) + ", Training accuracy:" + str(acc_train))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME),global_step=i) # 保存模型
train_writer.close()
test_writer.close()
2.10 执行程序,tensorboard生成可视化
(1)运行整个程序,在程序中定义的summary node就会将要记录的信息全部保存在指定的logdir路径中了,训练的记录会存一份文件,测试的记录会存一份文件。
(2)进入命令行,这里可直接点击pycharm中的Terminal,运行以下代码,等号后面加上summary日志保存的绝对路径。
三种启动方式
#tensorboard --logdir=C:\Users\dbsdz\Desktop\TensorBoardTest\log 可以
#cd E://TensorBoardTest tensorboard --logdir=log 可以
#e: cd TensorBoardTest tensorboard --logdir=log 可以
(注意路径不用带引号,文件名不能有中文、不能有空格,否则会出错)
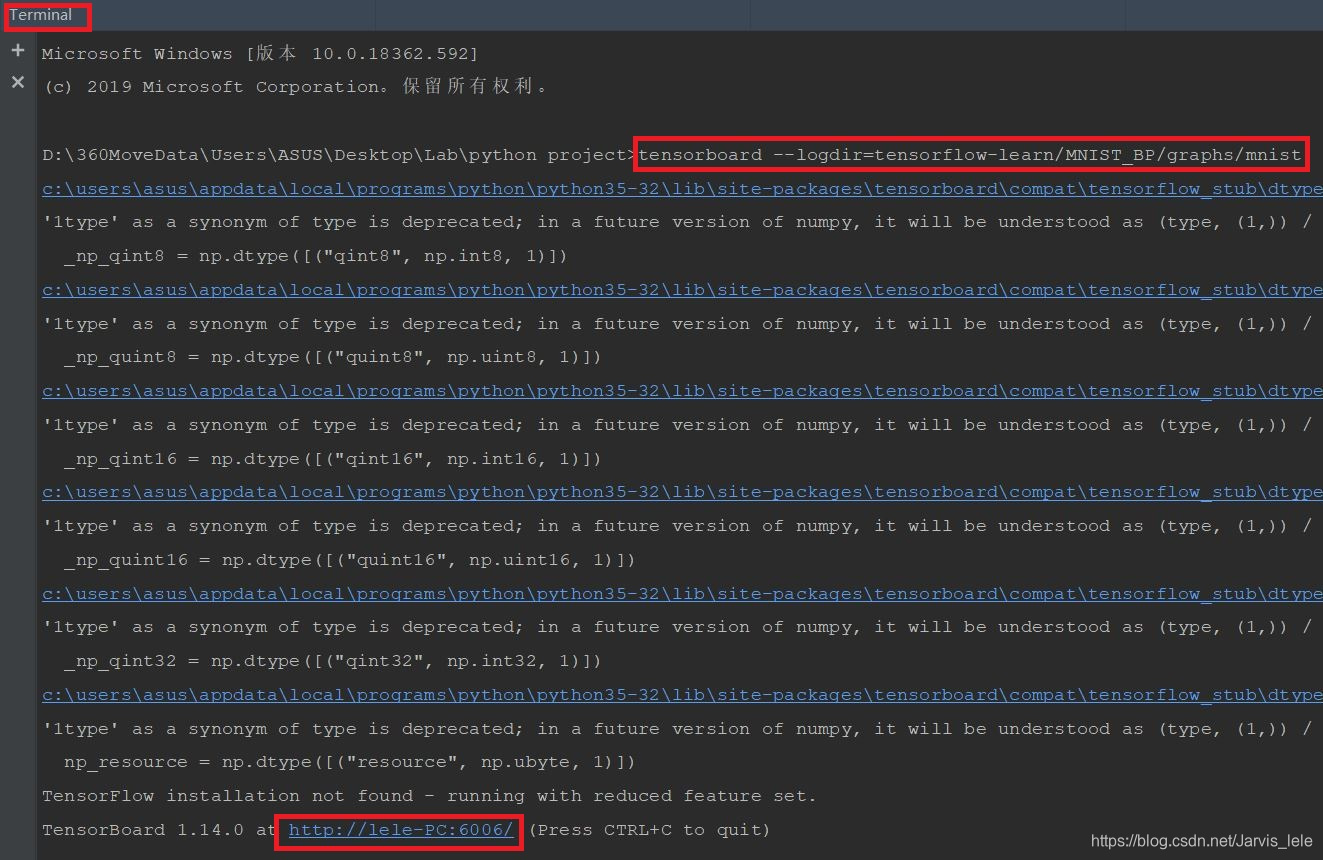
tensorboard --logdir=logdir path
(3)执行命令之后会出现一条信息,上面有网址,将网址在浏览器中打开就可以看到我们定义的可视化信息了,成功的话如下:
3. Tensorboard Web端解释
最上面橙色一栏的菜单,最多可以展示7个栏目,都一一对应着我们程序中定义信息的类型。
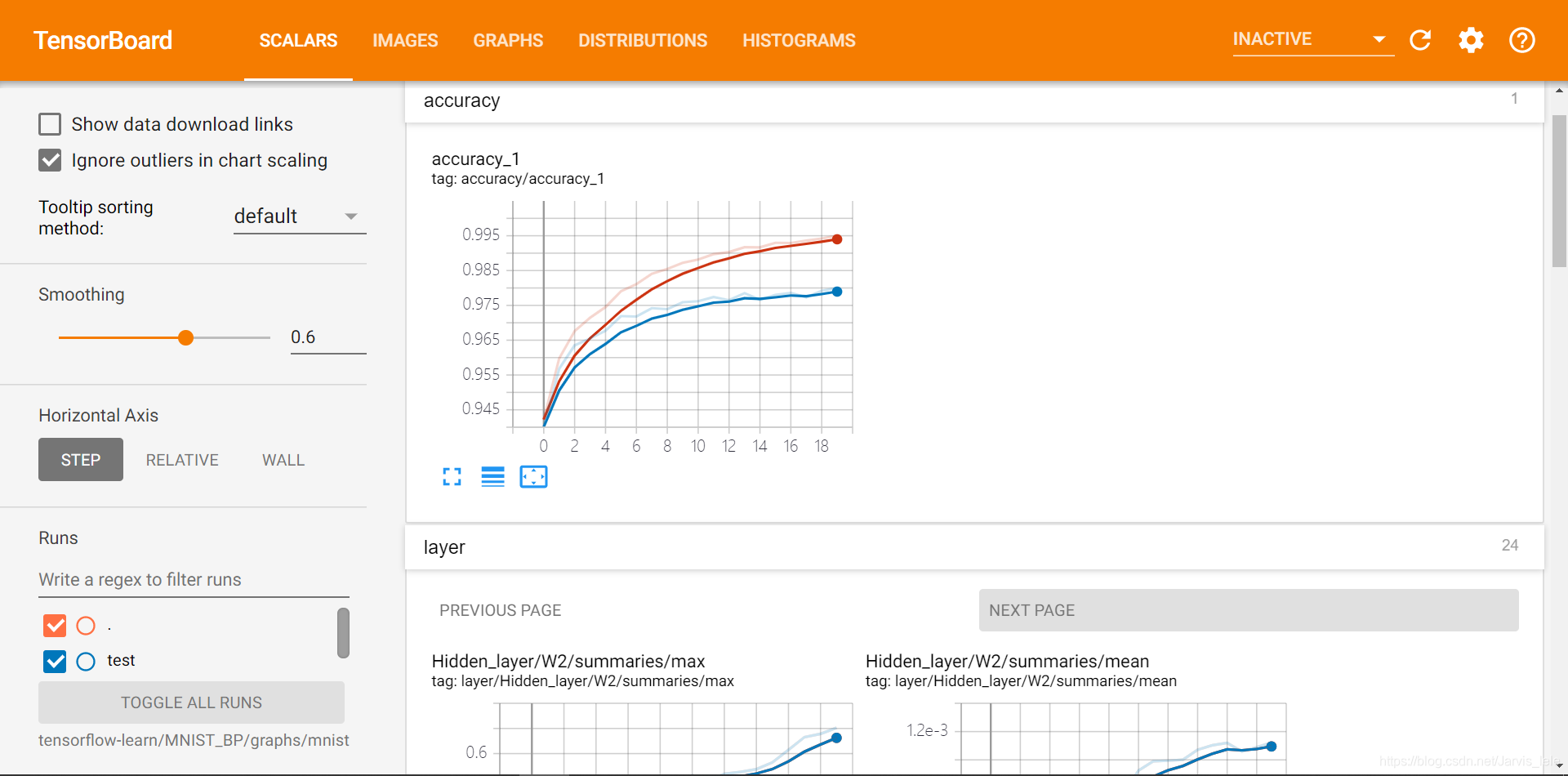
(1)SCALARS
展示的是标量的信息,我程序中用tf.summary.scalars()定义的信息都会在这个窗口。
回顾本文程序中定义的标量有:准确率accuracy,dropout的保留率,隐藏层中的参数信息,已经交叉熵损失。这些都在SCLARS窗口下显示出来了。
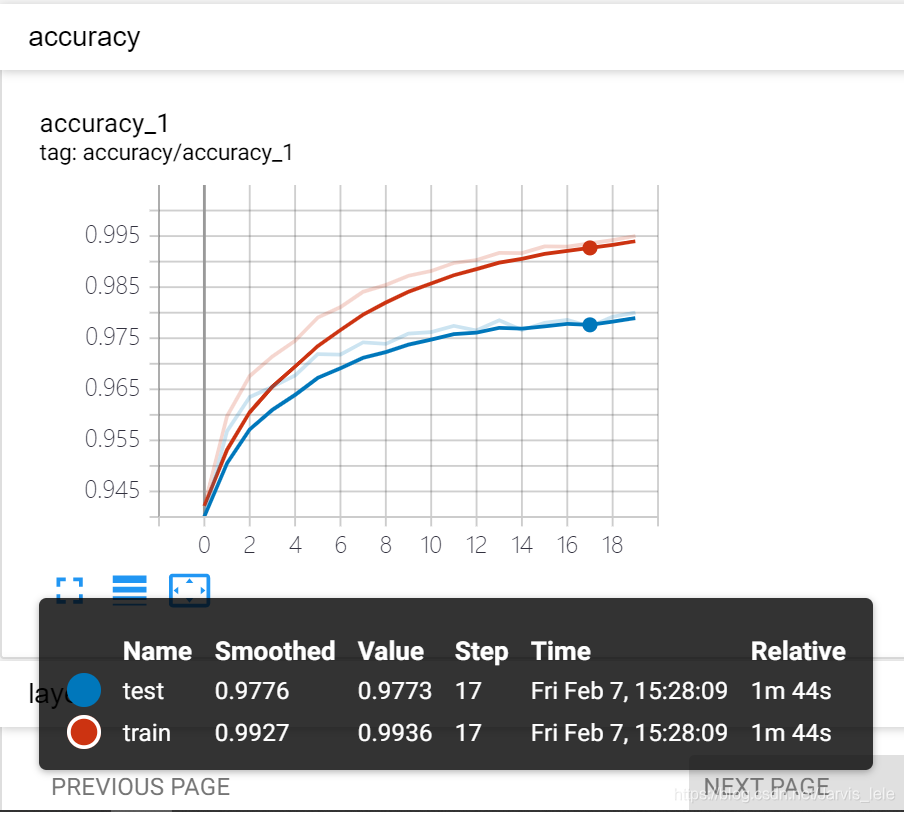
① 点开accuracy,红线表示train集的结果,蓝线表示test集的结果,可以看到随着循环次数的增加,两者的准确度也在通趋势增加,值得注意的是,在0到120次的循环中准确率快速激增,100次之后保持微弱地上升趋势,直达1000次时会到达0.967左右
② 点开layer,查看隐藏层的参数信息。
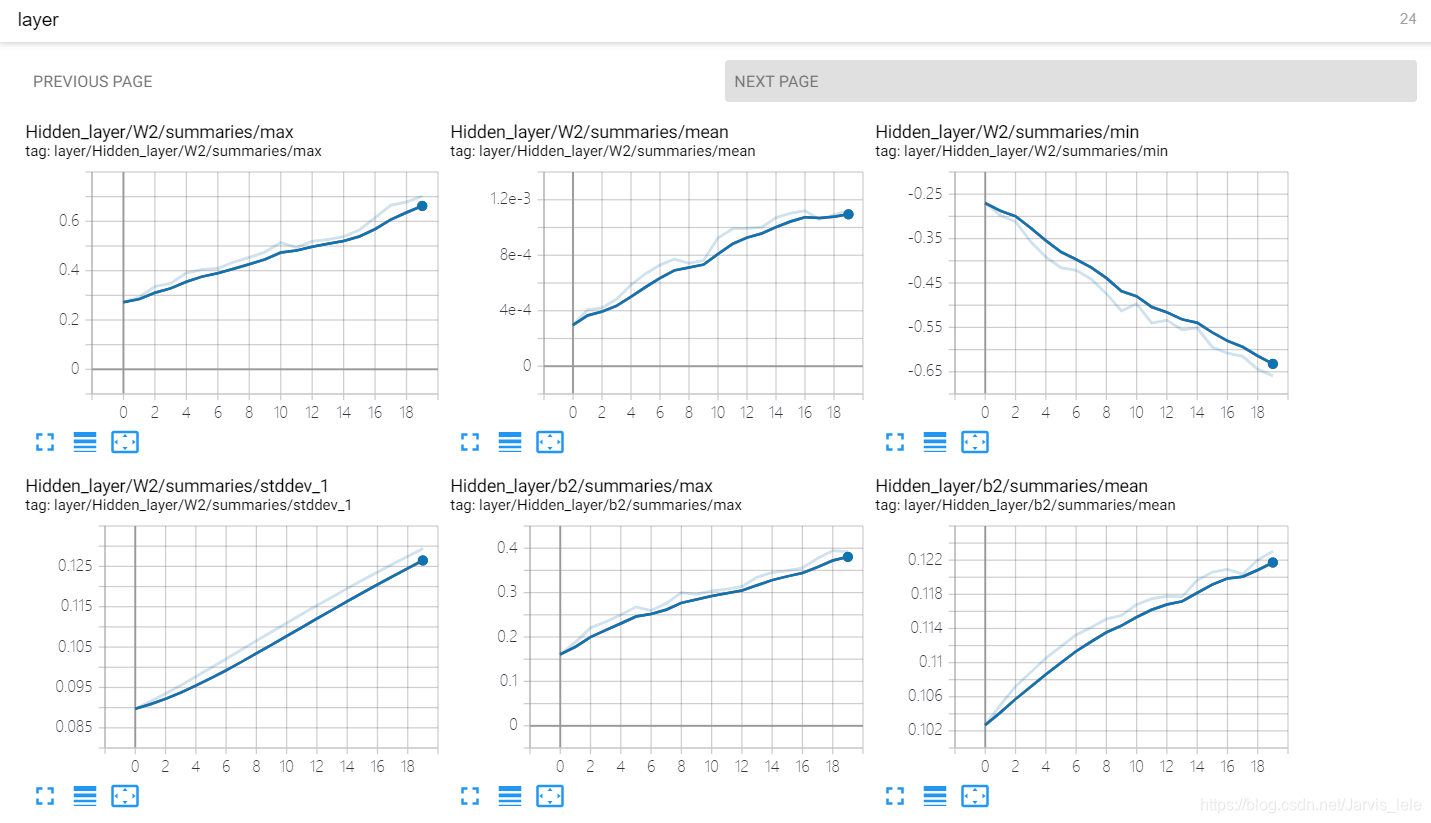
以上,第一排是权值w的信息,随着迭代的加深,最大值越来越大,最小值越来越小,与此同时,也伴随着方差越来越大,这样的情况是我们愿意看到的,神经元之间的参数差异越来越大。因为理想的情况下每个神经元都应该去关注不同的特征,所以他们的参数也应有所不同。
第二排是偏执项b的信息,同理,最大值,最小值,标准差也都有与b相同的趋势,神经元之间的差异越来越明显。
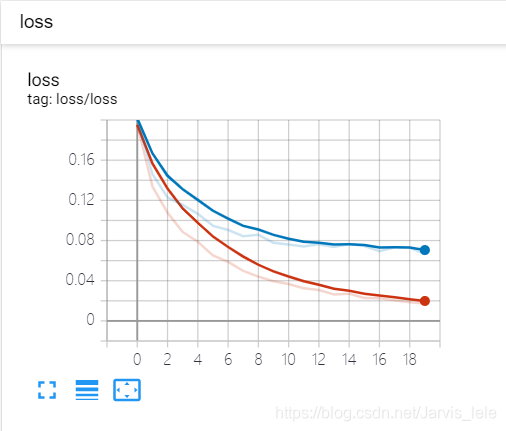
③ 点开loss,可见损失的降低趋势。
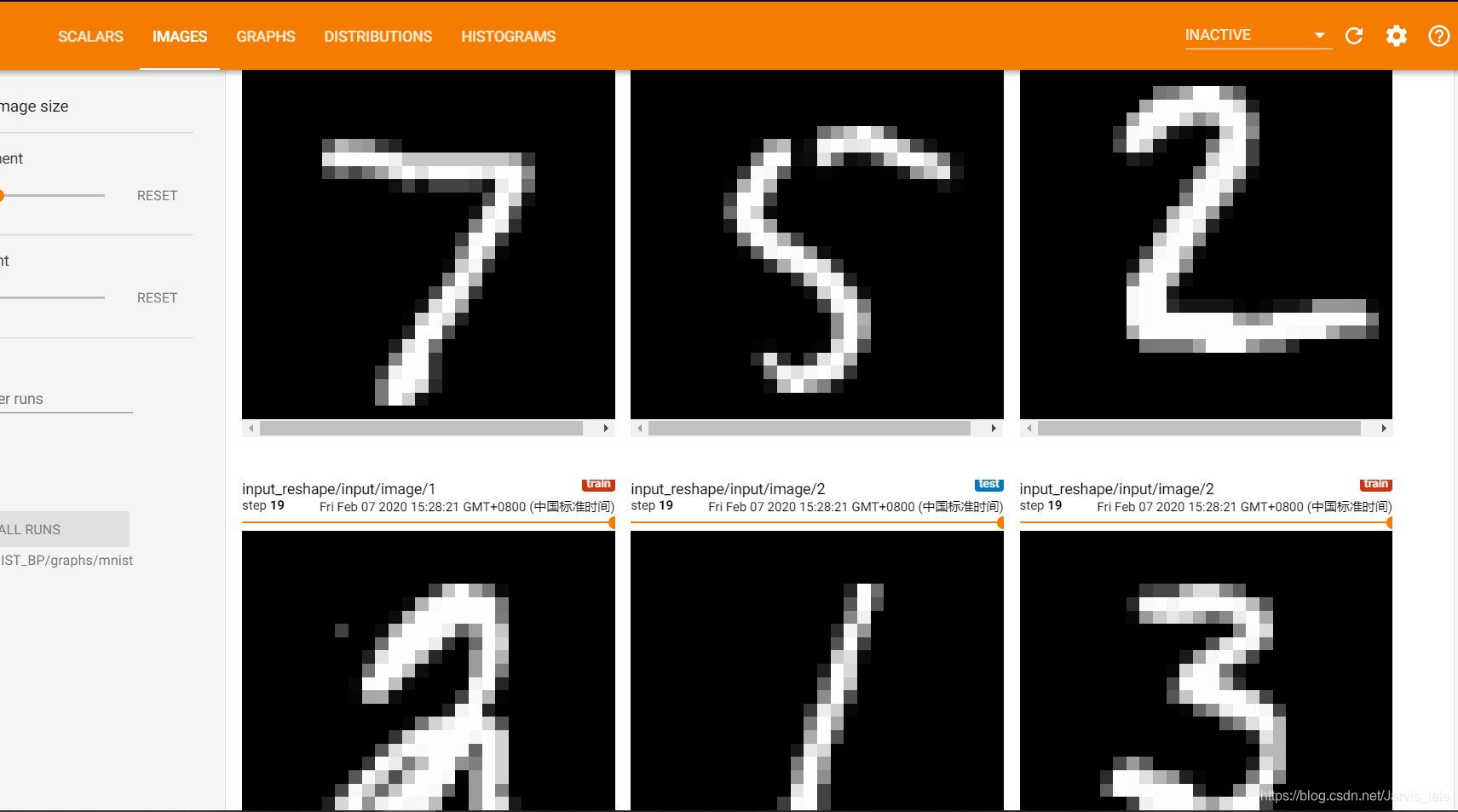
(2)IMAGES
在程序中我们设置了一处保存了图像信息,就是在转变了输入特征的shape,然后记录到了image中,于是在tensorflow中就会还原出原始的图片了:
(3)AUDIO
这里展示的是声音的信息,但本案例中没有涉及到声音的。
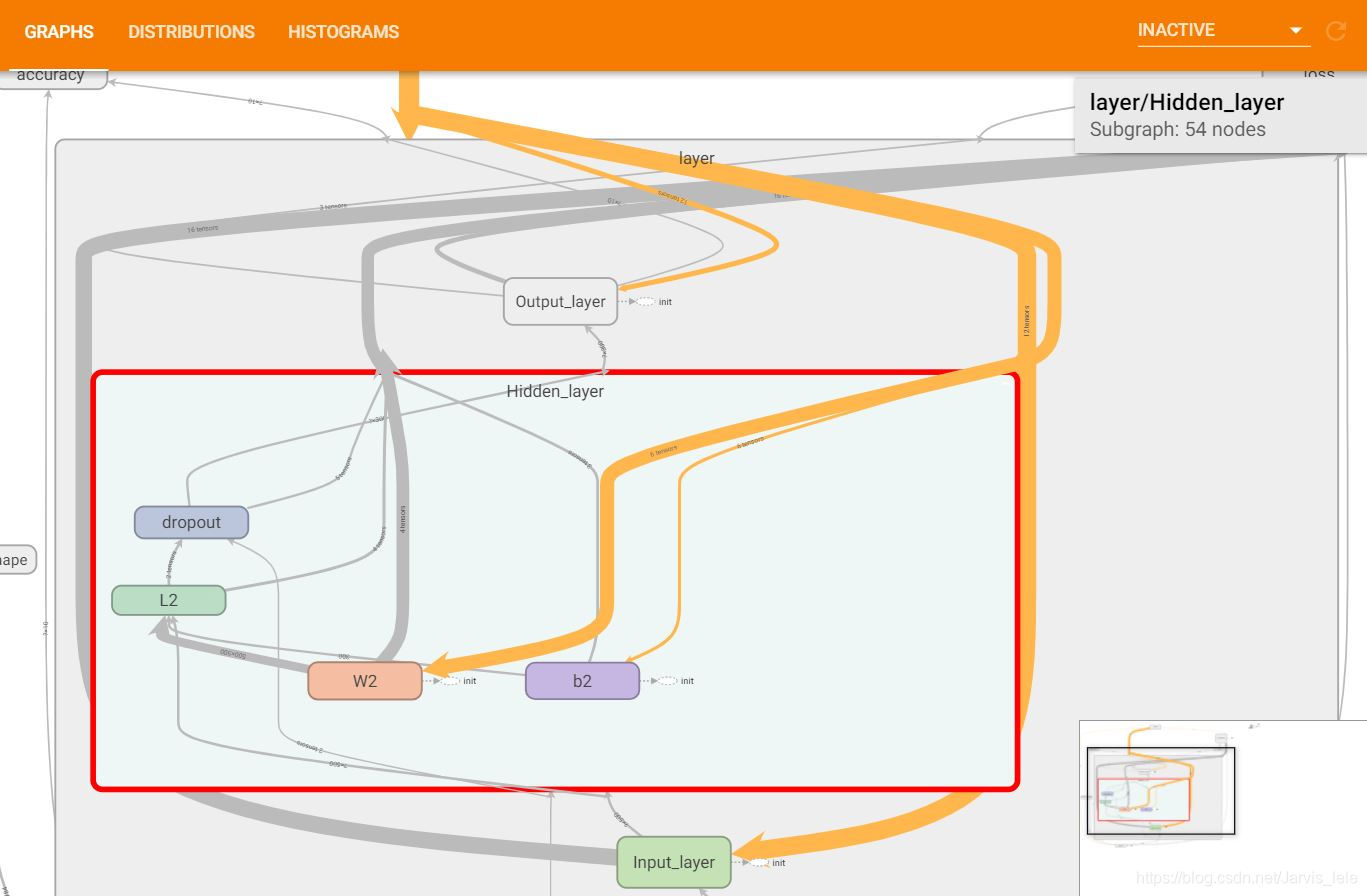
(4)GRAPHS
这里展示的是整个训练过程的计算图graph,从中我们可以清楚地看到整个程序的逻辑与过程。
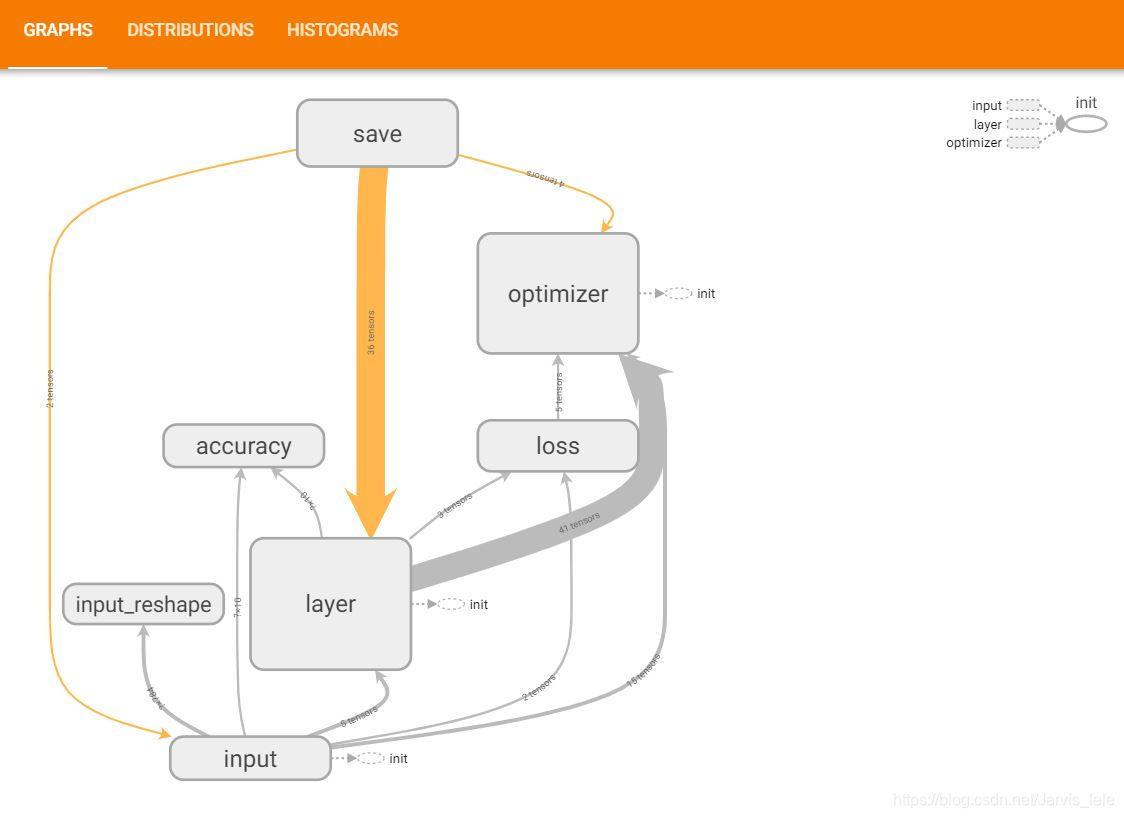
单击某个节点,可以查看属性,输入,输出等信息

单击节点上的“+”字样,可以看到该节点的内部信息。
(5)DISTRIBUTIONS
这里查看的是神经元输出的分布,有激活函数之前的分布,激活函数之后的分布等。
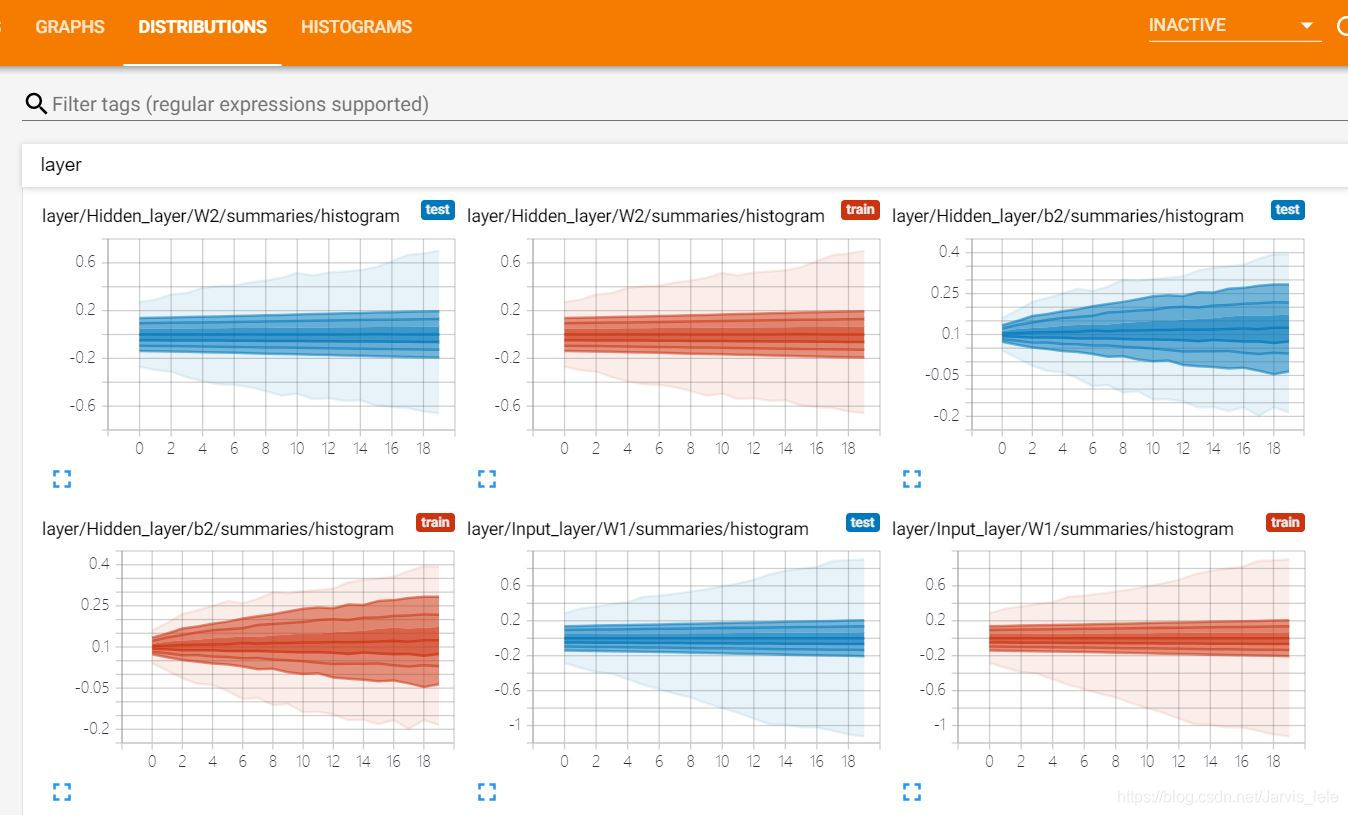
(6)HISTOGRAMS
也可以看以上数据的直方图

(7)EMBEDDINGS
展示的是嵌入向量的可视化效果,本案例中没有使用这个功能。之后其他案例中再详述。
完整代码:
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
'''
定义固定的超参数,方便待使用时直接传入。如果你问,这个超参数为啥要这样设定,如何选择最优的超参数?
这个问题此处先不讨论,超参数的选择在机器学习建模中最常用的方法就是“交叉验证法”。
另外,还要设置两个路径,第一个是数据下载下来存放的地方,一个是summary输出保存的地方。
'''
MODEL_SAVE_PATH="model"#模型保存路径
MODEL_NAME="mnist_model" #模型保存文件名
logdir='./graphs/mnist' # 输出日志保存的路径
dropout=0.6
learning_rate=0.001
STEP=20
# 每个批次的大小
batch_size = 100
# 计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var) ##直方图
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32, [None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')
# 保存图像信息
with tf.name_scope('input_image'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name='W1')
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries(b1)
with tf.name_scope('L1'):
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1, name='L1')
L1_drop = tf.nn.dropout(L1, keep_prob)
with tf.name_scope('Hidden_layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1), name='W2')
variable_summaries(W2)
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
variable_summaries(b2)
with tf.name_scope('L2'):
L2 = tf.nn.tanh(tf.matmul(L1_drop, W2) + b2, name='L2')
L2_drop = tf.nn.dropout(L2, keep_prob)
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
variable_summaries(W3)
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
variable_summaries(b3)
prediction = tf.matmul(L2_drop, W3) + b3
# 创建损失函数
with tf.name_scope('loss'):
# 计算所有样本交叉熵损失的均值
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar('loss', loss )
# 使用AdamOptimizer优化器训练模型,最小化交叉熵损失
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
# 计算准确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分别将预测和真实的标签中取出最大值的索引,若相同则返回1(true),不同则返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope('accuracy'):
# 求均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
saver=tf.train.Saver() #实例化saver对象
with tf.Session() as sess:
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data
merged = tf.summary.merge_all()
# 写到指定的磁盘路径中
train_writer = tf.summary.FileWriter(logdir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(logdir + '/test', sess.graph)
writer = tf.summary.FileWriter(logdir, sess.graph)
# 断点续训,如果ckpt存在,将ckpt加载到会话中,以防止突然关机所造成的训练白跑
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
for i in range(STEP):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
opt=sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,keep_prob: dropout})
train_sum, acc_train = sess.run([merged, accuracy],feed_dict={x: mnist.train.images, y: mnist.train.labels, keep_prob: 1.0})
train_writer.add_summary(train_sum, i)
# 记录训练集的summary
test_sum, acc_test = sess.run([merged, accuracy],feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0})
test_writer.add_summary(test_sum, i)
if i %2==0:
print("Iter" + str(i) + ", Testing accuracy:" + str(acc_test) + ", Training accuracy:" + str(acc_train))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME),global_step=step) # 保存模型
train_writer.close()
test_writer.close()
