1、Hadoop
MapReduce,大数据计算框架,map将数据写入磁盘,然后分发到reduce。只适合处理对处理速度不敏感的大数据计算任务。基于磁盘,大量网络传输。处理过程太死板,必须shuffle
HDFS,大数据存储系统
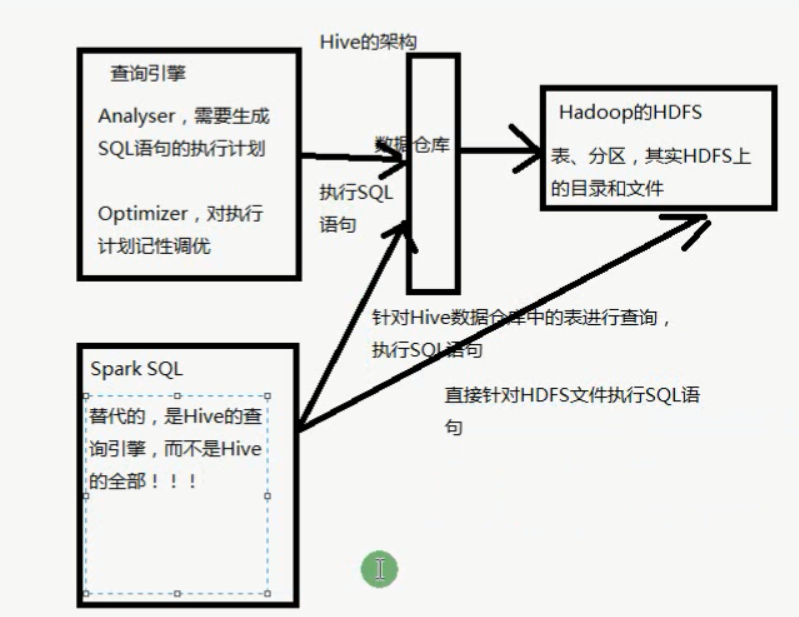
Hive,SQL,大数据查询框架/计算框架
HBase,NOSQL,实时/准实时查询,存储查询系统
YARN,资源调度
客户端,J2EE开发的一些数据系统,包含HQL的shell脚本,
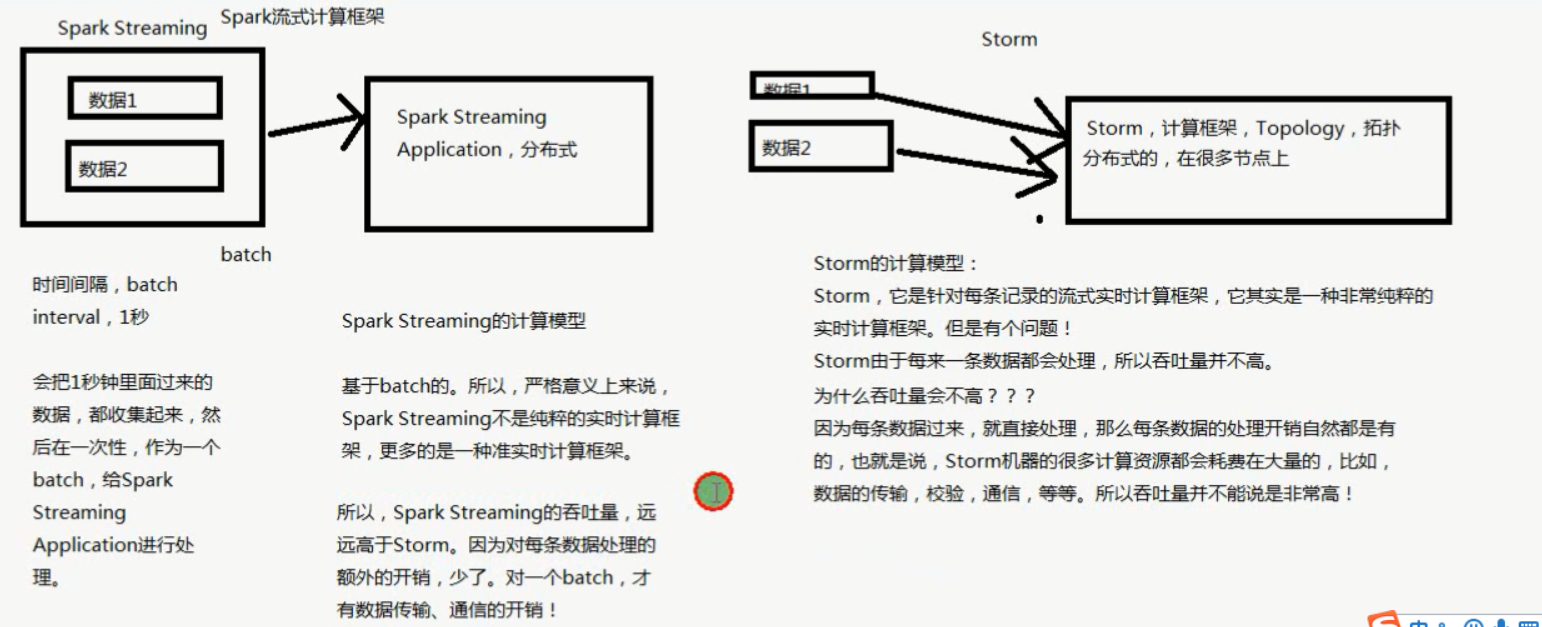
2、Spark,大数据计算框架。执行操作时,各种操作都在内存。比mapreduce和hive快几十倍。
HDFS,大数据离线计算和批处理
Hive,
Spark Core离线计算
扫描二维码关注公众号,回复:
11123477 查看本文章

Spark SQL交互式查询
Spark Stream实时流计算
Spark MLlib机器学习
Spark Graphx图计算
Spark RDD
Spark Engine
Yarn,Mesos,AWS
HDFS,S3,Cassandra
3、storm