因为最近在做手的分割,并且目前的思路是把它理解为一个对于手部的具体语义分割问题,所以对这个领域有了一点点的了解与认识,在这里总结一下。
模型设计
语义分割对分割精度要求比较高,尤其是物体的边界,所以需要对图像的信息进行充分的理解,因此从数据集学习的过程模型要经过精心设计。
目前思路
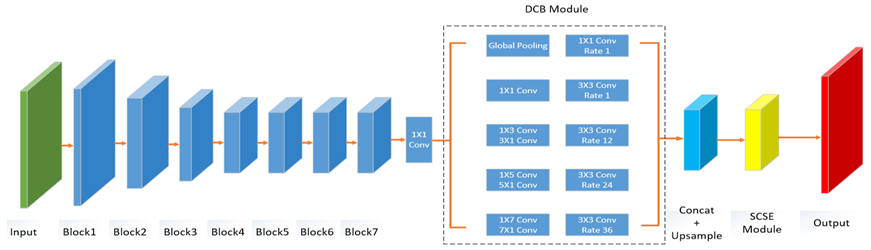
目前的思路是来自师兄的硕士毕业设计。通过Wide ResNet在充分提取图像信息,其性能与运算量已经达到了一个比较好的平衡,很多语义分析问题也都有采用这项技术,所以选取它做BackBone。很多文章都讨论过ResNet在深度和宽度上该如何权衡。
在Wide ResNet后接了一个空洞卷积模块,也是为了从多个尺度进行信息的融合。在DeepLab中使用了不同尺度的空洞卷积,PSPNet中使用了多尺度池化,能够结合网络低层的角点、边缘信息的同时考虑物体的抽象表示。
另外值得一提的是,很多语义分析模型现在的思路是用FCN与CRF/MRF结合,能够在充分提取信息的基础上尽可能提高精度。
pooling层虽然可以增大感受野,但是也会损失很多信息,而upsampling又无法恢复这些信息,所以就使用了空洞卷积,能够在减少损失的同时增大感受野,可以在一定程度上满足语义分割任务对精度的要求。
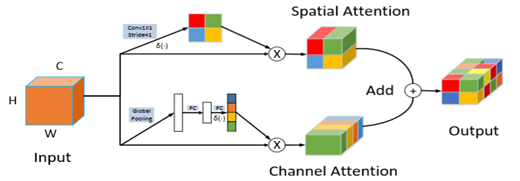
最后的部分的重点是Attention模块,分为空间Attention和通道Attention。Attention的思想便不用多说,实际上是为重要的部分赋予更大的权重。前者是在h和w平面上做一个权重控制,而后者主要是在通道做控制,即c这个尺度上赋予不同的权重,最终做一个结合能够提高准确率。
当然,也可以尝试优先空间或者优先通道,经过试验最终的效果还是并联好一点。
不说语义分析问题,就训练而言我们也可以用到一些比较先进的训练技术,比如BatchNorm是很重要的,那么我们可以用一些技术来优化内存占用或速度,再比如学习率是很重要的,学习率衰减的算法我们也可以好好选择,然后是泛化能力,我们可以在数据增强这里下功夫。
总的来说现在的思路效果还是很好的,至少在EgoHands上基本SOTA了吧,还没来得及看今年的文章,但是稍微优化一下应该会有更好的效果。比如CRF能不能结合一下,以及下面模型的一些思想能否融入进来,这都需要大量的实验作为基础。
RefineNet
RefineNet是16年底完成的工作,发表在CVPR2017上。其思路也是现在很多模型设计的主流思路,这里简单介绍一下。
因为图像理解过程中语义分割对图像精度要求比较高,尤其是在图像边界的部分。而随着频繁的卷积与池化,最后的输出分辨率缩减严重,很多细节信息都丢失了。为了克服这样的问题,有很多思路。比如反卷积、空洞卷积(在不增加参数的前提下获得更大的感受野,也是DeepLab的重要技术)和通过中间层特征生成高分辨率结果。
RefineNet中还提到了DeepLab的问题,比如需要高维特征,计算量较大,以及空洞卷积造成的一些信息丢失,都是会影响最终的精度。
RefineNet主要的工作便是在充分利用中间层特征上。因为中间层特征既包含一部分底层信息,又有抽象的表示,作用还是很大的。当然,残差模块仍然是基本模块,RefineNet表面上来看是对各层输出的结果做了一个结合,从而使抽象信息与角点信息有一个很好的结合,能够充分保留图像信息。
RefineNet refines low-resolution (coarse) semantic features with fine-grained low-level features in a recursive manner to generate high-resolution semantic feature maps.
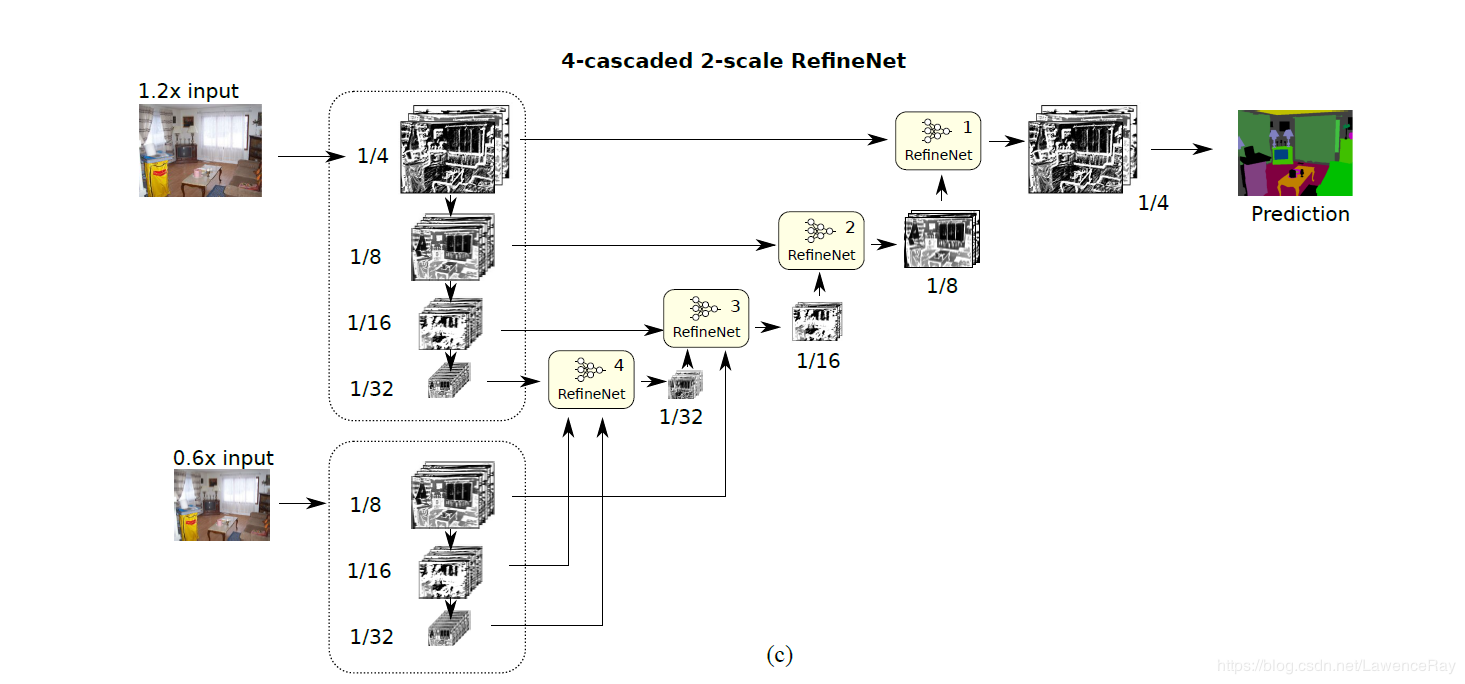
通过高低层之间的融合来提高精度,这种fusion的思想确实很值得借鉴。其提出大概也是在发现退化问题后尝试进行解决。当然,原文中还有很多高级的技术,比如Chained residual pooling,也是在计算量与精度的基础上进行精心设计的结构。

这篇文章还有待精度,但是其中各层的结合的思路确实值得思考。
MobileNet
复杂的模型速度相对比较慢,想要做到实时识别难度是很大的,尤其还要搭载在一些嵌入式设备中。这里就可以考虑2017年诞生的MobileNet的一些思路,目前MobileNet已经到第三个版本,无论是速度还是准确率上都有比较好的效果。
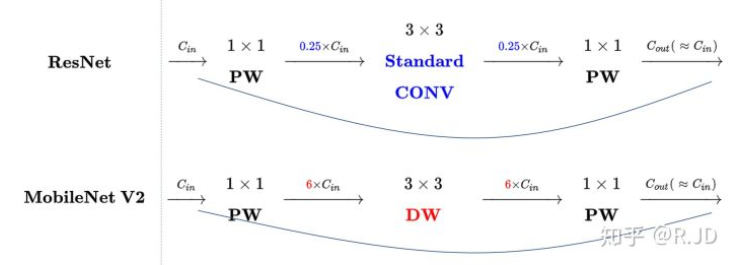
MobileNet的思路是把传统的卷积分成两步,分别是depthwise和pointwise,经过推导最终的计算量会有比较大的下降,而准确率损失的并不是很大,所以还是很划算的,尤其是追求实时性的嵌入式设备。而pointwise一般用1×1的卷积核来实现,在v1版本中会紧跟bn层和relu层,以提高模型的泛化能力。
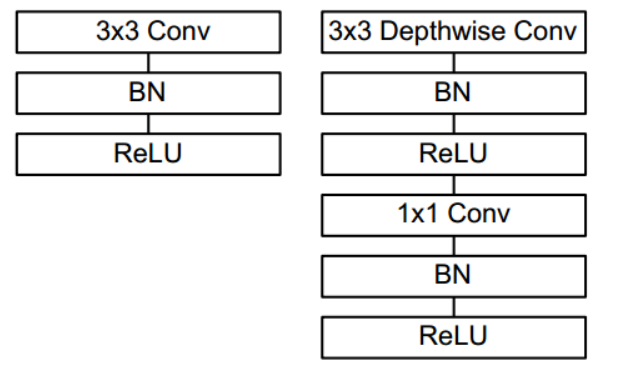
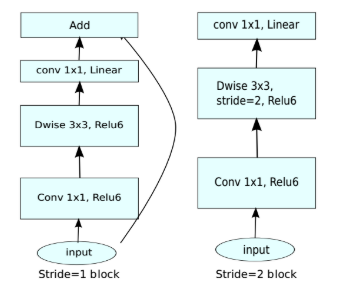
v2发表在次年,即2018年。在v1的基础上引入了Inverted Residuals和Linear Bottlenecks,因为v1时发现depthwise的卷积核容易失效。
一般的残差模块,会通过11的卷积进行研所,然后再33的卷积进行特征提取,最后再用11的卷积把通道变换回去从而减少33模块的计算量,提高残差模块的计算效率,即“压缩-卷积-扩张”。
而倒残差模块首先经过11的卷积进行扩张,然后33的depthwise卷积,最后再压缩回去,过程正好相反。因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。
至于Linear Bottlenecks,当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大,如下图所示。因此,认为对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。(具体参考:https://www.cnblogs.com/dengshunge/p/11334640.html)
因为这个问题,作者将最后一层的ReLU换成了线性激活函数,其他层的激活函数没有改变。
v3就更厉害了,还是用的automl利用NAS(神经结构搜索)来搜索网络的配置和参数,这种方法超出人工调参很多。v3在v2的改进比如说发现计算资源消耗比较大的是网络的输入层和输出层,使用了一些技巧。比如提前了池化层,维度的一些改变以及激活函数的选取,就比较细节了。
由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。
然后还加入了SE模块,即之前提到的注意力模块,在准确率上会有提升。
总结一下,从MobileNet的设计与发展可以看出,其目标是在保证准确率的情况下尽可能减少计算量提高速度。准确率的保证通过激活函数、层的设计、Attention甚至automl来实现。而速度上为了减少运算量创新地使用了卷积分离,事实证明对准确率损失很小而速度提升很大,这来自于对卷积操作的深入理解,并结合ResNet的很多思路。
实际效果
目前基于一些工作已经训练出了模型,但是在对它进行效果验证的时候还是挺让人失望的。尽管在原数据集上有不错的拟合效果,但是随便抽取了几张有手的图,可能是因为手的颜色或者形状甚至光照、手的位置与数据集中有较大不同,要么识别的特别不完整,只识别到手上几小块,要么过度识别,把脸也识别进去了。而且在没有使用轻量级模型的情况下,Tesla V100上的帧率可能只有2fps,与实时性差的很远。
这更让我觉得这只是在机械地拟合数据,实际应用还是受到很大限制。mIoU已经刷到这么高了,但是仍然与我们的目标效果还是有较大差距。语义分割本来也是一个比较有挑战性的任务,还是有很大研究的余地的。
我想这可能也是单张图片的局限性吧,实际应用可能还是视频会好一些,但对实时性或者说模型的速度要求就高了。
我现在觉得,不如通过目标检测框出手,这个准确率还是挺不错的,然后再通过比较高级的肤色建模将手分割出来,泛化能力肯定比现在的好,相当于传统方法与深度学习方法的一个结合吧。
延伸思考
深度学习是数据与模型结合的过程,我们追求的既有模型的准确率也有模型的速度,无论你在哪个方面取得一定进展,都可以考虑发文章。而深度学习本质上还是一个高维的模式识别问题,所以局限性还是很多,在某个场景下效果非常好的模型在另一个场景下效果可能就让人难以接受。
比如手分割的问题,在EgoHands上mIoU可能都将近90了,但是很多实际场景下的效果还是无法应用。对于这件事我们需要从两个角度来看待:第一,还是数据集过于局限,尽管EgoHands有4800张像素级标注的图像,但是其场景和形式还是比较单一,如果放在日常生活中先不说一些特殊场景,与人的辨识能力自然是有很大差距,即使是说深度学习在模仿人学习的过程,我想一个有辨识能力的人从出生到现在学习过的场景是难以计算的,所以有差距是自然的;第二,那我们就要去适应这种现实,至少在人工智能的下一次技术突破到来之前,毕竟数据场景局限的问题是难以消除的,假如像素级标记几十亿张图像在训练很久很久以后的模型我想效果肯定不错,但是这样的成本是我们现阶段难以付出的,所以不如应用时便局限于某个场景,在某个场景做的足够好也能够实现很多应用。
总的来说,要想追求人的效果如果还是以这种思路发展下去,至少在语义分割领域我觉得是难以达到的,尽管模型设计的无比的好,能够在某个数据集上mIoU接近于100,但换到其他数据集或者是日常场景中,可能效果又很差,而且一般的轻量级模型可能也难以达到这样的准确率。所以我觉得做研究不能为了提升准确率而做,这只是结果,我们应该做的还是找新的思路,尽管效果可能暂时达不到SOTA。
另外,人对世界中物体间边界的认识,是有“动”的因素的,视差以及甚至亲自去感受过这个物体,在大脑中形成一个粗略的建模,才会有记忆,如果在没有认识先验知识的情况下看到一张图片,可能也不知道该怎么分割,所以我觉得还是得从这个角度来出发。
或者说我决定我们不能从人认识世界的结果来训练模型,而是应该让模型学习我们认识的过程。说的容易但是实现起来可能很难。但或者可能只有找到新的思路来衡量物体,比如不要再仅仅通过mask图像,而是学习OpenPose的一些思路,这样可能实现一套在一定的训练下能够举一反三,更能模仿人认识世界的系统,或者不模仿人从另一个角度认识世界但也能达到同样的效果。
