FCN学习笔记
FCN(Fully Convolutional Networks for Semantic Segmentation)
Semantic Segmentation
语义分割问题,简而言之,就是在一幅图像中划分不同物体,将属于同一物体的像素用一个标签进行标注。比如说这样:

在深度学习应用到计算机视觉领域之前,研究人员一般使用纹理基元森林(TextonForest)或是随机森林(Random Forest)方法来构建用于语义分割的分类器。2014年,加州大学伯克利分校的Long等人提出的全卷积网络(Fully Convolutional Networks),推广了原有的CNN结构,在不带有全连接层的情况下能进行密集预测。
FCN特点
1.输入可以是任意大小
2.可以实现像素级的预测
3.学习和推理都是对整张图片同时处理的
4.同时实现了语义分析和定位
区别于传统CNN:1.固定大小的输入 2.输出是一维的
FCN的三个主要技术
1.卷积化(Convolutionalization)
在VGG,Resnet等分类网络中,网络末端是由三个全连接层构成的。在FCN中,我们需要换成卷积层。如图所示:

这里对卷积化进一步解释:
输入为224x224x3的向量,经过VGG网络到全连接层之前,输出维度为7x7x512的向量。这里要换成全连接层,也即是1x1卷积层。这一步完成后,输出的是1x1xn的向量。
这个过程也可以叫做特征提取或下采样,或Encoder。
那么如何使得输出为spatial output呢?
可以看到这里的HxW为224x224,一般来说,我们会对输入图像做padding=100的操作。这样,输入大小就远大于224x224了,输出大小也就是变大了,也就是coarse output。

2.上采样(In-network Upsampling)
在经过卷积化以后得到coarse input,但是,这时的输出大小还不是原图大小,要想复原大小,我们还需要上采样的操作。
上采样主要有三种实现方式:
1.反池化(Unpooling)
这里用最大池化举例:
我们需要记住最大值所在位置即Pooling Indices,然后经过unpooling可得到与原图大小相同的输出。但是,这里的问题是,我们会丢失掉一些细节。
2.插值(Interpolation)
主要是双线性插值(Bilinear Interpolation)主要思路是:若想求P点的值,那么,我们取P点周围四个点
。分别求直线
,
与过P点垂线交点
。然后由于直线
过点P,则P点值可求得。
3.转置卷积(Transposed Convolution)
转置卷积的原理:
卷积运算可以表示为矩阵运算。
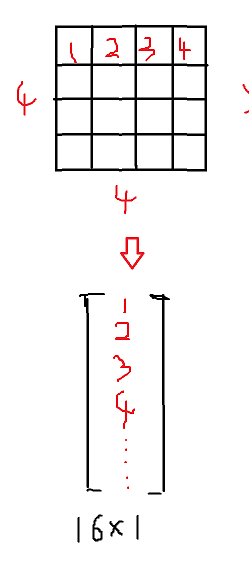
假设我们kernel size=3,如下图,那么,卷积后我们得到一个2x2的结果。
现在,我们把4x4的输入,变换为16x1的向量。
我们可以把卷积表示为矩阵形式,如下:
我们定义这三个矩阵分别为为
,则上图可表示为
。
若求矩阵A,则只需计算
。
这里是动图演示:




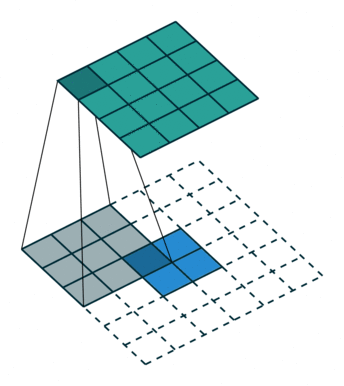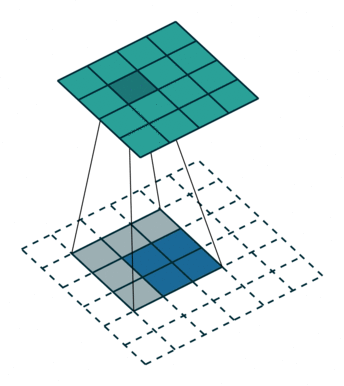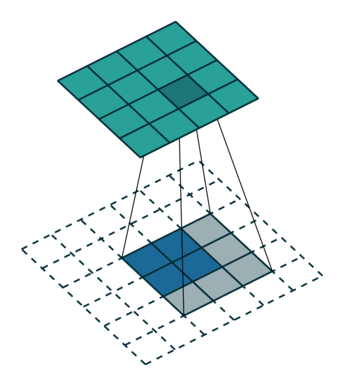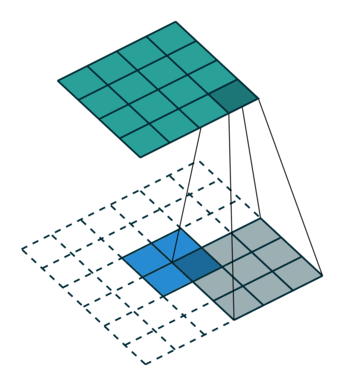
如果不在conv1_1加入pad=100,那么对于小于192x192的输入图像,在反卷积恢复尺寸前已经feature map size = 0!所以在conv1_1添加pad=100的方法,解决输入图像大小的问题(但是实际也引入很大的噪声)。
- 由于FCN在conv1_1加入pad=100,同时fc6卷积层也会改变feature map尺寸,那么真实的网络就不可能像原理图3那样“完美1/2”。
那么在特征融合的时候,如何保证逐点相加的feature map是一样大的呢?这就要引入crop层了。以fcn-8s score_pool4c为例:
layer { name: "score_pool4c" type: "Crop" bottom: "score_pool4" # 需要裁切的blob bottom: "upscore2" # 用于指示裁切尺寸的blob,和输出blob一样大 top: "score_pool4c" # 输出blob crop_param { axis: 2 offset: 5 } }在caffe中,存储数据的方式为:caffe blob = [num, channel, height, width]
- 而score_pool4c设置了axis=2,相当于从第2维(index start from 0!)往后开始裁剪,即裁剪height和width两个维度,同时不改变num和channel纬度
- 同时设置crop在height和width纬度的开始点为offset=5
不妨定义:
crop_w = upscore2 blob width crop_h = upscore2 blob height用Python语法表示,相当于score_pool4c层的输出为:
score_pool4c = score_pool4[:, :, 5:5+crop_h, 5:5+crop_w]
刚好相当于从score_pool4中切出upscore2大小!这样就可以进行逐点相加的特征融合了。
3.跳跃结构(Skip Architecture)
这个结构的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是包含的位置信息很不充分,所以作者将不同池化层的结果进行上采样之后来优化输出,可以提高精度。具体结构如下:

不同上采样结构得到的结果对比如下:

这里的32s,16s,8s代表上采样多少倍。
当然,你也可以将pool1, pool2的输出再上采样输出。不过,作者说了这样得到的结果提升并不大。
