一、线性表的应用
-
线性表合并函数
List union_list(List L1, List L2) { List L; // 合并的线性表。 int size1=getSize(L1), size2=getSize(L2); // 线性表 L1,和 L2 的大小。 ElemType e1, e2; // 线性表 L1 和 L2 的元素。 int i1=0, i2=0; // 线性表 L1 和 L2 的索引。 initial(&L); // 初始化 L。 while (i1<size1 && i2<size2) { e1 = getElem(L1, i1); // 取得 L1 的元素。 e2 = getElem(L2, i2); // 取得 L2 的元素。 // 将 L1 和 L2 较小的元素放到 L 中,并移到下一个元素的位置。 if (e1<e2) { insert(&L, e1); i1++; } else if(e1 == e2){ insert(&L, e1); i1++; i2++; } else {insert(&L, e2); i2++;} } // 继续复制 L1 的元素。 while (i1<size1) insert(&L, getElem(L1, i1++)); while (i2<size2) insert(&L, getElem(L2, i2++)); return L; }
-
线性表L:含有L1和L2共同元素
List intersection_list( List L1, List L2){ List L; //有L1和L2共同元素的线性表。 int size1=getSize(L1), size2=getSize(L2); // 线性表 L1,和 L2 的大小。 ElemType e1, e2; // 线性表 L1 和 L2 的元素。 int i1=0, i2=0; // 线性表 L1 和 L2 的索引。 initial(&L);//初始化L。 while (i1<size1 && i2<size2) { e1 = getElem(L1, i1); // 取得 L1 的元素。 e2 = getElem(L2, i2); // 取得 L2 的元素。 // 把L1和L2相同的元素放入L中。 if(e1<e2){ //L1和L2元素不相等,不放入L中。 i1++; } else if(e1==e2){ //L1和L2元素相等,放入L中。 insert(&L, e1); i1++; i2++; } else i2++; //L1和L2元素不相等,不放入L中。 } return L; }
二、初步了解web scraping
-
概念解析
Web scraping基于Python语言,即在网上获取数据的代码,又统称为“爬虫”。但是“爬虫”又分为两种:一种是网络爬虫(Web crawler);另一种是网页抓取(Web scraping)。学习Web scraping,首先要了解网页是由代码组成,这些代码称为HTML。HTML是一种浏览器看得懂的语言,浏览器能将这种语言转换成我们肉眼看到的网页,所以我们可以用爬虫按照HTML里面存在的规律来爬取所需要的信息。
-
了解源代码——HTML
HTML的起始标签是<html>,终止标签是</html>,其中间是所有HTML的代码,它又分为两个部分<head>和<body>,<head>是我们在网页上看不到的,包含了一些网页的源信息,而<body>是会被显示在网页上的,我们爬取的大多数是<body>里的信息。
-
用Python爬取网页数据
首先从Python脚本里导入urllib这个库,urlopen打开网页链接,而中文不能直接读取,需要用decode解析一下。然后,用正则表达式选取文本信息。然而使用Python的正则表达式进行匹配会出现有些我们不想要的信息,所以我们会采用BeautifulSoup来进行解析网页。同时每个网页不止由HTML组成,还由CSS来“装饰”网页。而每个CSS都有不同类型数据的Class组成,所以我们可以用Class来更快的筛选出我们所需要这一组里面的部分数据,即不会出现这一组里面我们不需要的数据。而且我们还可以利用正则表达式和BeautifulSoup相结合来获取更有难度的信息。
我们通常使用Python的自带模块urllib来提交网页请求,这个模块能满足我们大部分的需求,但是为了满足我们日益膨胀的其他需求,比如向网页发送信息,上传图片等等,我们常用Python外部模块requests来有效的处理这些问题,会有更好的兼容性。其实在加载网页时候,最重要的类型是get和post等,这些是打开网页的关键。其中用get向网页提交个人信息会再返回你的个人信息放在urllib里面,而post不会。当用post登录时若其登录状态是连续时,我们就要用到cookies,放到我们下一次登录的指令里面,即可以用登录状态访问下一个网页;或者我们用session来进行post的操作,即这时候就可以不用把cookies放到下一次登录指令中。
当我们想要更快速、更便捷的爬虫方法时,就要运用多进程分布式爬虫,即运用Python的multiprocessing(多进程)或者使用异步加载Asyncio。但是如果不仅想要爬网页还想处理数据就要运用到scrapy(爬虫高级库)。它会自动帮我们处理看过和没有看过的网页并且自动帮我们分析,然后得到response。
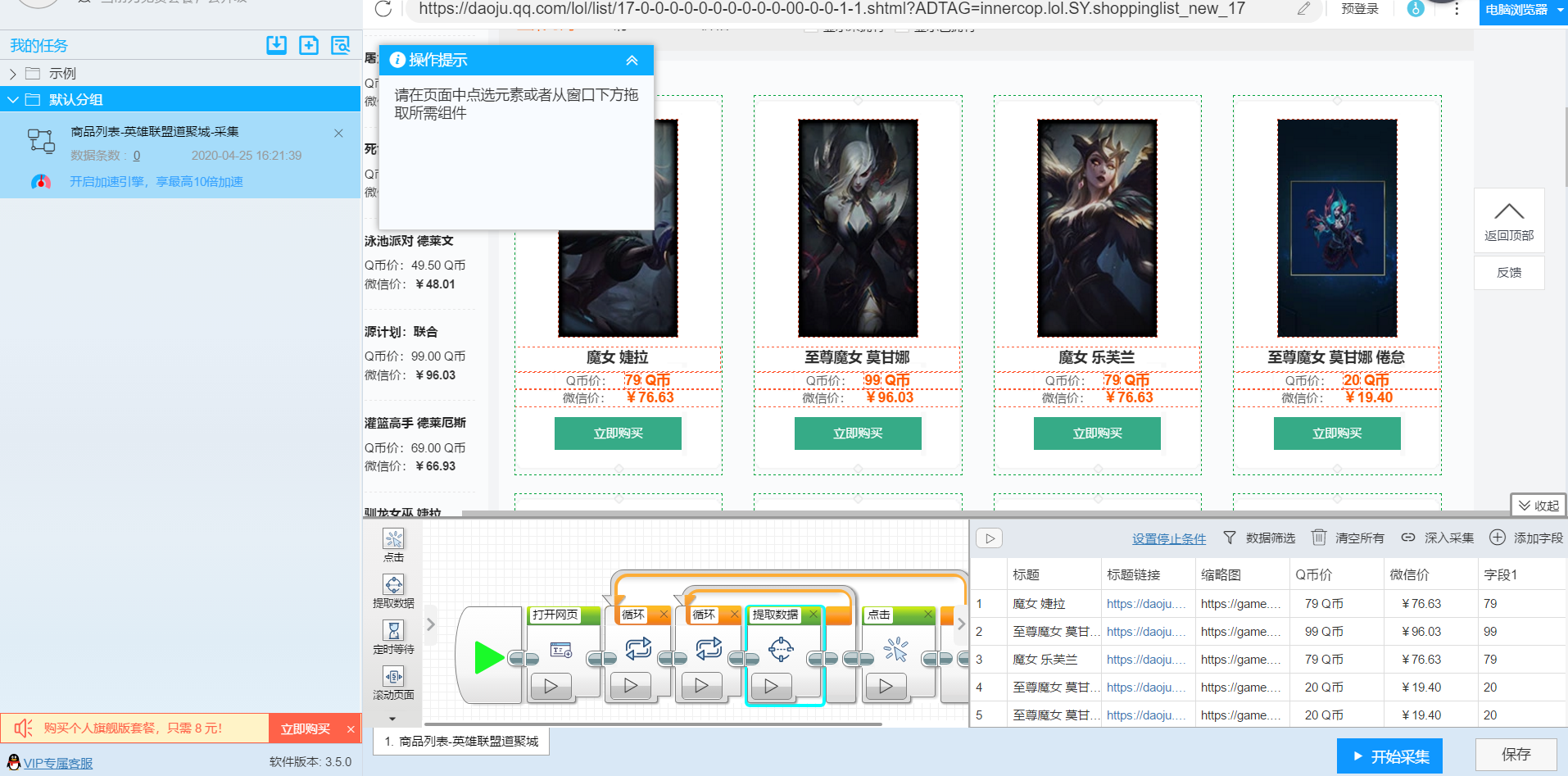
三、利用“后羿采集器”爬取网页数据
-
流程图模式爬取LOL皮肤数据