自制中国各区县经纬度查询工具
1. 引言
1.1 问题描述
在进行空间数据可视化的过程中,之前使用一些在线的坐标转换工具,发现存在着小的瑕疵,偶尔还会把对应地址的经纬度的错误信息返回回来,有些时候数据的精度还达不到需求,这种情况下就不是加快工作的进度,而是给正在处理数据的人添堵了。
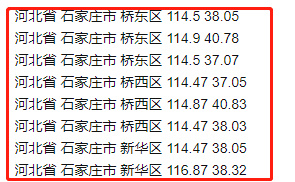
比如使用Geocoding地图工具转换,关于河南省相关的县,返回的数据存在着错误

1.2 基本思路
由于上面的问题存在,因此就产生了自己创建一个经纬度查询工具的想法。基本思路就是,把中国几乎所有的市区县的经纬度全部获取到,然后保存在本地(或者数据库),之后如果要使用其中部分的市区县数据,直接就可以去匹配,然后输出目标地址的经纬度信息了

2. 获取全国市区县的名称
全国的市区县太多了,光靠手动的进行填写或者一个个搜索根本不符合编程人员的正常思维,所以就开始搜集信息了,然后在豆瓣上找到给出的市区县的数据,而且附带的有经纬度,但是数据的精度不够,而且存在着数据重复的现象。豆瓣上的数据
2.1 数据初阅
浏览里面前面一部分的信息,发现存在着重复的信息,最后的经纬度竟然不一样,如下
2.2 数据转移
本着解决问题出发的角度,好不容易找到这么完备的市区县的数据,既然经纬度的信息不对,那就自己找对应的经纬度信息。首先要解决的问题是获取这里市区县的信息,然后对数据进行去重。操作如下,将豆瓣上的数据全部复制到新建的Excel表格中,然后数据按照空格分列后保存。注意:为了避免争议,这里剔除港澳台相关的数据

2.3 数据去重
使用python进行数据的去重,代码如下
import pandas as pd
df = pd.read_excel(r'C:\Users\86177\Desktop\city_lng_lat.xlsx')
data = df[['省份','地市','区县']] #剔除掉经纬度信息
print(len(data)) #未去重之前的数据量
data.drop_duplicates(inplace = True)
print(len(data)) #去重之后的数据量
→ 输出的结果为:(可以看出是有重复数据的,这里也进行了清理)
3179
3134
查看一下区县字段的数据计数情况及最高出现的数据
print(data['区县'].value_counts()[:5])
print(data[data['区县'].str.contains('市中区')])
→ 输出的结果为:(由此可见,数据中的重复值已经清洗完毕)
市中区 6
郊区 5
城区 4
鼓楼区 4
新华区 3
Name: 区县, dtype: int64
省份 地市 区县
1372 山东省 济南市 市中区
1405 山东省 枣庄市 市中区
1446 山东省 济宁市 市中区
2304 四川省 广元市 市中区
2319 四川省 内江市 市中区
2326 四川省 乐山市 市中区
3. 获取全国市区县的经纬度数据
3.1 数据获取路径
为了避免大厂提供的坐标拾取系统的反爬虫机制,这里选择一个综合性的坐标拾取的网站进行数据获取,数据获取的网址,如下(默认选取的是腾讯高德地图数据)

3.2 数据样本
读取刚刚保存的全国市区县的数据,然后选择某个地方的数据作为样本(这里取北京,地区狭窄,区域较多),如下
。北京地区的数据又刚好是所有“省份”字段中的第一个,所以在进行数据切片的时候第一个就是北京
data_demo = data[data['省份'].str.contains('北京市')]
data_demo['地址'] = data_demo['省份'] + data_demo['地市'] + data_demo['区县']
print(data_demo)
→ 输出的结果为:(共有20条数据,为了避免“区县”字段重复数据的影响,添加了一个“地址”字段,保证数据的唯一性)
省份 地市 区县 地址
0 北京市 北京市 北京市 北京市北京市北京市
1 北京市 北京市 天安门 北京市北京市天安门
2 北京市 北京市 东城区 北京市北京市东城区
3 北京市 北京市 西城区 北京市北京市西城区
4 北京市 北京市 崇文区 北京市北京市崇文区
5 北京市 北京市 宣武区 北京市北京市宣武区
6 北京市 北京市 朝阳区 北京市北京市朝阳区
7 北京市 北京市 丰台区 北京市北京市丰台区
8 北京市 北京市 石景山区 北京市北京市石景山区
9 北京市 北京市 海淀区 北京市北京市海淀区
10 北京市 北京市 门头沟区 北京市北京市门头沟区
11 北京市 北京市 房山区 北京市北京市房山区
12 北京市 北京市 通州区 北京市北京市通州区
13 北京市 北京市 顺义区 北京市北京市顺义区
14 北京市 北京市 昌平区 北京市北京市昌平区
15 北京市 北京市 大兴区 北京市北京市大兴区
16 北京市 北京市 怀柔区 北京市北京市怀柔区
17 北京市 北京市 平谷区 北京市北京市平谷区
18 北京市 北京市 密云县 北京市北京市密云县
19 北京市 北京市 延庆县 北京市北京市延庆县
3.3 Selenium自动化工具
有了网页可以进行数据的查找,就可以进行自动化的获取市区县的经纬度数据了,这里使用selenium进行自动化获取数据。
3.3.1 相关模块的导入及启动浏览器
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
import time
import os
browser = webdriver.Chrome() #已经设置过驱动了
browser.get('http://www.gpsspg.com/maps.htm') #加载网址
time.sleep(5) #设置等待时间
3.3.2 封装获取数据的函数
def get_data(data):
data_num = len(data) #计算数据长度作为循环的依据
num_sum = data_num #复制一下总长度,为了构建count计数器
site_list = [] #创建保存字段的列表,为了生成DataFrame,保存数据到本地
while data_num:
site_dict = {} #创建保存字段的字典
count = num_sum-data_num + 1 #创建count计数器
data_site = data['地址'].values[count-1] #获取地址字段的数据,用于获取经纬度
site_name = data['省份'].values[count-1] #获取省市的数据,用于创建生成Excel文件的命名
data_input = browser.find_element_by_xpath('//*[@id="s_t"]') #获取文字输入框
data_enter = browser.find_element_by_xpath('//*[@id="s_btn"]') #获取确认搜索按钮
data_input.send_keys(data_site) #将数据送入搜索框
time.sleep(0.5) #设置反应等待时间
data_enter.click() #点击搜索按钮
time.sleep(1) #等待数据刷新
data_lat_lng = browser.find_element_by_xpath('//*[@id="curr_xy"]').text #获取刷新出来的经纬度数据
data_lat = data_lat_lng.split(' ')[0].split(',')[0] #获取纬度数据
data_lng = data_lat_lng.split(' ')[0].split(',')[1] #获取经度数据
site_dict['地址'] = data_site #将地址信息存入字典
site_dict['经度'] = data_lng #将经度数据存入字典
site_dict['纬度'] = data_lat #将纬度信息存入字典
site_list.append(site_dict) #将字典信息保存到列表中
#设置输出提示
print(f'正在爬取第{count}条数据\n地址:{data_site},经度:{data_lng},纬度:{data_lat}')
data_input.clear() #清空文字输入框
data_num -= 1
save_data(site_list,site_name) #保存爬取的数据
3.3.3 封装保存数据的函数
def save_data(site_list,site_name):
data_1 = pd.DataFrame(site_list) #将上面爬取的数据生成DataFrame数据,为了将“省份”,“地市”和“区县”三个字段的数据合并
data_2 = pd.merge(data_province, data_1, on='地址') #合并数据,得到目标格式的数据
os.chdir('d:')
if not os.path.exists('China'):
os.makedirs('China') #这三行代码是在d盘下面创建一个文件夹保存生成的excel文件
data_2.to_excel(f'd:/China/{site_name}.xlsx', index= False) #保存文件
print(f'\n\n\n已经爬取{site_name}各市区县经纬度数据\n\n\n') #完成提醒
3.3.4 创建接口执行程序
使用selenium模块是需要网络顺畅的,如果一次性爬取全部的信息,假设3000条数据,那么加上等待时间是1.5,就是4500s,也就是75min,如果出现网络波动就会导致数据获取异常。因此为了最大化的避免这个问题对获取结果的影响,选择分块(按照各省)进行数据的获取,也方便核实数据
if __name__ == '__main__':
df = pd.read_excel(r'C:\Users\86177\Desktop\city_lng_lat.xlsx')
data = df[['省份','地市','区县']]
print('未去重前的数据量:{}'.format(len(data)))
data.drop_duplicates(inplace = True)
print('去重后的数据量:{}'.format(len(data)))
data['地址'] = data['省份'] + data['地市'] + data['区县']
for province in data['省份'].unique()[:1]:
data_province = data[data['省份'] == province]
print(f'正在爬取{province}经纬度数据......')
get_data(data_province)
→ 输出的结果为:(程序执行后会调用谷歌浏览器进行数据的爬取,这里爬取的是北京市数据)
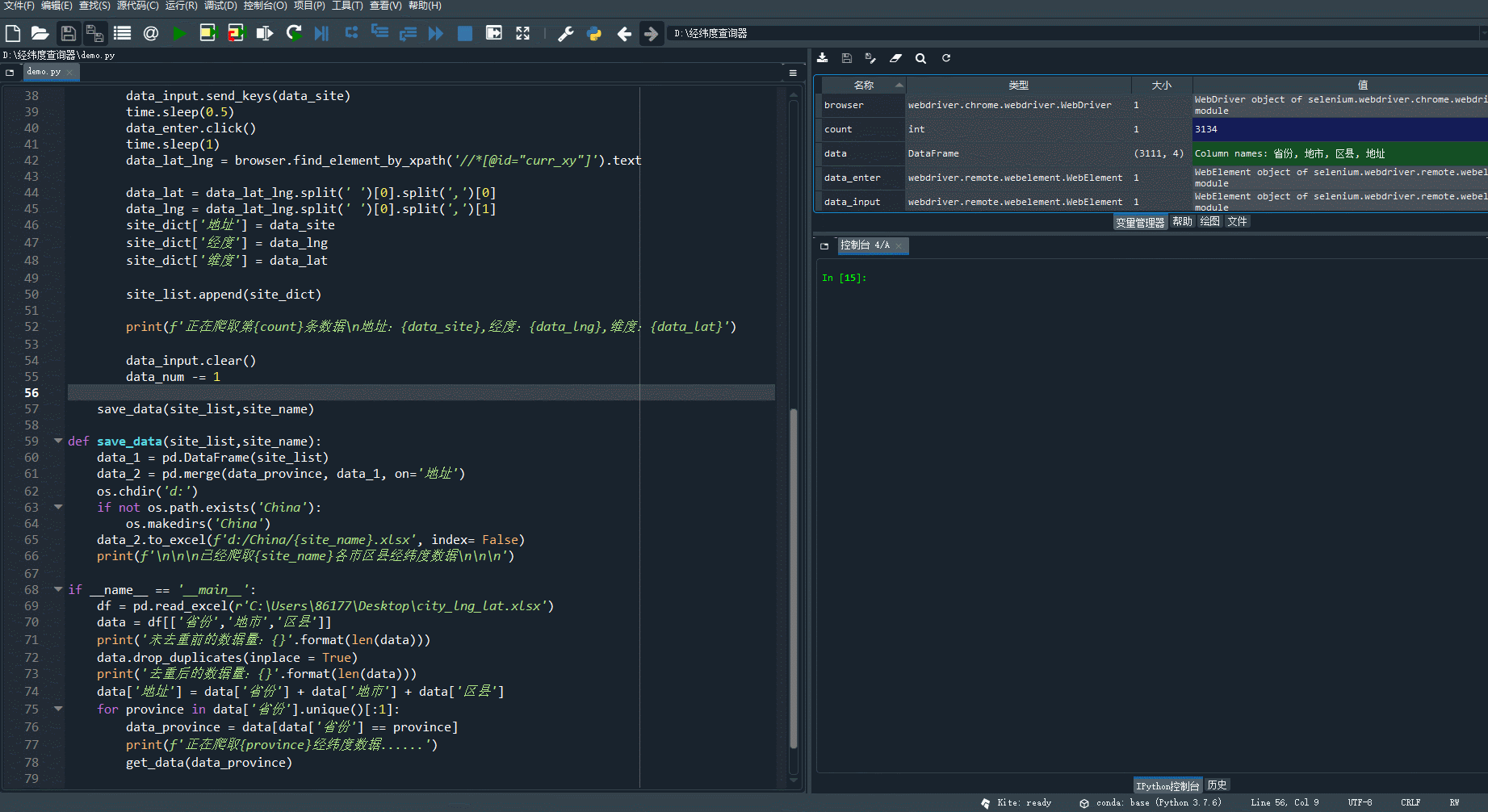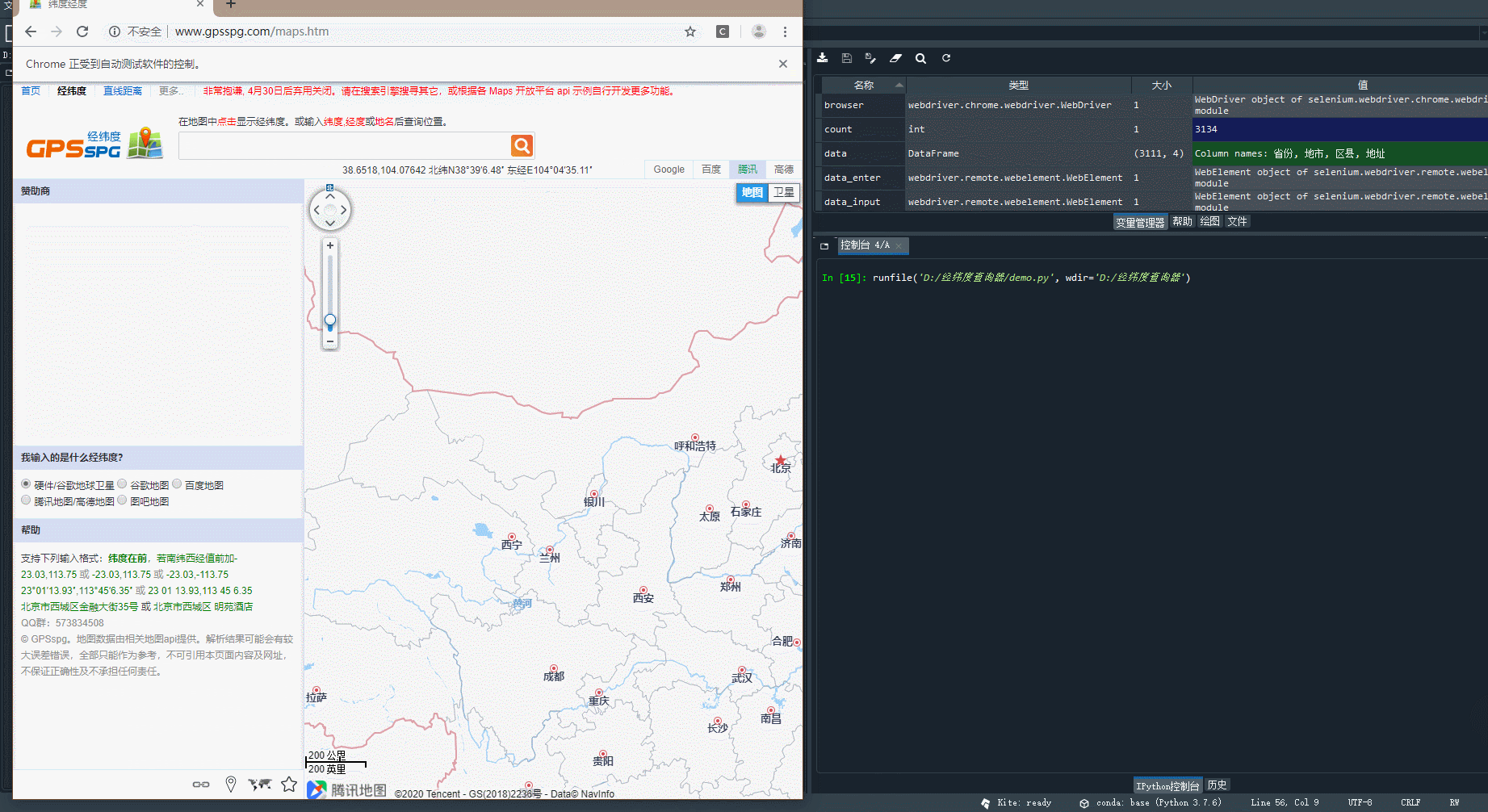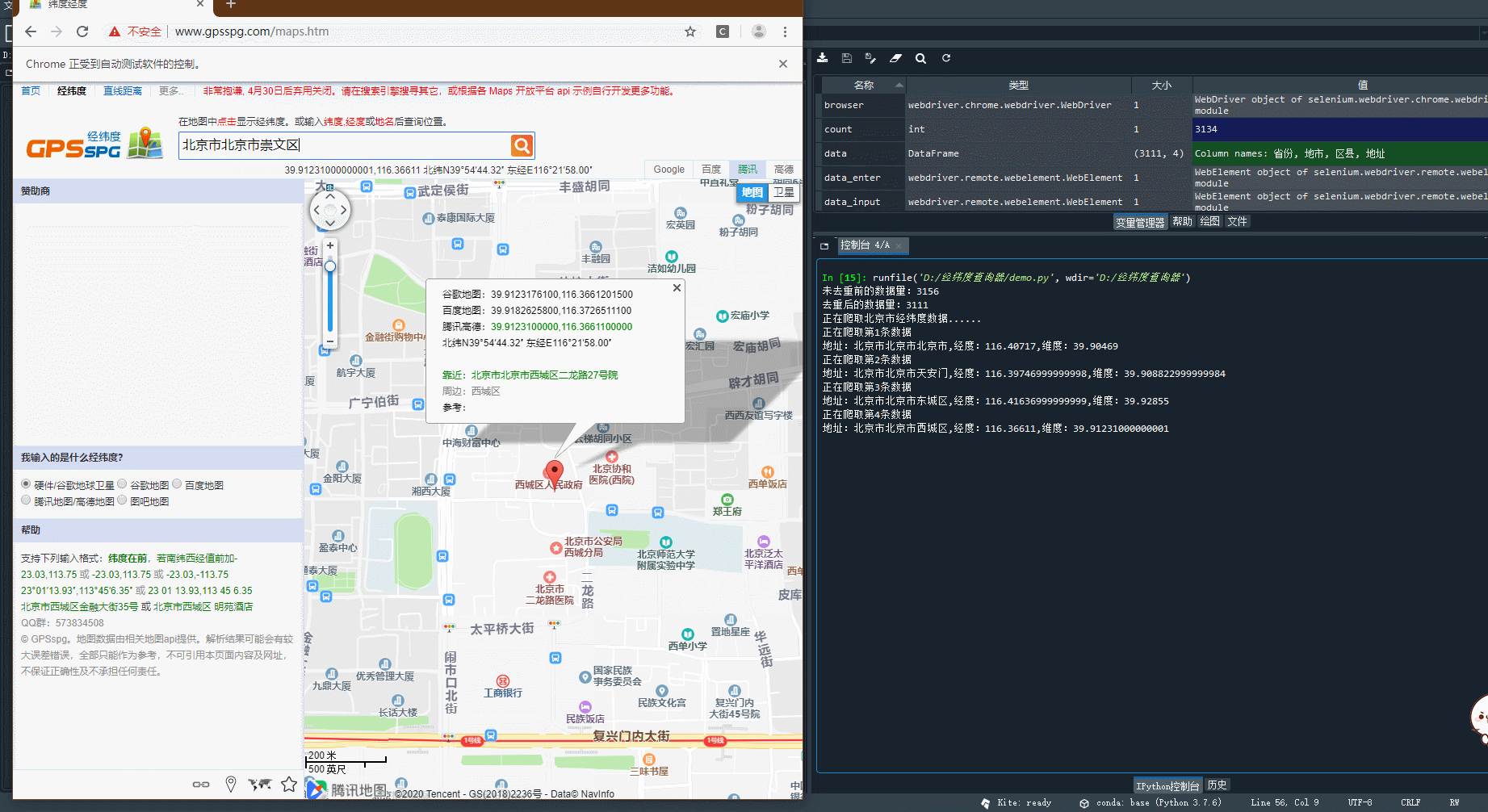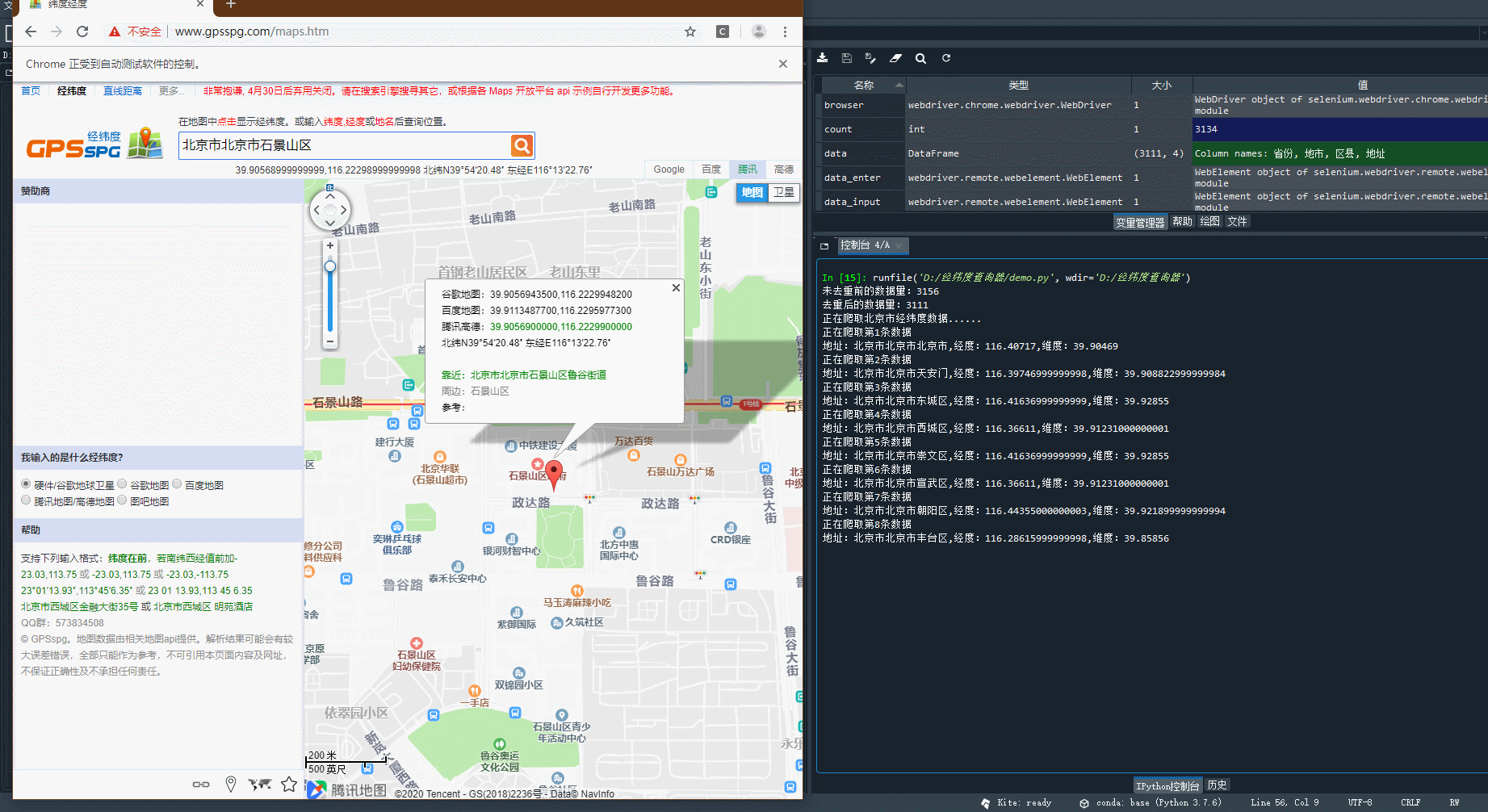
由此可以获取样本中北京各地区的经纬度,关于城区中的五个区,划分的太细了,可见地图识别是将东城区和崇文区归为同一个位置,西城区和宣武区归为同一个位置,结合北京市城区的地图,可知这种划分还可以在可理解的范围之内,除此之外并没有相同的经纬度信息,证明样本数据采集成功,如下

3.4 获取全部市区县的经纬度数据
上面是以北京市的市区县名称作为样本,可以发现返回结果无误后,接着就是获取全部的数据,这里只需要拿加载的data数据进行Selenium自动化数据的采取即可,也就是修改切片的范围(建议5个省市一次,保证准确率),最后获取全部数据。
比如:湖北省数据爬取过程…
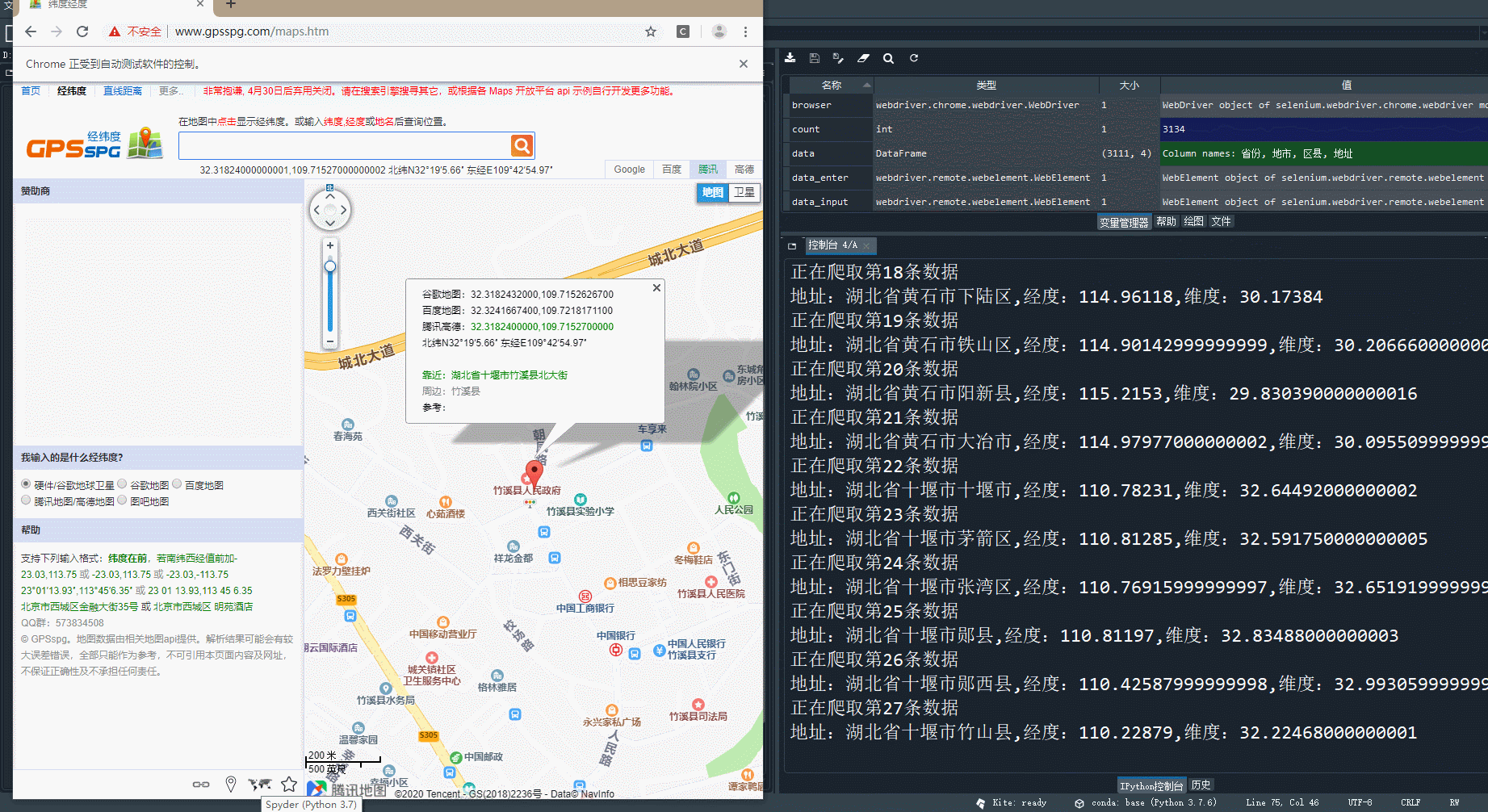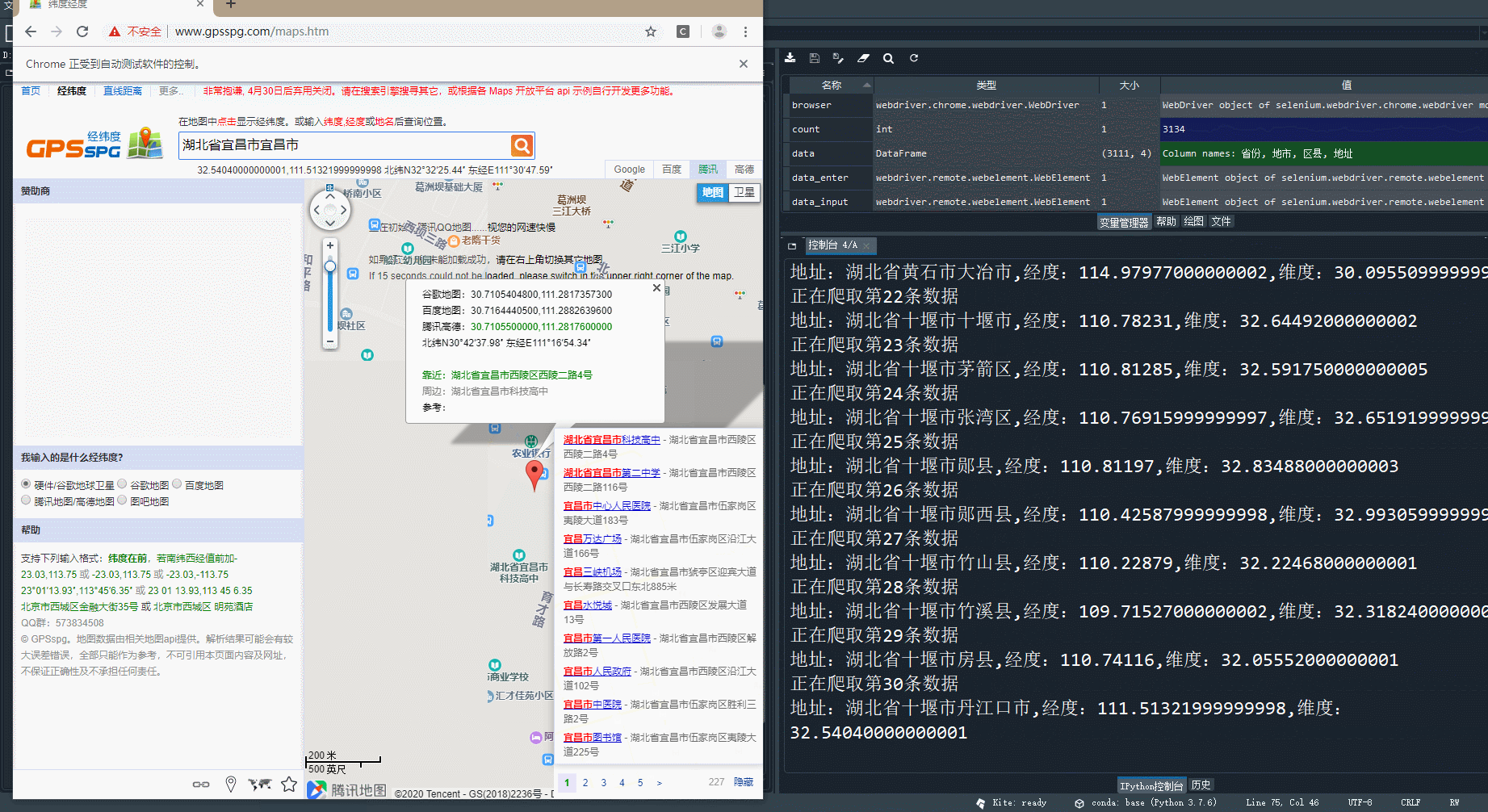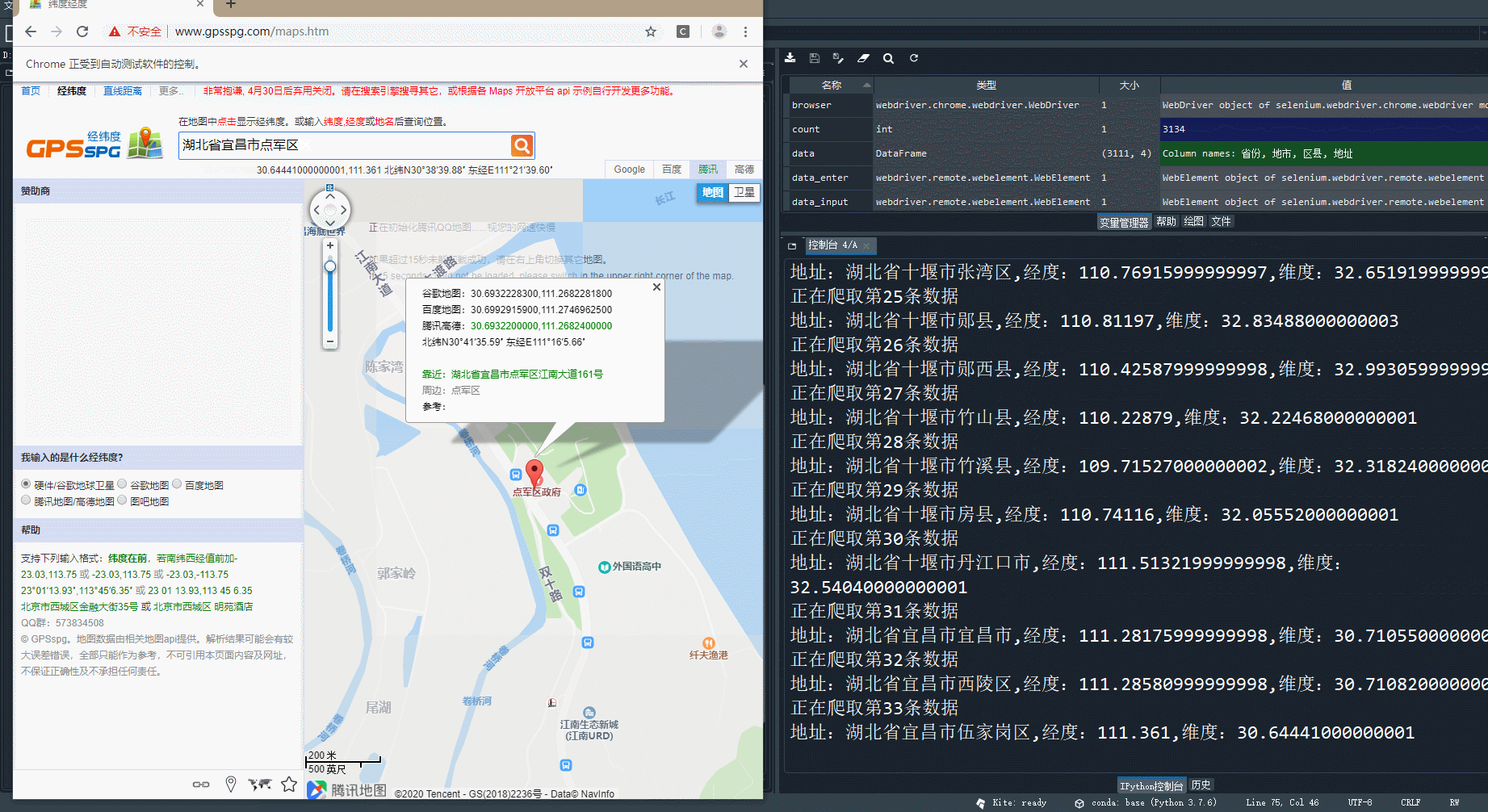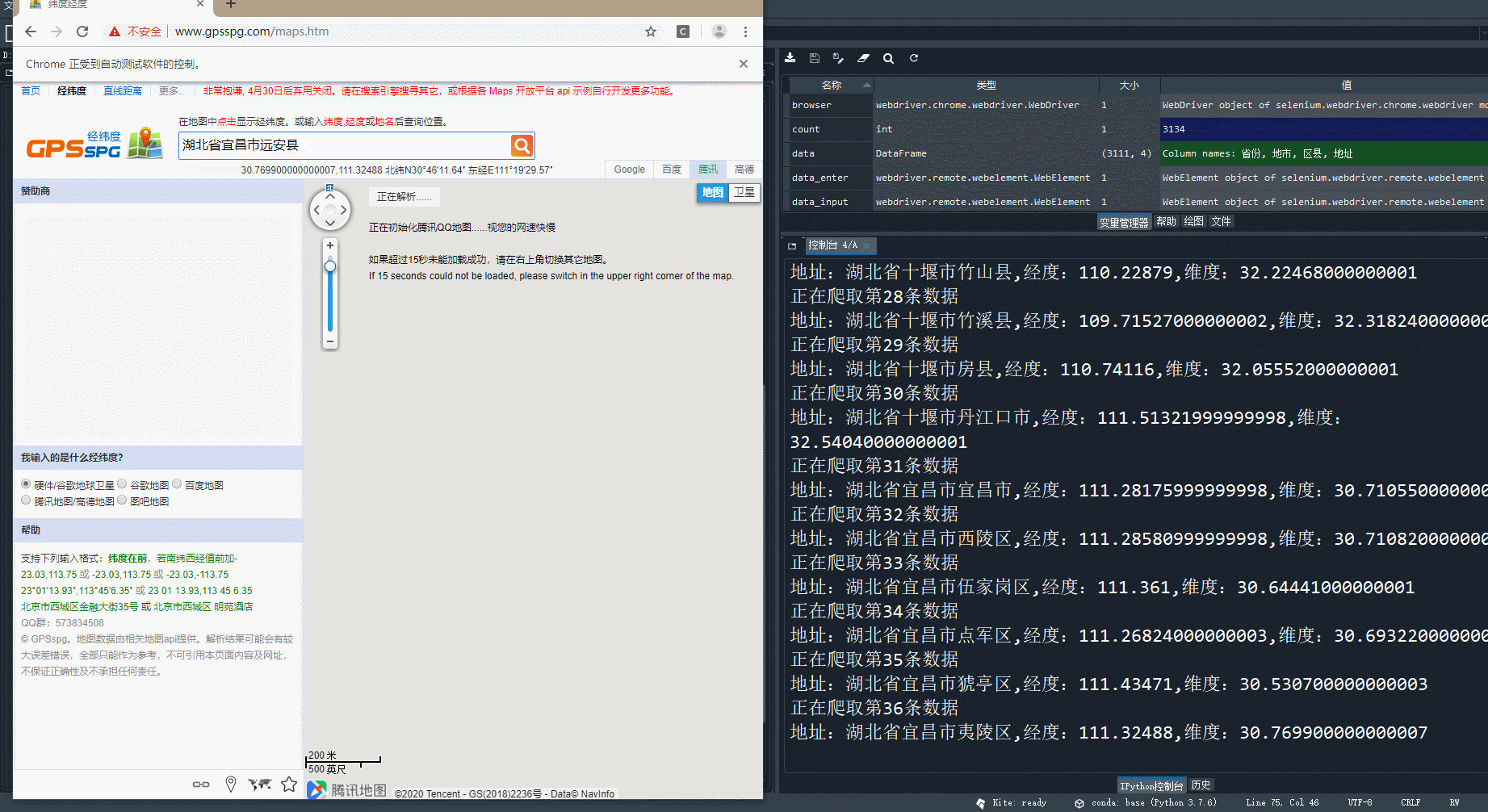
程序执行完成后,会在d盘的Chian文件夹下生成各个省份的经纬度数据的文件,如下:

3.5 多文件数据合并获取全国市区县的经纬度数据
可以加载之前博客中已经封装好的函数,直接调用输入指定的文件读取路径和生成路径即可,代码如下
def excel_concat(dir_path, obtain_path):
'''
Generate a xlsx-file concated by all xlsx-files under the current folder and return its contents
'''
file_paths = glob.glob(dir_path + '/*.xlsx')
#print(file_paths)
df = pd.DataFrame()
i = 1
for file_path in file_paths:
df_ = pd.read_excel(file_path)
df = pd.concat([df,df_])
print(f'Concating {i} file')
i += 1
df.to_excel(os.path.join(obtain_path,'concat_data.xlsx'),index = False)
print('Concated!')
return df
excel_concat('D:/China','D:/China')
→ 输出的结果为:(文件合并,共31个省市区县)

4. 数据库测试
4.1 随机检测数据的选取与字段处理
随机从3100多条数据中抽取20条数据进行地址的经纬度的获取,选取的测试数据是不包含经纬度的数据,仅仅只包含“省份”和“区县”字段.如下。由于全部数据中包含上面了这两个字段,而测试文件也包含了这两个字段,所以为了保证最后返回的excel文件中包含“省份”和“区县”字段的名称,需要把测试文件数据中的相同字段的名称进行修改。
import pandas as pd
data = pd.read_excel('D:/China/concat_data.xlsx',usecols=['省份','区县','经度','纬度'])
data['site'] = data['省份'] + data['区县']
print(len(data))
data_test = data.copy().sample(20)[['省份','区县']]
data_test.columns = ['provice','zone']
data_test['site'] = data_test['provice'] + data_test['zone']
match_data(data_test)
4.2 匹配数据
完善上面的match_data函数功能,主要是使用pd.merge的方法进行数据的匹配,然后获取需求字段的信息,最后把数据存到Excel文件中。
为了减轻内存的负担,不能能每次运行都直接生成文件到本地计算机,因此再设计的时候可以直接通过创建临时文件夹,将生成的文件放在临时文件夹中,然后定义一个邮件发送的函数,把临时文件夹中的excel文件发送到用户的邮箱,这样就完成了数据的获取,而且不再占用本地的内存空间
这里需要使用tempfile和os模块,tempfile用于创建临时文件夹,os负责将程序运行的路径指定到临时文件夹下,然后在发邮件时候进行excel文件的获取,代码如下
from tempfile import TemporaryDirectory
import os
def match_data(data_test):
data_site = pd.merge(data_test,data,on = 'site',how = 'left')
data_site = data_site[['省份','区县','经度','纬度']]
with TemporaryDirectory() as tmp_folder:
print('临时文件夹已创建:{}'.format(tmp_folder))
os.chdir(tmp_folder)
data_site.to_excel('demo.xlsx',index = False)
send_email('demo.xlsx')
4.3 自动发送邮件
上面已经在临时文件中保存了excel文件了,这一步使用yagmail模块进行邮件的发送,关于yagmail如何发送邮件,可以参考每天向邮箱发一份新闻,代码如下。
import yagmail
def send_email(path):
yag = yagmail.SMTP(user = '[email protected]', host = 'smtp.163.com')
contents = [
'很感谢您使用由lys_828用户设计的全国市区县经纬度查询工具\n返回的数据结果见附件。',
path,
]
yag.send('[email protected]','经纬度获取测试邮件',contents)
→ 输出的结果为:(可以看到,在指定邮箱中已经存在我们需要的数据了,而在创建的文件夹中的数据也经销毁了)

5. 程序运行窗口搭建
这里使用python自带的tkinter模块进行简单窗口的搭建,这里选择使用继承式进行窗口的设计,代码如下,
5.1 程序试错
主要有两部分,其中第一部分是完成框体的搭建,第二部分就是设置框体中的内容
from tkinter import * #导入tkinter中所有的方法
from tkinter import filedialog, messagebox #这两个需要单独导入
from tkinter.ttk import Label, Button #导入ttk模块中的指定几个组件
#继承Tk这个类
class Query(Tk):
def __init__(self): #初始化自己的创建的EditorPlus类
super().__init__() #在继承Tk这个类的基础上在自己的类中添加内容
self._set_window_() #设置程序运行主窗口
self._set_content_() #设置框体中的内容
#设置初始化窗口的属性
def _set_window_(self):
self.title("全国市区县经纬度查询工具") #窗口名称
scn_width, scn_height = self.maxsize() #获得程序运行机器的分辨率(屏幕的长和宽)
wm_val = '340x80+{}+{}'.format((scn_width - 400) // 2, (scn_height - 450) // 2)
self.geometry(wm_val) #将窗口设置在屏幕的中间
self.iconbitmap("D:/经纬度查询器/query.ico") #加载一下窗口的左上方显示的图片
self.protocol('WM_DELETE_WINDOW', self.exit_editor) #设置窗口关闭提醒
def exit_editor(self):
if messagebox.askokcancel('退出?','确定退出吗?'): #设置文本提示框
self.destroy() #满足条件的话主窗口退出
def _set_content_(self):
Label(self, text='请输入文件路径',width=15).grid(row=0, column=0) #设置提醒输入路径的标签
self.path = Entry(self,width = 30) #设置路径输入框
self.path.grid(row=0, column=1) #放置位置
Label(self, text='请输入邮箱地址',width=15).grid(row=1, column=0) #设置邮箱输入标签
self.address = Entry(self,width = 30) #设置邮箱地址输入框
self.address.grid(row=1, column=1) ##放置位置
Button(self, text="确定", command=self.onclick).grid(row = 2, column = 0, columnspan = 2) #放置确定按钮
def onclick(self):
path = self.path.get() #获取路径
address = self.address.get() #获取邮箱地址
data_test = pd.read_excel(path) #读取想要查询数据的数据
print(data_test) #这里先进行调试打印输出看一下
if __name__ == '__main__':
app = Query() #类的实例化
app.mainloop()
→ 输出的结果为:(这里测试了输入路径,结果是可以正常读取数据,邮箱这里也是可以正常获取的)

5.2 功能添加
上一步已经根据指定路径完成欲获取市区县经纬度数据文件的读取,这一步只需要将获得的邮箱的值传递到send_email函数中即可,代码如下
import pandas as pd
import yagmail
import os
from tempfile import TemporaryDirectory
def onclick(self):
path = self.path.get()
address = self.address.get()
data_test = pd.read_excel(path)
print(data_test)
data_test.columns = ['provice','zone']
data_test['site'] = data_test['provice'] + data_test['zone']
match_data(data_test,path,address)
def match_data(data_test,path,address):
file_name = os.path.basename(path)
data_site = pd.merge(data_test,data,on = 'site',how = 'left')
data_site = data_site[['省份','区县','经度','纬度']]
with TemporaryDirectory() as tmp_folder:
print('临时文件夹已创建:{}'.format(tmp_folder))
os.chdir(tmp_folder)
data_site.to_excel(file_name,index = False)
send_email(file_name,address)
def send_email(path,address):
yag = yagmail.SMTP(user = '[email protected]', host = 'smtp.163.com')
contents = [
'很感谢您使用由lys_828用户设计的全国市区县经纬度查询工具\n\n\n返回的数据结果见附件。',
path,
]
#print('发送成功')
yag.send(address,'经纬度获取测试邮件',contents)
if __name__ == '__main__':
data = pd.read_excel('D:/China/concat_data.xlsx',usecols=['省份','区县','经度','纬度'])
data['site'] = data['省份'] + data['区县']
→ 输出的结果为:(在输入路径和邮箱地址后,程序会自动向指定邮箱发送已经匹配成功的经纬度的数据文件)
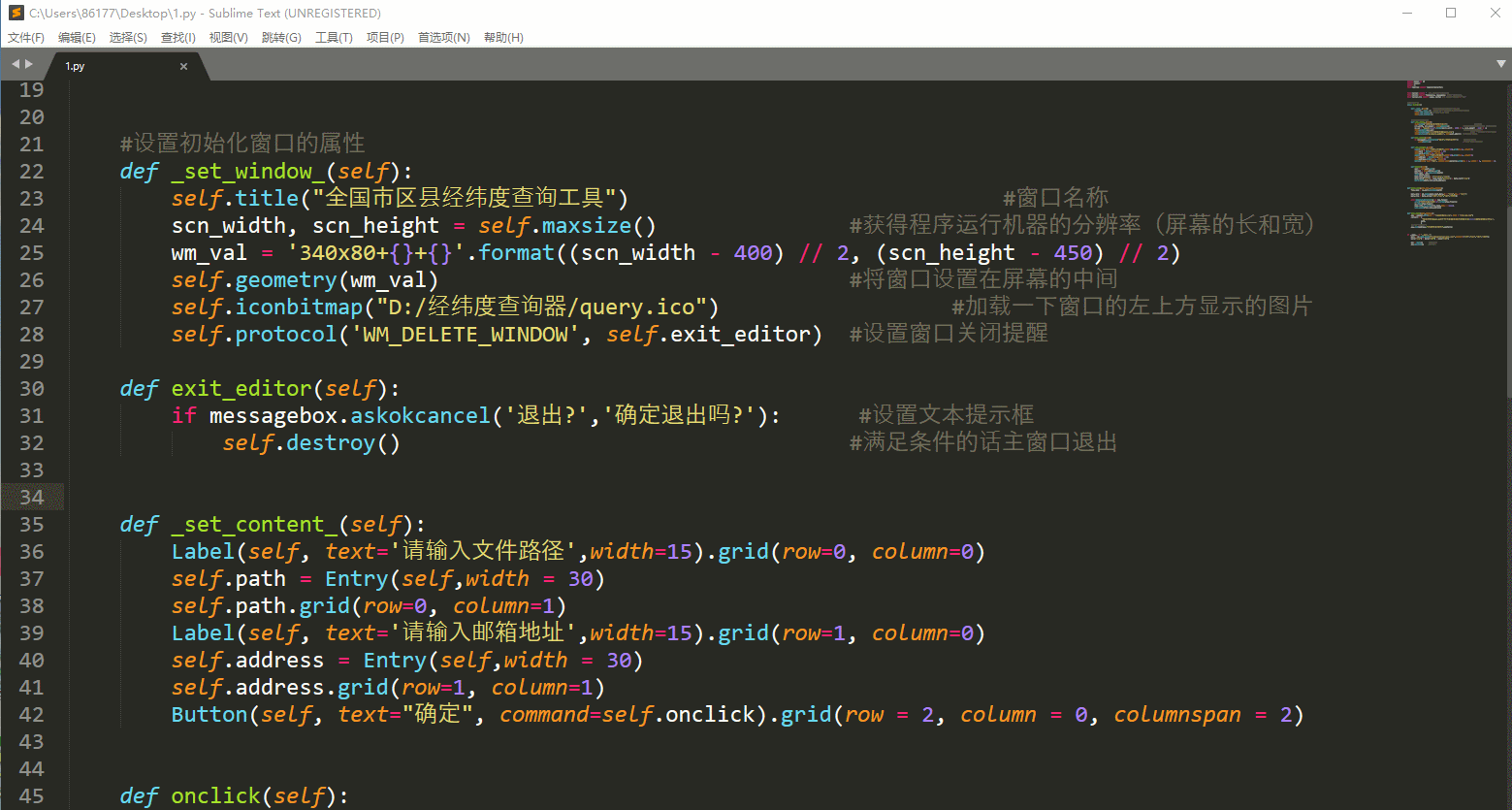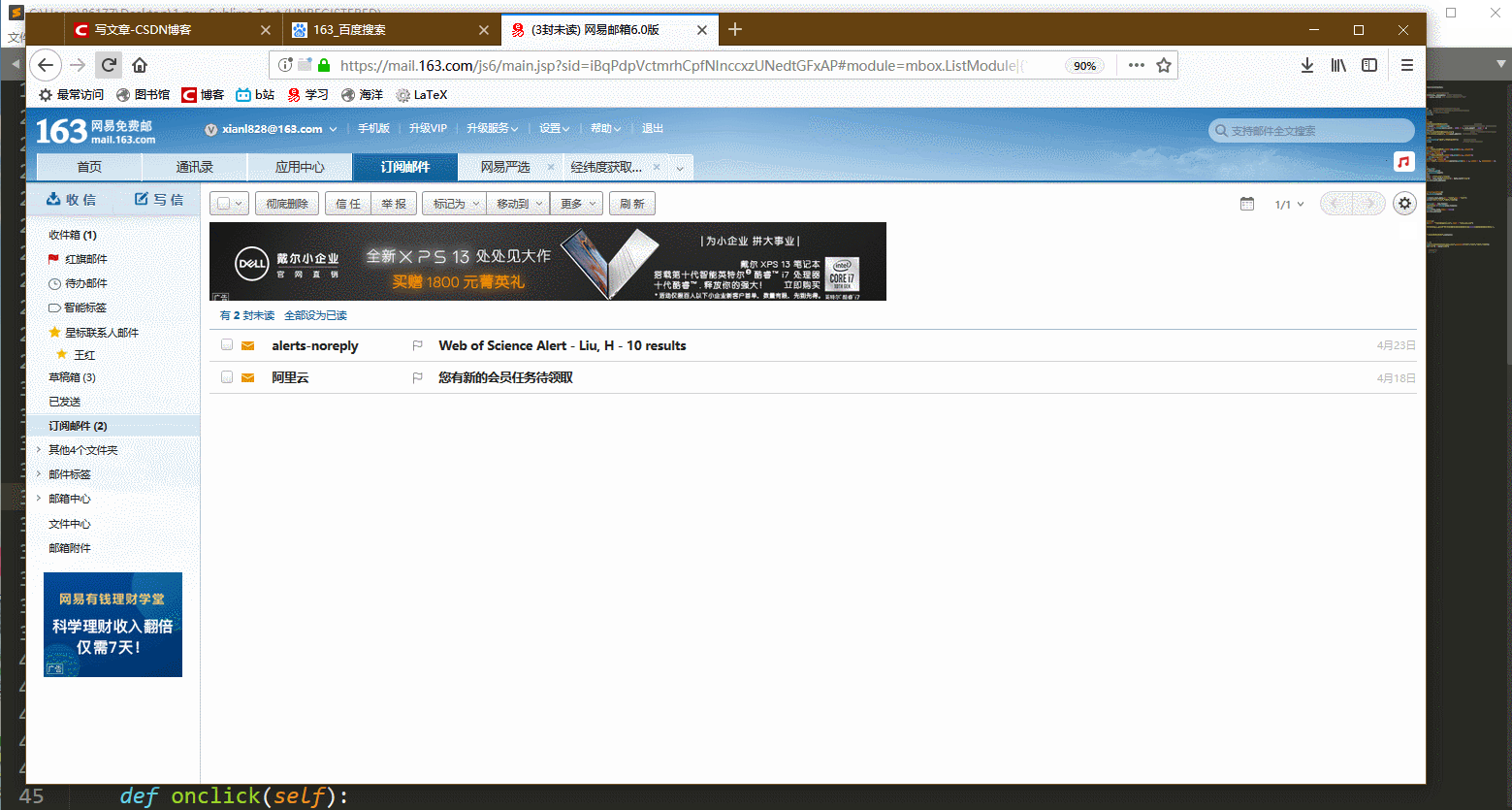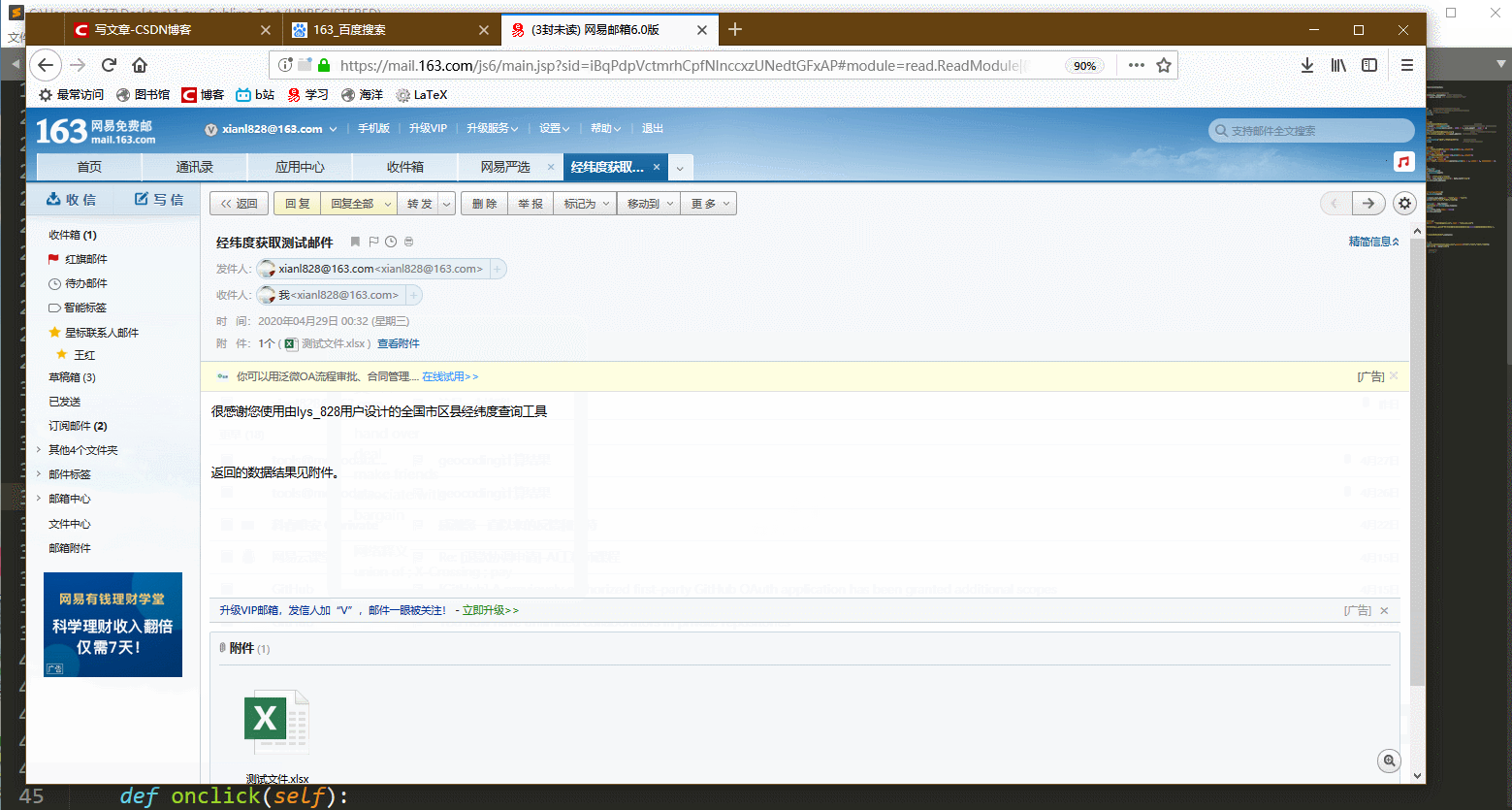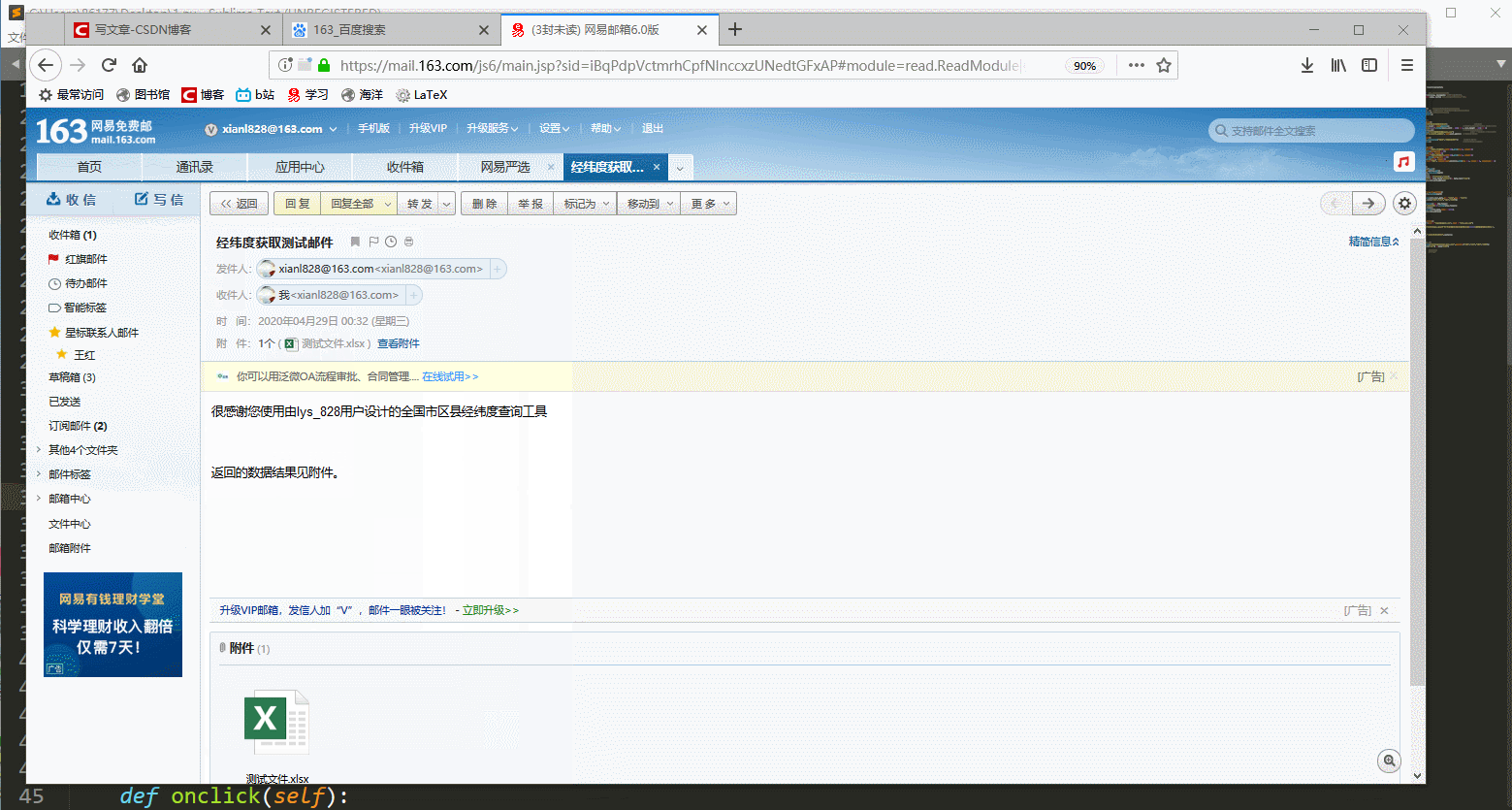
最后返回的邮箱数据预览

6. 尚待完善
1) 在没有添加Tkinter之前,临时文件在程序执行之后就会被清理掉,但是加了之后虽然可以正常的发送邮件,但是临时文件夹(只剩下空文件夹没有被清理),初步猜测是和加载了最后的app.mainloop()有关,暂未想到替代方式
2) 可视化窗口设置较为简陋,这里只是进行尝试的实现功能,后期还需要进一步完善,比如可以设置一个文件路径选择按钮,直接加载文件路径等
3) 代码可能不是很精简,后续还得继续学习…
