1. 获取百度AI接口许可及生成情感倾向分析的url链接
注意要用自己的密匙获取access_token,注意要用自己的密匙获取access_token,注意要用自己的密匙获取access_token!!!
import requests
import json
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
#client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
access_token = response.json()['access_token']
# 按要求写入header参数
headers = {'content-type': 'application/json'}
#生成情感分析的链接
url_sentiment_classify = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=' + access_token
2. 分析文本选择
文章选自鲁迅的短片小说《祝福》
#加载要分析的文本
news = '''参考上面的链接的文章,将原文复制到这里即可'''
#去掉换行符
news = news.replace('\n','')
#统计特定人物的句子数量
xls_sentences = []
for i in news.split('。'):
if '祥林嫂' in i or '她' in i:
#鲁迅在文章中的‘她’指代的也是祥林嫂
xls_sentences.append(i)
print('包含祥林嫂的句子数量:',len(xls_sentences))
xls_sentences[:5]
–> 输出的结果为:
包含祥林嫂的句子数量: 132
['况且,一直到昨天遇见祥林嫂的事,也就使我不能安住',
'那是下午,我到镇的东头访过一个朋友,走出来,就在河边遇见她;而且见她瞪着的眼睛的视线,就知道明明是向我走来的',
'我这回在鲁镇所见的人们中,改变之大,可以说无过于她的了:五年前的花白的头发,即今已经全白,全不像四十上下的人;脸上瘦削不堪,黄中带黑,而且消尽了先前悲哀的神色,仿佛是木刻似的;只有那眼珠间或一轮,还可以表示她是一个活物',
'她一手提着竹篮',
'内中一个破碗,空的;一手拄着一支比她更长的竹竿,下端开了裂:她分明已经纯乎是一个乞丐了']
3. 情感倾向指标计算
1) 少量句子进行试错
① 这里选择第五个句子进行试错分析
xls_sentences[4]
–> 输出的结果为:
'内中一个破碗,空的;一手拄着一支比她更长的竹竿,下端开了裂:她分明已经纯乎是一个乞丐了'
② 测试代码如下:
responsei = requests.post(url_sentiment_classify,
data = json.dumps({'text': xls_sentences[4]}),
headers = headers)
if response:
print(responsei.json()['items'][0])
–> 输出的结果为:(以第五个句子进行举例,发现可以正常输出,而且句子的情感负向指数达到了99.9%,可以说是非常负面的评价了)
{'positive_prob': 0.000266106, 'confidence': 0.999409, 'negative_prob': 0.999734, 'sentiment': 0}
2) 对全部的句子遍历循环
为了保证服务器的正常反馈回来数据,这里建议加上请求暂停时间,如果不加等待时间请求服务器过快,会导致返回数据错误,无法获取其中的内容,这里随机设定为0.5秒
import time
start_time = time.time()
#保存数据,为了数据可视化
xls_data = []
for i in xls_sentences:
try:
# 请求网址然后返回数据
responsei = requests.post(url_sentiment_classify,
data = json.dumps({'text':i}),
headers =headers)
if responsei:
# 如果返回数据了,然后提取相应的字段信息
dic = {'sentence':i,
'positive_prob':responsei.json()['items'][0]['positive_prob'],
'sentiment':responsei.json()['items'][0]['sentiment']}
#print(dic) 数据核实
xls_data.append(dic)
#添加请求暂停时间
time.sleep(0.5)
except:
continue
# 数据转为DataFrame
df_xls = pd.DataFrame(xls_data)
# 计算代码执行时间
end_time = time.time()
print('代码运行时间(s):', end_time - start_time)
print(len(df_xls))
df_xls.head()
–> 输出的结果为:(可以发现当句子的数量较大时候,程序运行的时间也是计较大的)
代码运行时间(s): 125.8831992149353
132
3)前五条数据如下

4. 绘制图表查看关键人的情感倾向指数
1) pyecharts版本使用
这里使用的pyecharts 0.5.11版本进行绘制
import pyecharts as pe
print(pe.__version__)
–> 输出的结果为:
0.5.11
2) 选定绘图数据
由于要绘制双轴图,所以是要有一个x值两个y值
x = df_xls['sentence']
y1 = df_xls['positive_prob']
y2 = df_xls['sentiment']
3) 绘制柱状图和折线图
bar = pe.Bar('祥林嫂 情感倾向')
bar.add('情感倾向指数', x, y1,
is_datazoom_show = True, datazoom_range = [0,100],
mark_line=[ "average"],
tooltip_axispointer_type = 'cross')
# 绘制折线图
line = pe.Line('祥林嫂 情感倾向')
line.add('情感倾向分类', x, y2, is_step=True, area_opacity = 0.2)
4) 两图合并
# 合并图表
overlap = pe.Overlap()
overlap.add(bar)
overlap.add(line,
yaxis_index=1, is_add_yaxis=True) # 新增y轴
overlap #jupyter notebook支持直接出图
–> 输出的结果为:(可以点击右侧的保存按钮将某一刻的图形进行保存)
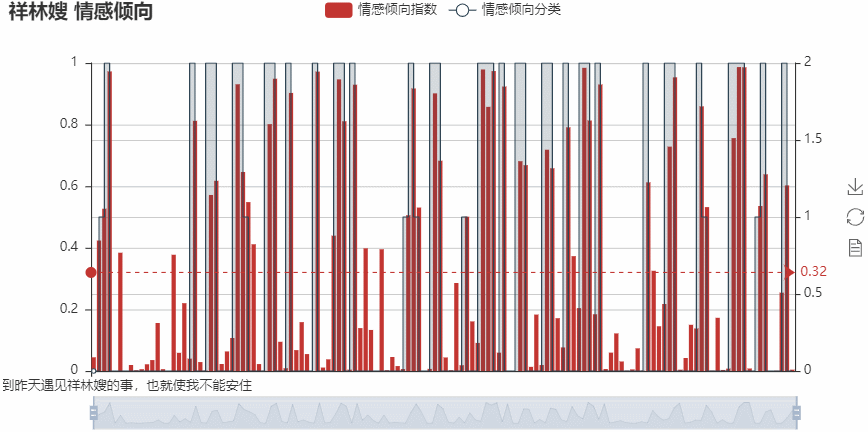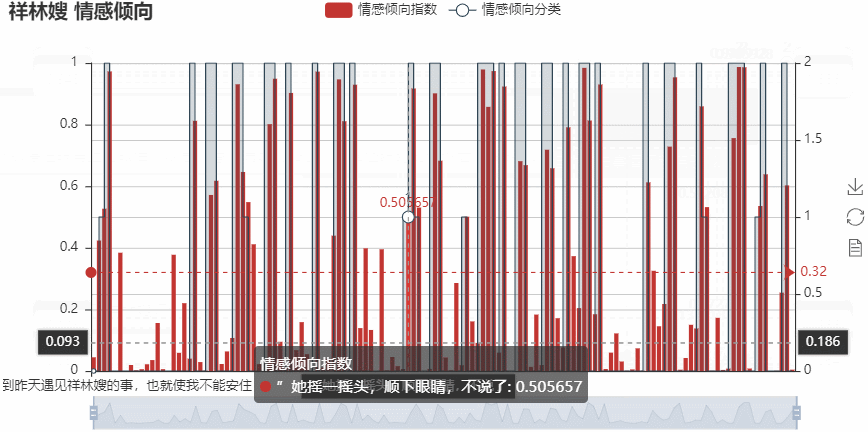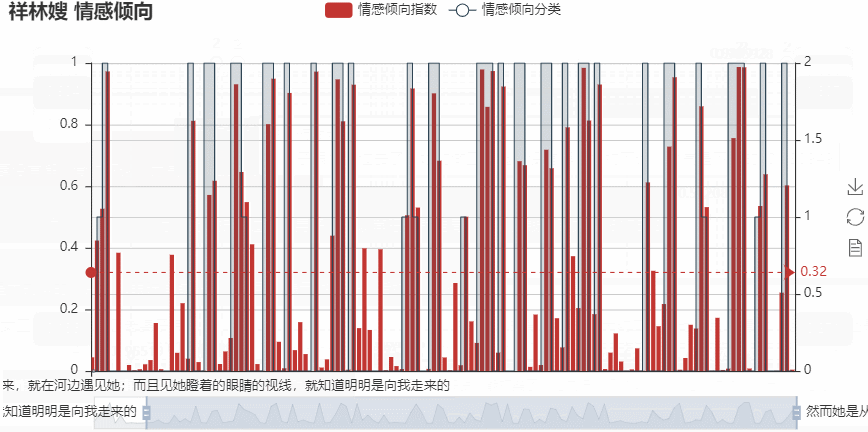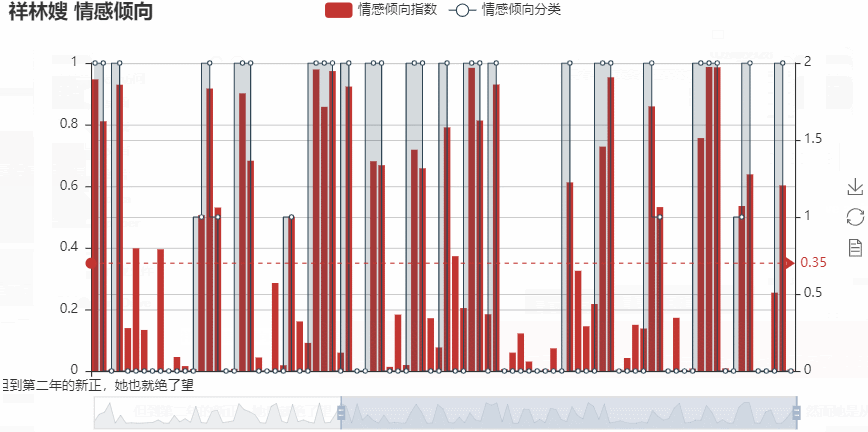
基于关键人物的句子筛选,绘图分析后,可以更直观看到对于祥林嫂的情感倾向指数,其平均值为0.32,偏负向!
5. 构建函数,提取任意关键词做情感指数分析
为了方便日后的工作调用采用的是函数封装,这里的封装就直接粗暴,保证函数直接调用就可以出图,并输出包含关键词的个数和成功提取关键词的个数,以及运行的时间(测试发现0.3秒系统提取的成功率已经很高了,如果追求完美的话这个请求等待时间可以继续上调,但是会影响程序的运行时间)函数步骤拆解如下:
1) 导入相关的库
import requests,json,time
import pandas as pd
import pyecharts as pe
2)文章的划分
这里考虑文章种是否有同义词,如果有的话可以使用字符串的replace方法,比如刚刚使用了or的逻辑判断,其实可以直接将这两个数据合并,如下
news = news.replace('她','祥林嫂')
下面代码完成的是对输入文章内容中的句子进行划分。注意是已经处理完毕后的数据,可以直接拿过来用的,代码执行后会打印输出包含关键词句子的数量。
slst = []
for i in news.split('。'):
if words in i:
slst.append(i)
print('关键词句子数量:',len(slst))
3) 获取许可的access_token
注意是要输入自己创建应用后的秘钥并获得许可的access_token
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=PRlycW9Fkfgm7moLA6uLeW&client_secret=GGF88lVjTnLHbIYjPzfla1bhtTy3kE'
response = requests.get(host)
if response:
access_token = response.json()['access_token']
4) 进行数据请求并返回结果
这一部分就是项目核心:获取情感倾向指标数据,请求等待时间可以根据自己的需求进行设置
# 按要求写入header参数
headers = {'content-type': 'application/json'}
url_sentiment_classify = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=' + access_token
# 计算情感倾向指标
datai = []
# for循环遍历
for i in slst:
try:
responsei = requests.post(url_sentiment_classify,
data = json.dumps({'text': i}),
headers = headers)
if response:
# 创建字典存储情感倾向分析结果
sen_dici = {'sentence':i,
'positive_prob':responsei.json()['items'][0]['positive_prob'],
'sentiment':responsei.json()['items'][0]['sentiment']}
datai.append(sen_dici) # 将结果存入列表
time.sleep(0.3)
except:
continue
5) 可视化输出数据
这里可以生成一个可视化数据的接口,最后函数的返回值中,第一个是绘制的图形的对象,第二个就是成功提取情感倾向指标数据的对象
dfi = pd.DataFrame(datai)
print('成功提取包含{}的句子数量:{}'.format(words,len(dfi)))
6) 出图
# 绘制交互图表做可视化表达
# 设置x、y轴
x = dfi['sentence']
y1 = dfi['positive_prob']
y2 = dfi['sentiment']
# 绘制柱状图
bar = pe.Bar(words + '情感倾向')
bar.add('情感倾向指数', x, y1,
is_datazoom_show = True, datazoom_range = [0,100],
mark_line=[ "average"],
tooltip_axispointer_type = 'cross')
# 绘制折线图
line = pe.Line(words + '情感倾向')
line.add('情感倾向分类', x, y2, is_step=True, area_opacity = 0.2)
# 合并图表
overlap = pe.Overlap()
overlap.add(bar)
overlap.add(line,
yaxis_index=1, is_add_yaxis=True) # 新增y轴
# 计算代码执行时间
end_time = time.time()
print('代码运行时间(s):', end_time - start_time)
6. 全部代码
def keywords_sentiment_analysis(news,words):
#第一部分:导入相关的库
import requests
import json
import time
import pyecharts as pe
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
#开始计时
start_time = time.time()
# 提取关键词所有句子
slst = []
for i in news.split('。'):
if words in i:
slst.append(i)
print('关键词句子数量:',len(slst))
#client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
if response:
access_token = response.json()['access_token']
# 按要求写入header参数
headers = {'content-type': 'application/json'}
url_sentiment_classify = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=' + access_token
# 计算情感倾向指标
datai = []
# for循环遍历
for i in slst:
try:
responsei = requests.post(url_sentiment_classify,
data = json.dumps({'text': i}),
headers = headers)
if response:
# 创建字典存储情感倾向分析结果
sen_dici = {'sentence':i,
'positive_prob':responsei.json()['items'][0]['positive_prob'],
'sentiment':responsei.json()['items'][0]['sentiment']}
datai.append(sen_dici) # 将结果存入列表
time.sleep(0.3)
except:
continue
# 数据转为DataFrame
dfi = pd.DataFrame(datai)
print('成功提取包含{}的句子数量:{}'.format(words,len(dfi)))
# 绘制交互图表做可视化表达
# 设置x、y轴
x = dfi['sentence']
y1 = dfi['positive_prob']
y2 = dfi['sentiment']
# 绘制柱状图
bar = pe.Bar(words + '情感倾向')
bar.add('情感倾向指数', x, y1,
is_datazoom_show = True, datazoom_range = [0,100],
mark_line=[ "average"],
tooltip_axispointer_type = 'cross')
# 绘制折线图
line = pe.Line(words + '情感倾向')
line.add('情感倾向分类', x, y2, is_step=True, area_opacity = 0.2)
# 合并图表
overlap = pe.Overlap()
overlap.add(bar)
overlap.add(line,
yaxis_index=1, is_add_yaxis=True) # 新增y轴
# 计算代码执行时间
end_time = time.time()
print('代码运行时间(s):', end_time - start_time)
# 返回绘图对象和可视化数据对象
return overlap,dfi
7. 演示示例
直接调用函数,返回一个绘图的对象和一个是可视化数据的对象
fig,df = keywords_sentiment_analysis(news,'祥林嫂')
–> 输出的结果为:(news输入前,已经将’她’合并到’祥林嫂’里面了,可以看出请求时间暂停为0.3秒时候满足精度的要求)
关键词句子数量: 132
成功提取包含祥林嫂的句子数量:132
代码运行时间(s): 114.1103241443634
1) 绘制图形
fig #在jupyter notebook上面直接输入这个对象参数,运行就会输出结果
–> 输出的结果为:

2) 可视化数据
df.iloc[20:30]
–> 输出的结果为:(比如这里查看中间的数据)

