引言
本文是接上一篇李宏毅机器学习——循环神经网络(一)
Learning Target
在RNN中如何定义损失函数呢。还是以Slot Filling为例,给定一些句子作为训练数据
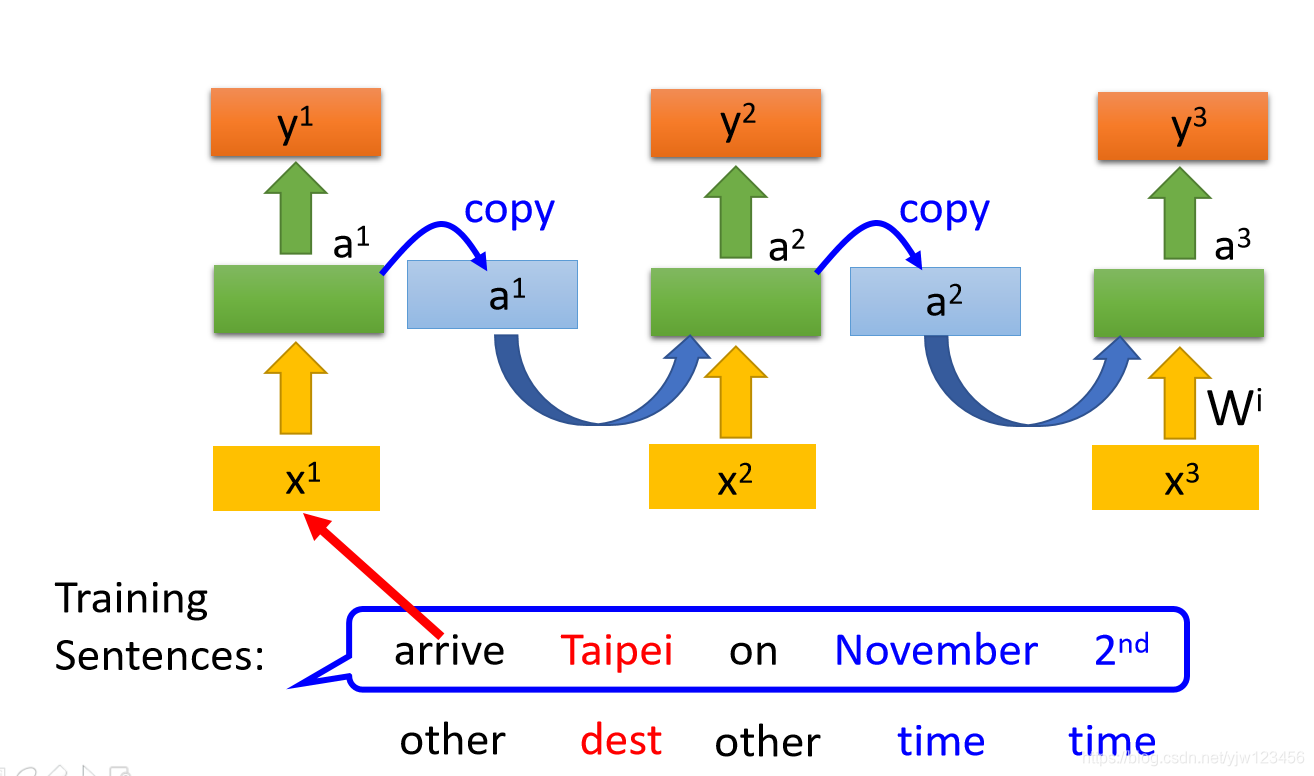
并且要给这些句子一些标签,告诉机器第一单词arrive属于other这个slot,Taipei属于dest这个slot等。
此时要怎么定义损失函数呢,比如把arrive丢到RNN中后,可以得到一个输出 ,接下来这个 要和参考向量计算交叉熵。

再把Taipei丢到RNN中取希望得到的
与这个参考向量计算交叉熵,越小越好。这里注意是有顺序的,在把Taipei丢进去之前,一定要先丢arrive。
Learing(训练)
现在有了损失函数后,如果做训练呢,还是用梯度下降。
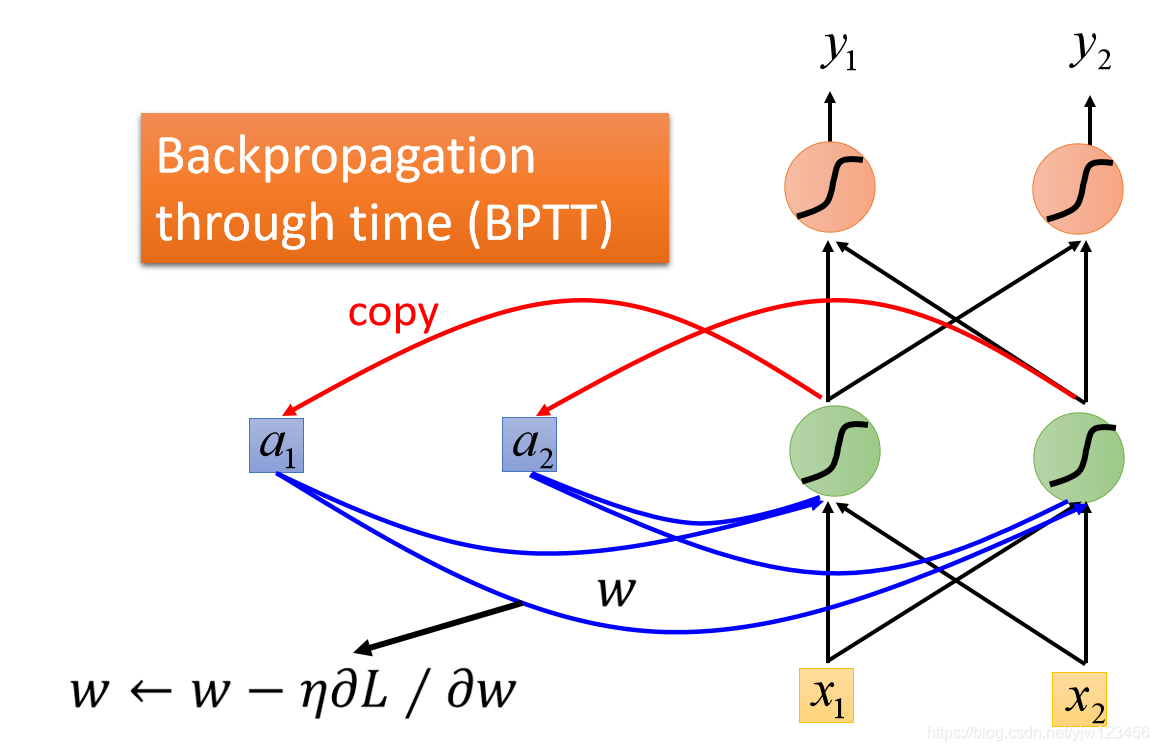
还是计算
对
的偏微分,用梯度下降的方法更新参数。在NN中我们用反向传播算法来更新参数,而在RNN中,需要使用反向传播算法的升级版——基于时间的反向传播算法(BPTT)。这里不细讲BPTT了。
不幸的是,RNN的训练是比较困难的。
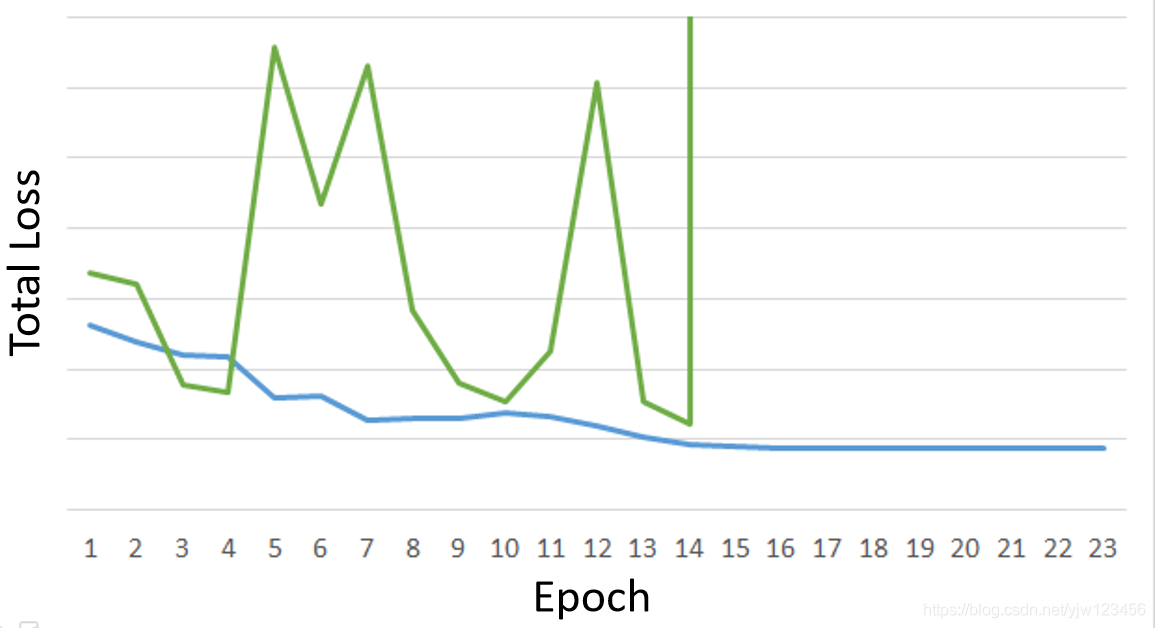
一般来说,在做训练的时候,希望学习曲线是蓝色的这条线。但是在训练RNN的时候,可能会看到绿色的这条线。
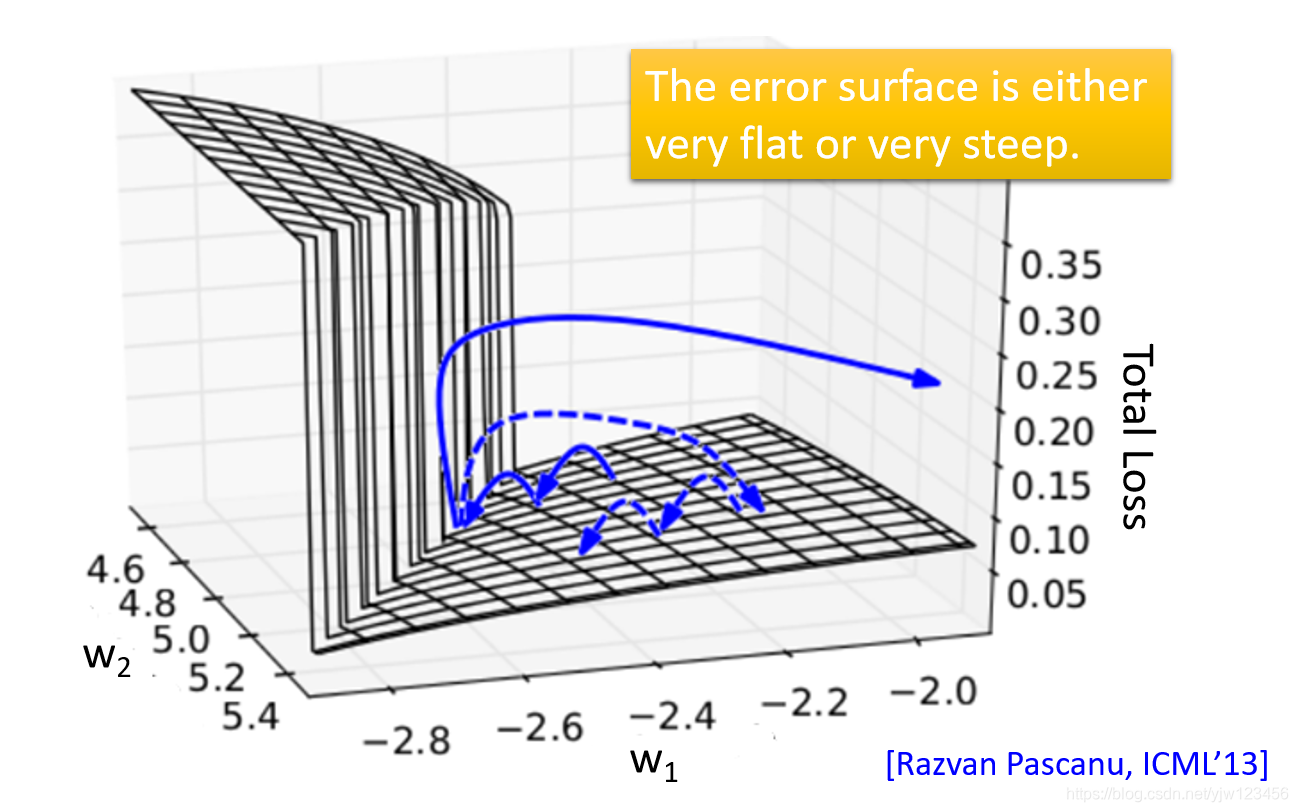
为什么会这样呢,因为误差曲面要么非常陡峭,要么非常平缓。平缓的时候学习的非常慢,此时你尝试增大学习率,结果又遇到了陡峭的曲面,然后整个损失会急剧上升。
那么怎么办呢,RNN的提出者就想了一招,叫Clipping(修建),当梯度大于某个阈值的时候,就把梯度取那个阈值,通常阈值取15。
那为什么误差曲面是这样呢。
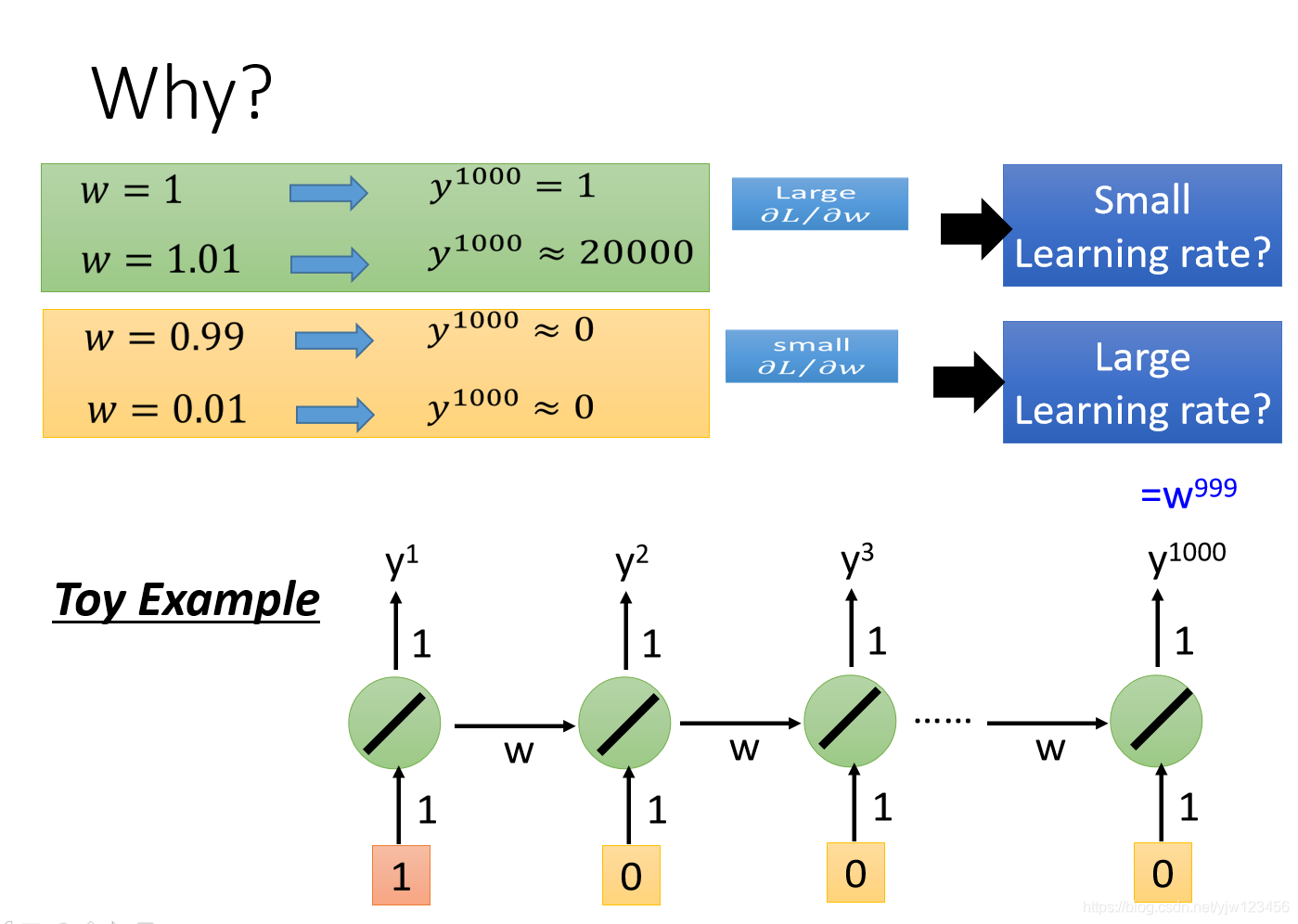
这里以一个简单的RNN为例,它只有一个线性的神经元。假设这个网络的输入是
。那么在第1000个时间点的输出就是
。
然后我们尝试改变 的值,变动 ,如果我们增大 ,那么最终会得到的输出是20000(这时可能需要一个很小的学习率),也就是20000倍! 反之如果减少,最终得到的值为 (此时又需要很大的学习率)。
因为从内存接到神经元的那一组权重是反复被使用的(比如这里被使用了1000次), 造成的变换一旦有影响,那么影响是巨大的。
那有什么样的技巧可以帮助我们解决这个问题呢,现在常用的就是LSTM。它能让你的误差曲面不那么崎岖,能解决梯度消失的问题,但是不能解决梯度爆炸的问题。
所以你可以把学习率设得小一点。
这也是为什么常用LSTM而不是RNN的原因。
为什么LSTM能处理梯度消失的问题呢,RNN和LSTM在处理内存的方式是不一样的。在RNN中,每个时间点,内存中的数据都会被覆盖掉。
但在LSTM中是把原来内存中的值乘上一个值,再加上输入的值,最后再覆盖。
如果权重可以影响到内存中的值,一旦发生影响,那么这个影响会一直存在(除非被遗忘门忘掉),不像RNN在每个时间点会被覆盖掉。
现在比较流行的一种RNN是GRU(Gated Recurrent Unit),它比LSTM要简单,只有两个门,更新门和重置门。所以它需要的参数量比较少,也就是模型更新简单,不容易过拟合。
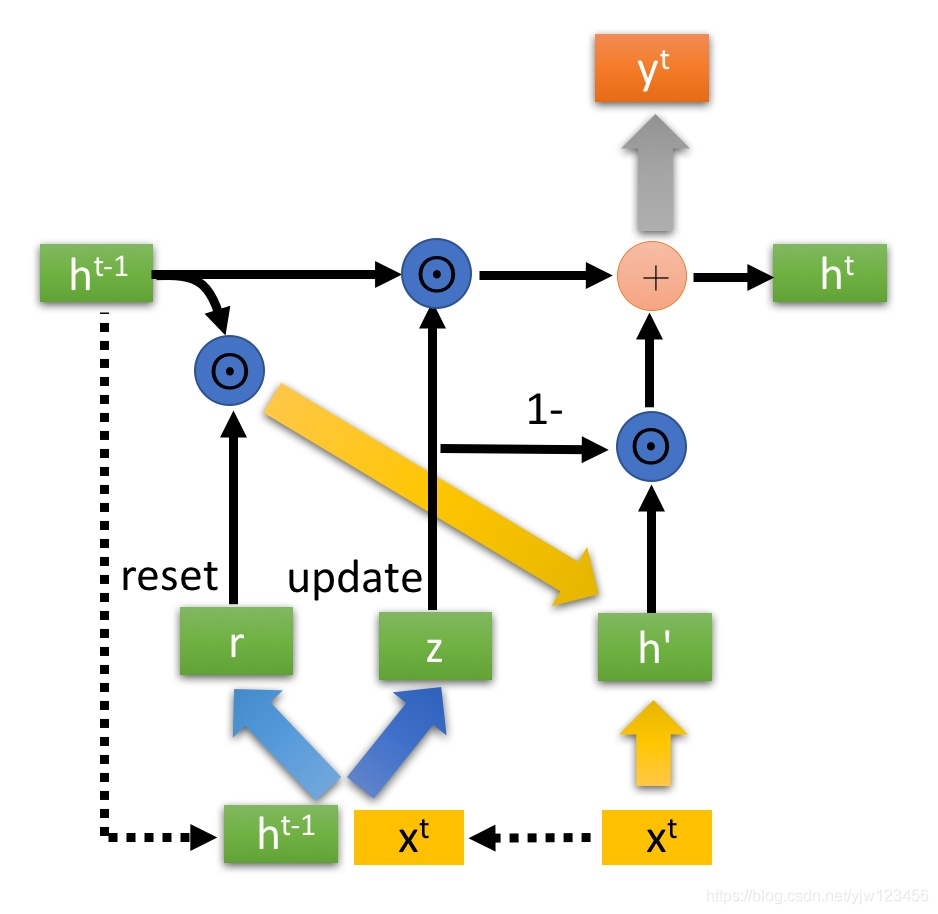
GRU需要把存在内存中的值洗掉,才可以存入新的值。
更多的应用
其实RNN除了填槽,还有很多应用。
在上面填槽的时候,我们假设输入和输出的序列是一样长的。实际上RNN还可以做更复杂的事情。
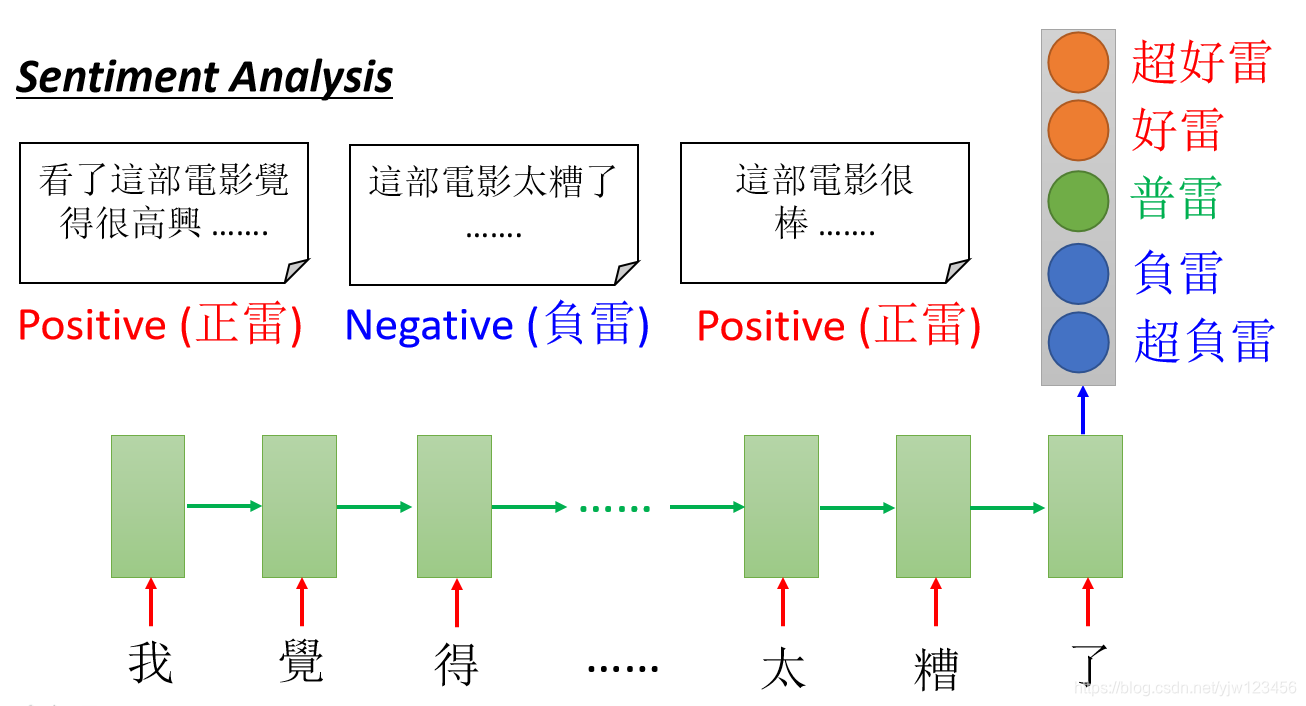
比如输入是一个向量序列,但输出可以只是一个向量,常用的场景就是情感分析(sentiment analysis)。

比如分析电影的评价。
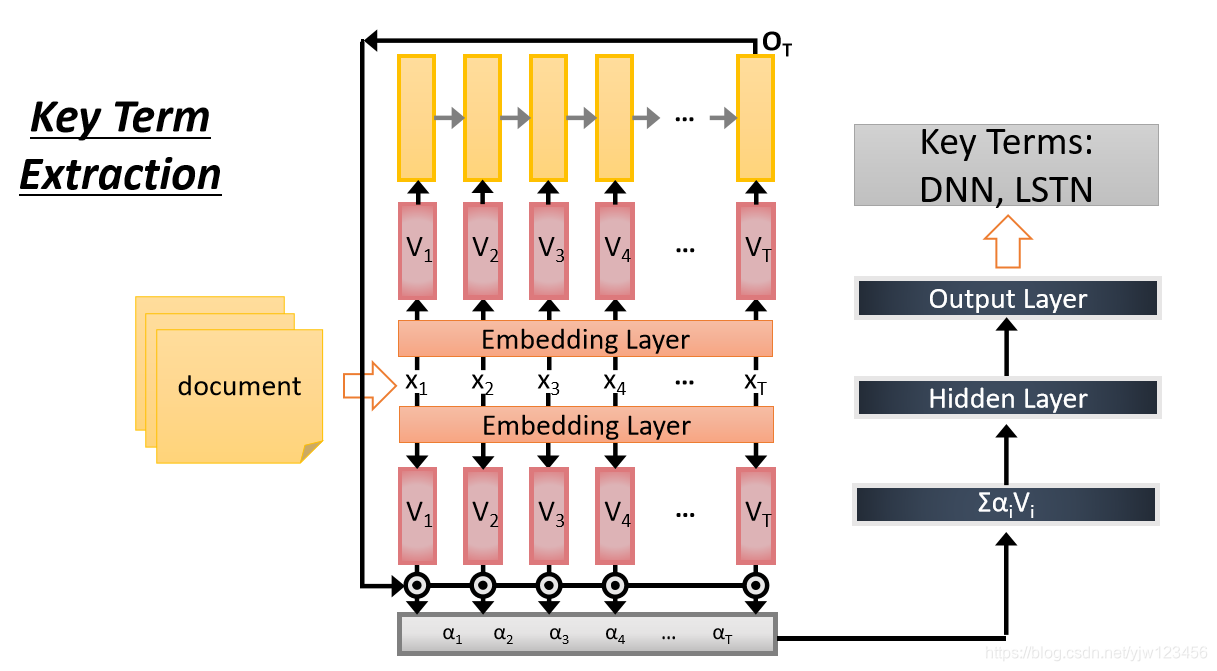
还可以做关键字抽取。
上面都是多(个向量)对一(个向量)的情况,还可以做多对多,不过输出的多个向量要比输入的要短。
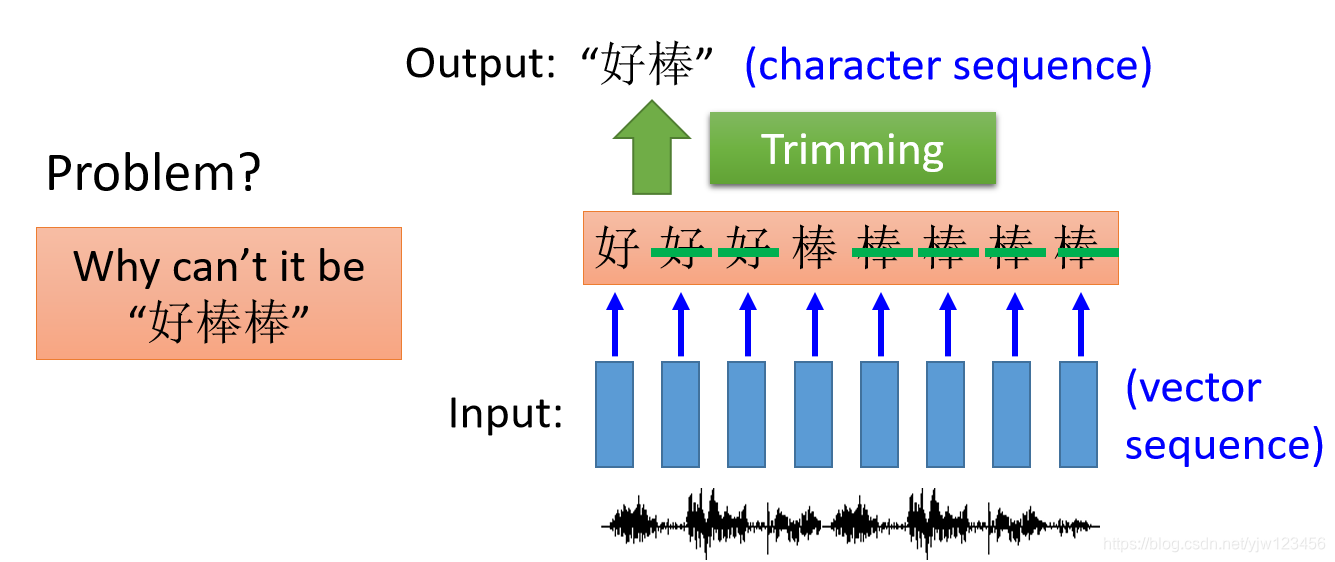
比如在语音识别中,每隔一小段时间就用一个向量来表示,这一小段时间可以是0.01秒,输出就是字符串。
如果我们用做填槽的那个RNN来做语音识别的话,它最多就输出每个向量对应的字符。
因为这一小段时间很短,哪怕你讲话讲得再快,一个字也会对应多个时间段,也就会有多个向量。比如这里输出是“好好好棒棒棒棒棒”。
可以通过Trimming拿掉重复的字符,但这样会有一个问题,可能真正对应的字符串是“好棒棒”。
Connectionist Temporal Classification (CTC) [Alex Graves, ICML’06][Alex Graves, ICML’14][Haşim Sak, Interspeech’15][Jie Li, Interspeech’15][Andrew Senior, ASRU’15]
怎么办呢,可以用CTC,主要思想就是在输出的时候,除了输出中文字符,还可以输出一个代表没有任何东西null的符号
。
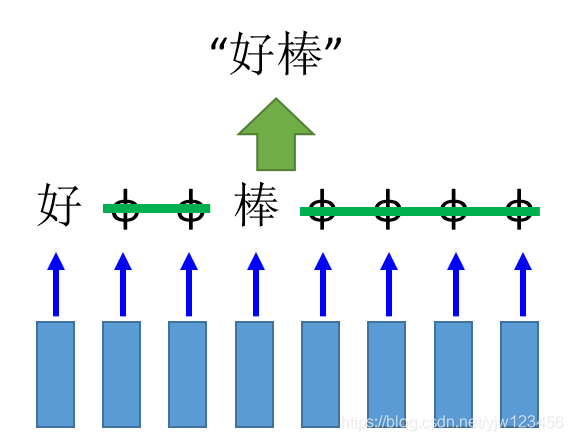
如果我们的输出是这样的,就可以把
拿掉,得到输出“好棒”。
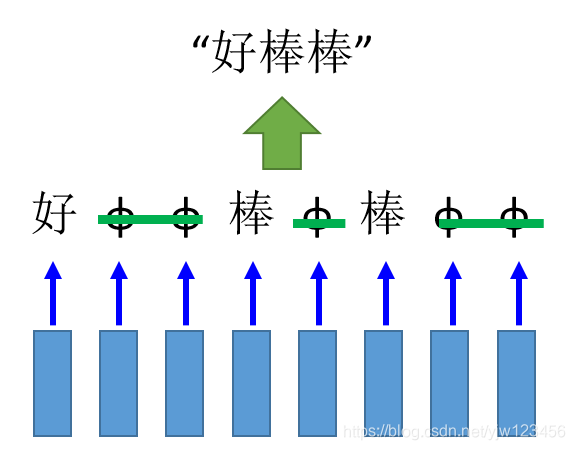
或者这样可以得到“好棒棒”。
CTC在做训练的时候,只给定声音特征(Acoustic Features)和最终的标签(好棒)。

但不会给定“好”、“棒”以及
分别对应哪几个向量,此时需要穷举所有可能的排列。
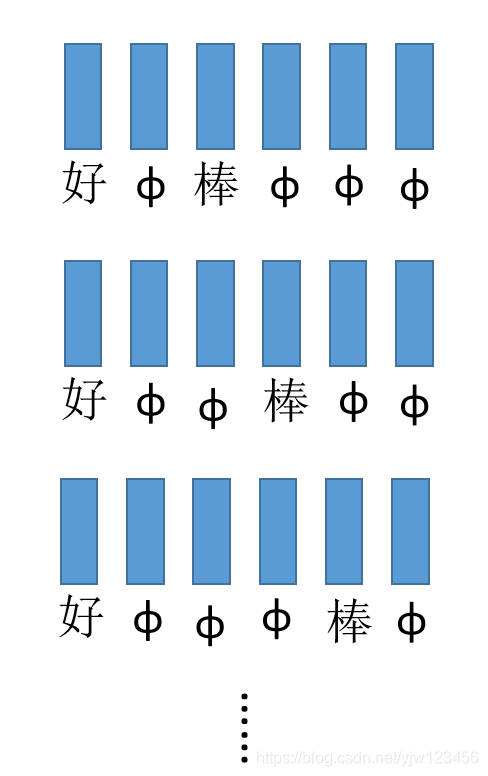
然后我们不知道哪个是对的,只好假设每个都是对的,在训练的时候全部都当成是正确的进行训练。
下面是文献得到的结果:
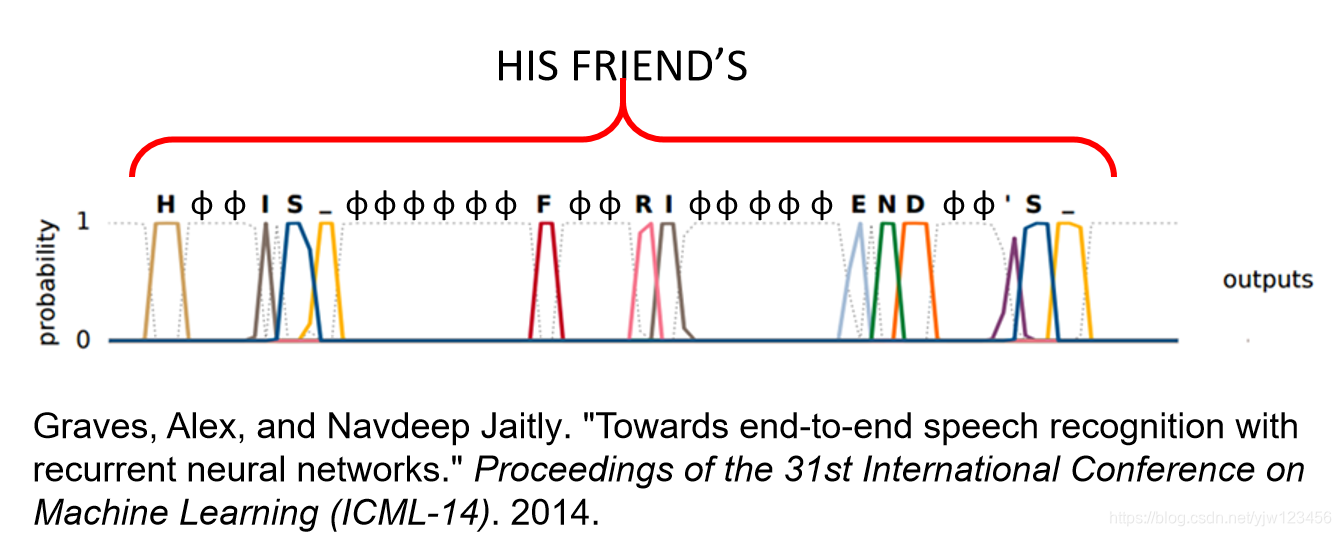
Graves, Alex, and Navdeep Jaitly. “Towards end-to-end speech recognition with recurrent neural networks.” Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014.
另一个神奇的应用是机器翻译,此时输入和输出都是序列,但不确定输入和输出哪个比较长。
[Ilya Sutskever, NIPS’14][Dzmitry Bahdanau, arXiv’15]
除了都是输出序列外,还可以进行句法分析。
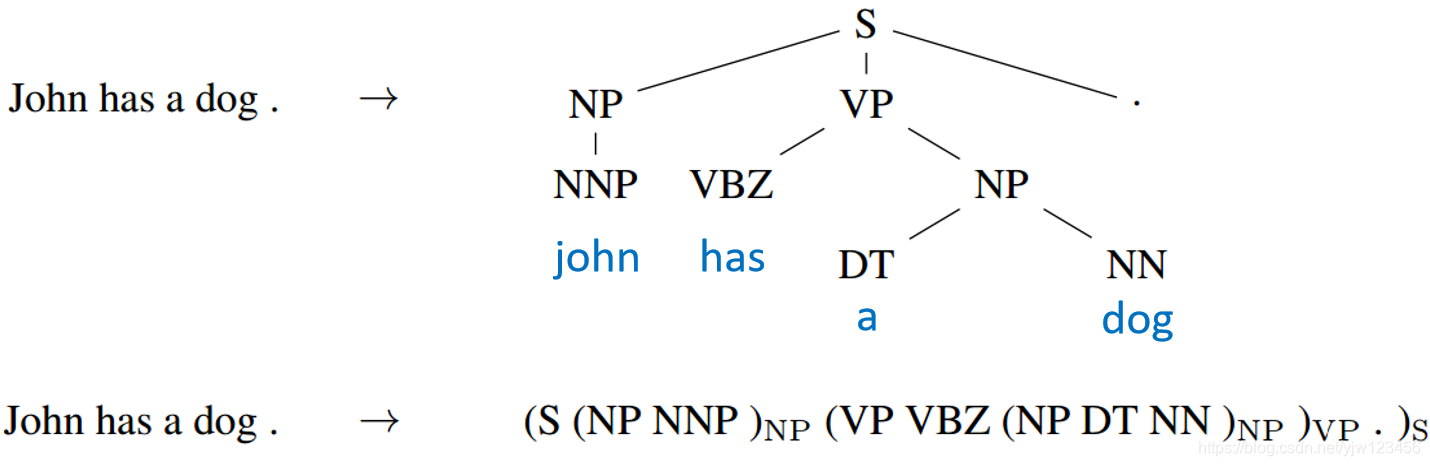
Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, Geoffrey Hinton, Grammar as a Foreign Language, NIPS 2015
Seq2Seq Auto-encoder
文本
我们之前讲过把一个文档表示成向量的话, 往往会用词袋法,但是这种方法会忽略掉单词之前的顺序信息。

比如上面两句话white blood cells destroying an infection(白细胞杀死细菌),和an infection destroying white blood cells(细菌杀死白细胞)。它们里面的词汇是一样的,但是因为顺序不同,表示的意思完全相反。
如果我们用Seq2Seq Auto-encoder这种做法,来考虑序列顺序的情况下,把一个文档变成一个向量。
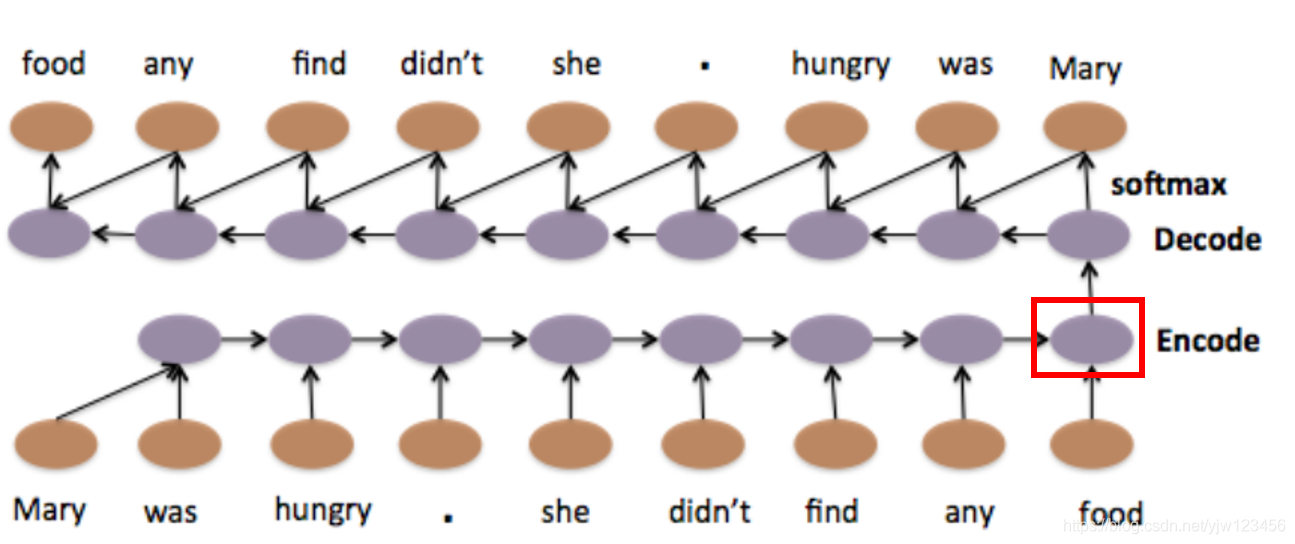
Li, Jiwei, Minh-Thang Luong, and Dan Jurafsky. “A hierarchical neural autoencoder for paragraphs and documents.” arXiv preprint arXiv:1506.01057(2015).
输入一个单词序列“Mary was hungy.she didn’t find any food”,通过一个RNN把它变成一个词嵌入向量,再把这个词嵌入向量当做Decode的输入,然后让这个Decode输出一模一样的句子(倒序)。
那编码的向量代表这个输入序列的重要信息,我们就可以通过这个Encoded 向量来让这个Decode把这个序列解码回来。
语音
Seq2Seq auto-encoder还可以用在语音上。
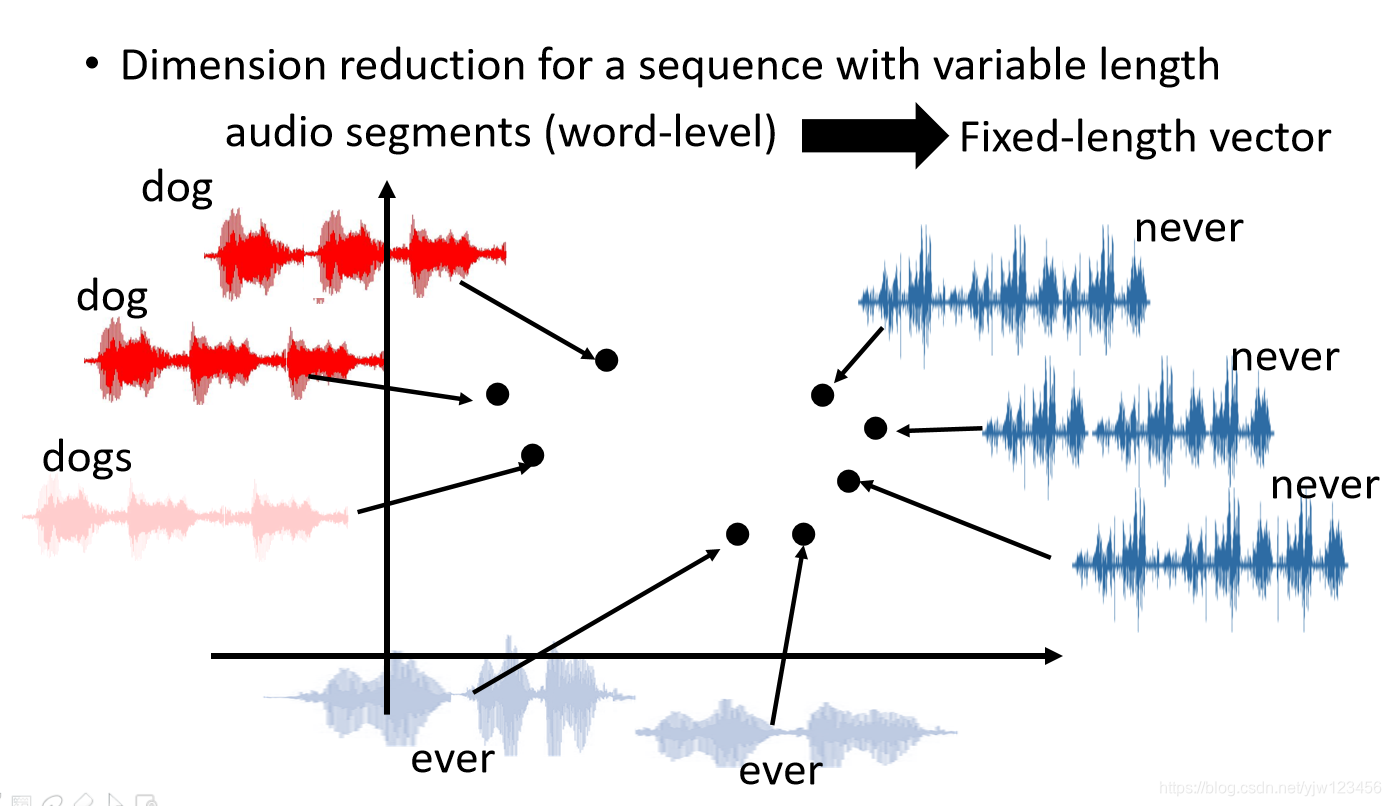
可以给变长的语音序列降维,将一段声音讯号变成固定长度的向量。
比如不同的描述dog的语音经过降维变成向量后,它们分布的距离是比较接近的。
Yu-An Chung, Chao-Chung Wu, Chia-Hao Shen,
Hung-Yi Lee, Lin-Shan Lee, Audio Word2Vec: Unsupervised Learning of Audio Segment Representations using Sequence-to-sequence Autoencoder, Interspeech 2016
那这种技术有什么用呢,还是有很多用的,比如可以用来进行语音搜索。
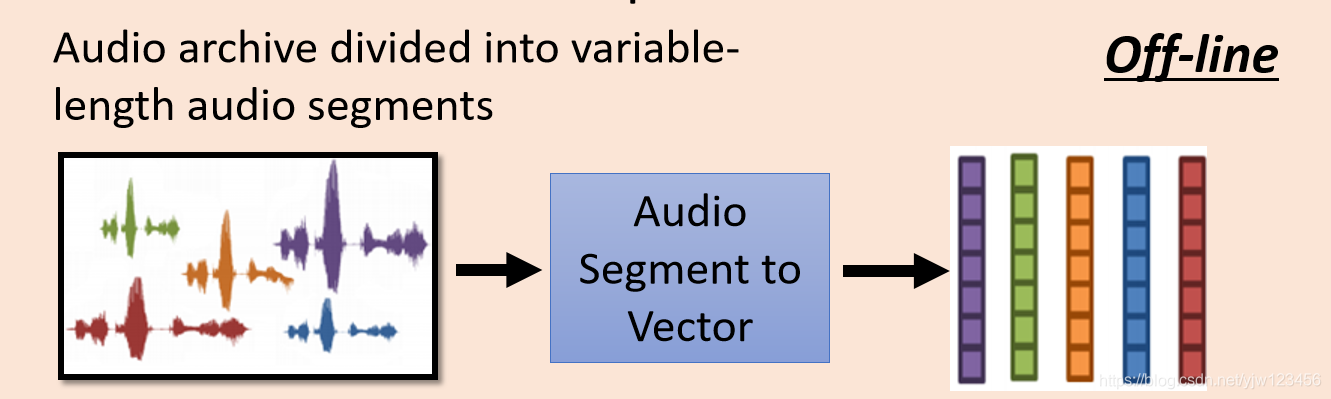
那么要怎么做呢,先把输入的声音讯号变成一段一段的,然后用上面介绍的技术把它们变成向量。
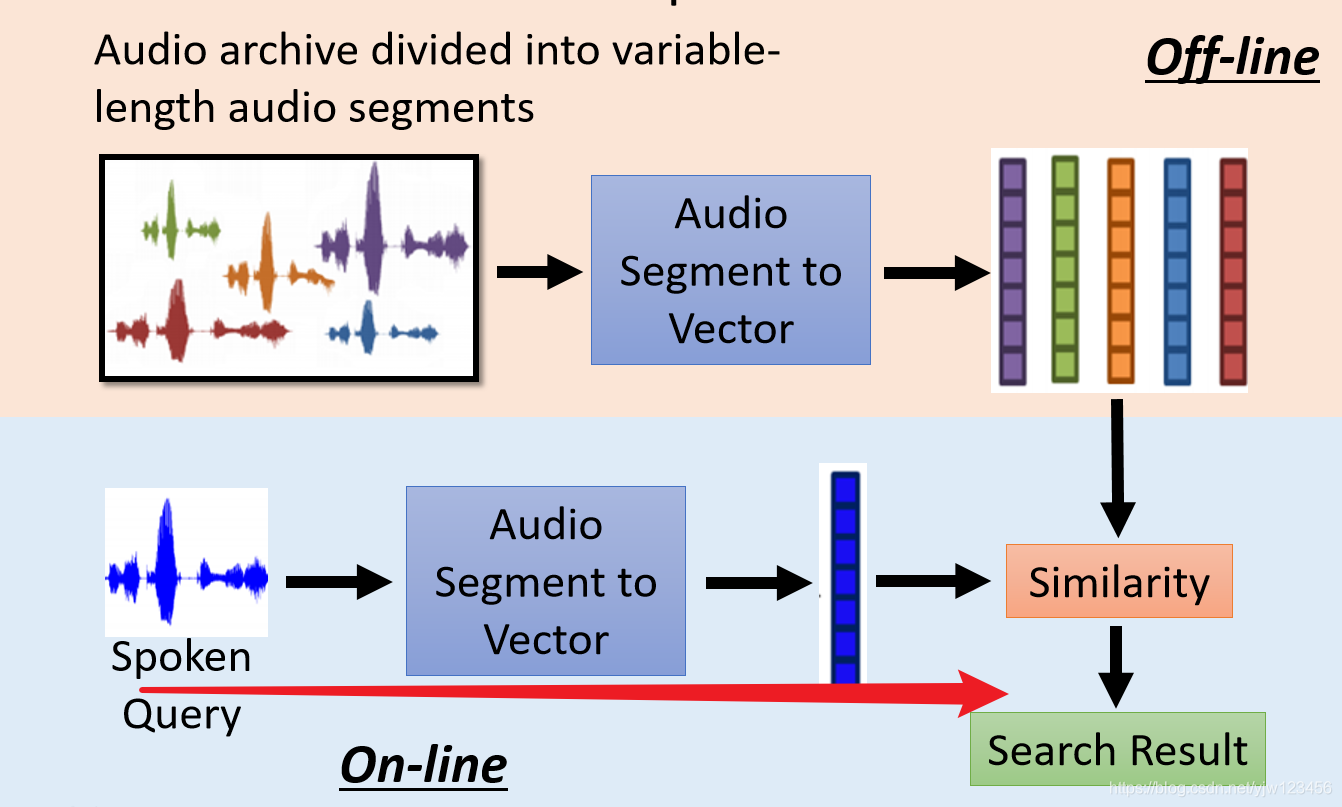
然后来一个人,讲一段语音,也把它变成向量,接下来计算这个向量与库里面向量的相似度,就可以得到搜索结果了。
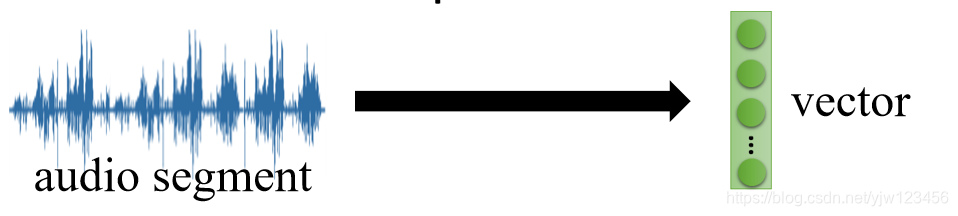
那怎么把声音讯号变成一个向量呢?
先把声音讯号抽成声学特征段(acoustic features segment),然后丢到RNN中去,这个RNN起到Encoder的作用。
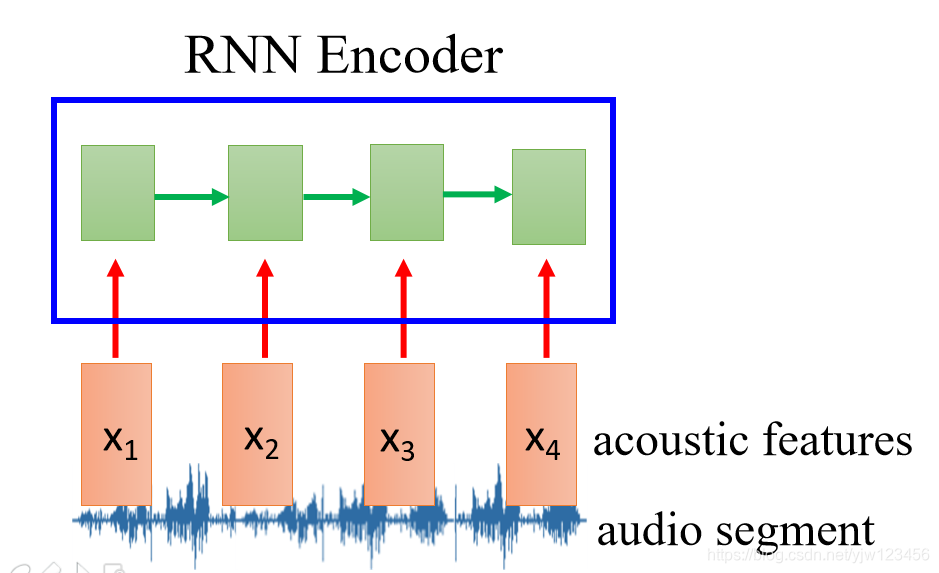
在RNN读过这个声学特征段后,它最后时间点存在内存中的值就成代表整个声音讯号,存在内存中的值是个向量,而这个向量就是我们想要的,这样就把一段声音讯号转换为一个向量。
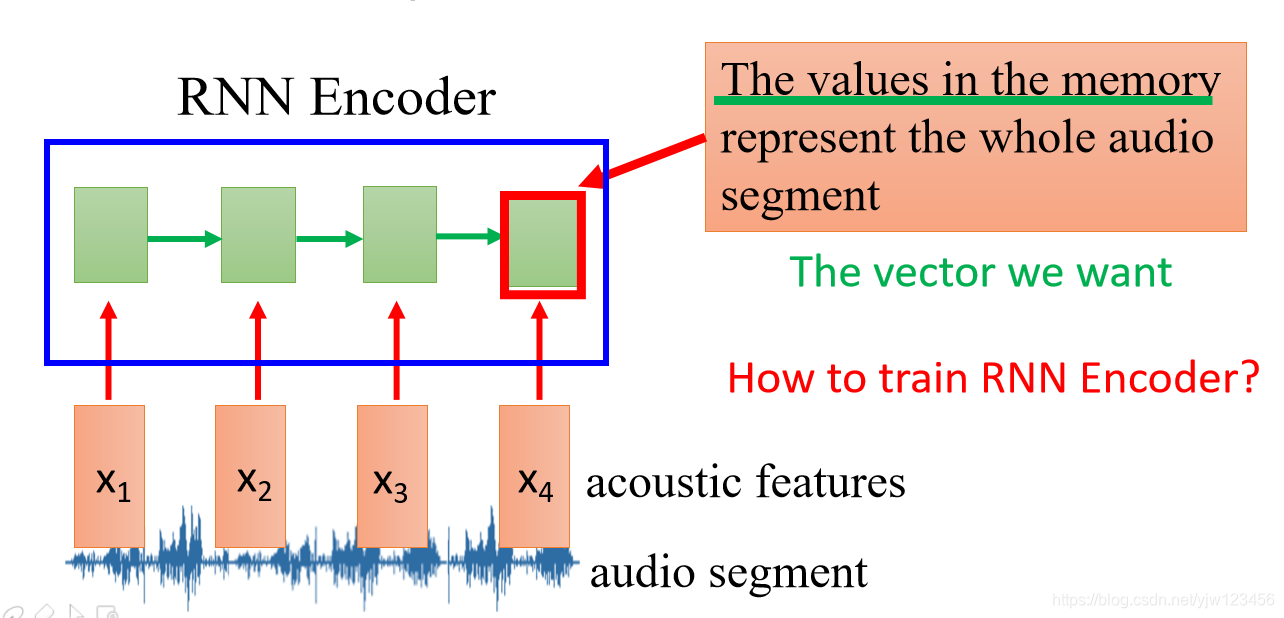
那现在的问题是如何训练RNN解码器呢?
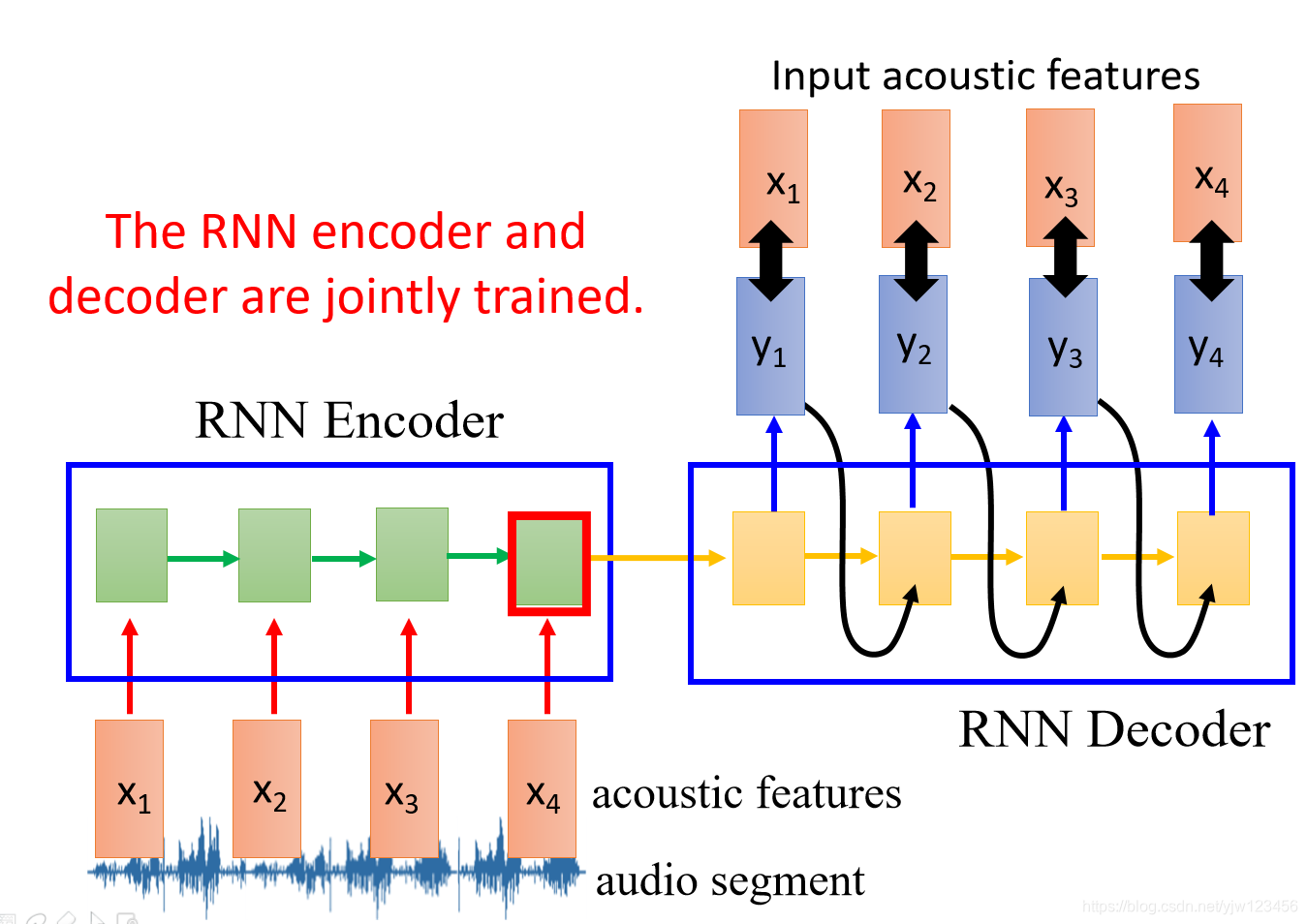
RNN解码器的作用是把编码器存在内存中的值当做输入,产生一个声学特征
,然后希望
和
越接近越好;
然后根据
产生
,根据
产生
…
这样其实RNN编码器和RNN解码器可以一起训练的。
Attention-based Model
除了RNN用到了memory以外,还有另外一种网络也用到的,就是Attention-based Model。

可以把它看成是RNN升级版,我们知道人的大脑可以同时记得很多东西,比如可以同时记得早餐吃了什么和10年前的夏天发生的事情。
当有人问你什么是深度学习的时候,你的脑中会提取重要信息,然后把这些信息组织起来,得到答案。但是此时你的大脑会自动忽略无关的信息,比如10年前夏天发生的事情。
我们也可以让机器有个很大的记忆容量

可以分配一个很大的空间,里面可以放很多向量,每个向量可以存放某种记忆。
当你把输入喂给DNN或RNN的时候,这个NN会操控一个Reading Head Controller(DispatchServletController?),这个Controller会决定Reading Head放的位置,

然后机器会从Reading Head的位置读取信息出来,然后产生最后的输出。
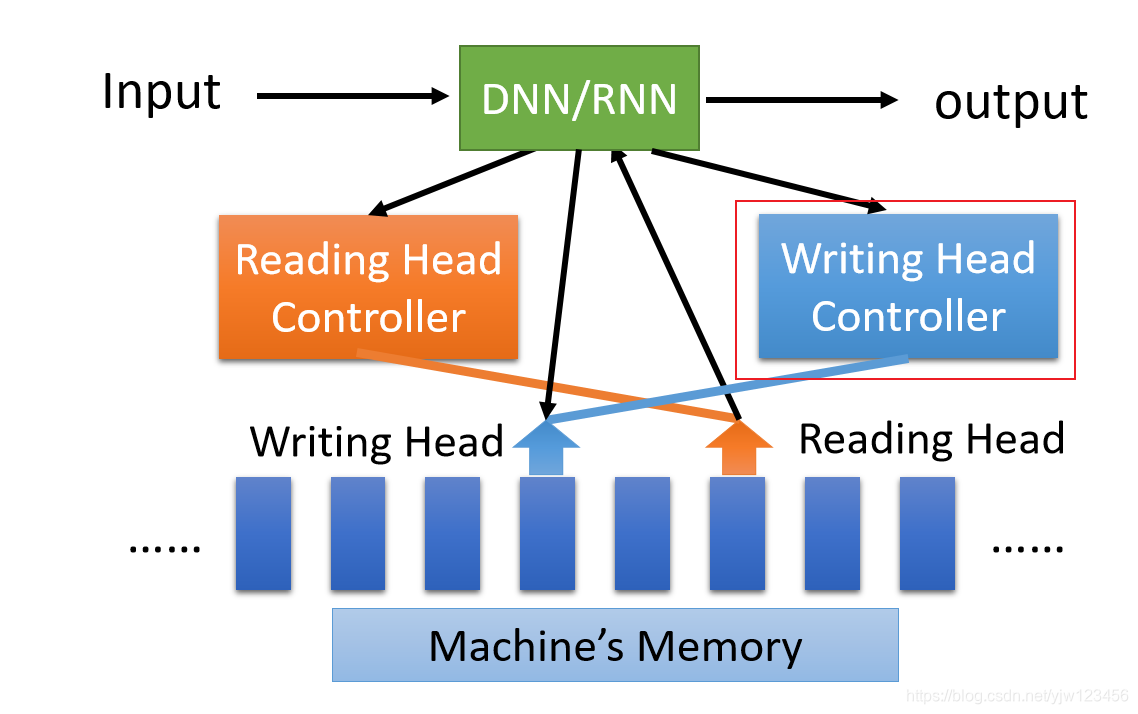
它还有一个2.0的版本,这个新版本它可以操控一个Writing Head Controller,这个Controller会决定在哪里写,然后机器会把信息写到这个位置。这个东西就是大名鼎鼎的神经图灵机。
Reading Comprehension
现在Attention-based Model常用在阅读理解(Reading Comprehension,不是高中做的英语阅读理解啊)里面。
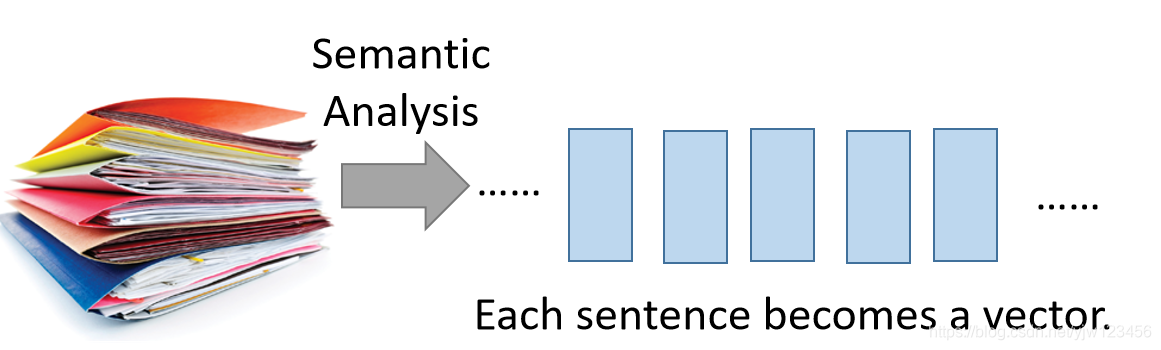
所谓阅读理解就是让机器去读一堆文档,机器把文档中的每句话变成一个向量,每个向量代表每句话的语义。
接下来你可以问机器一些问题,看它理解了这些文档没有。
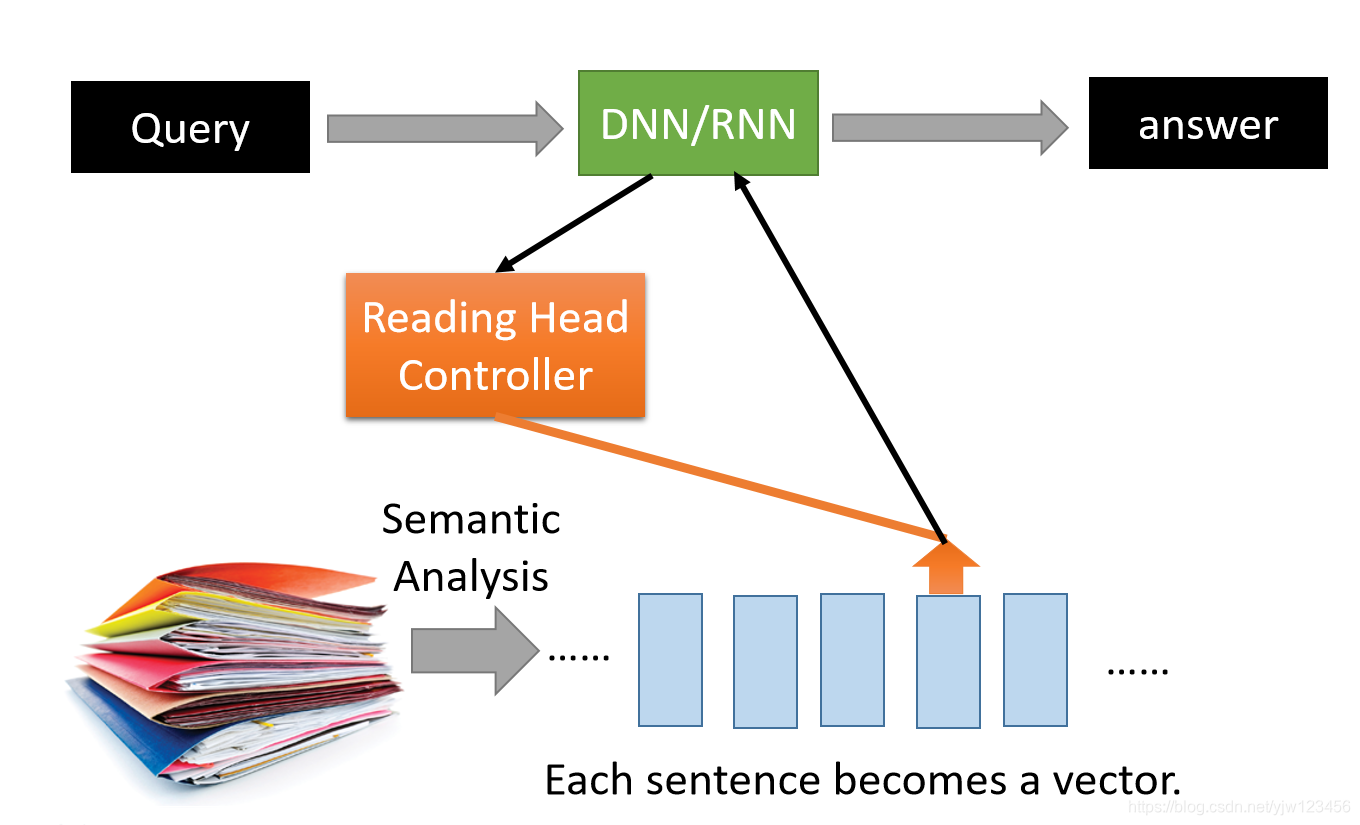
这些问题会丢进中央处理器里面(DNN/RNN),由它来决定哪些向量是与这些个问题有关的。
机器会把有关的向量读到中央处理器里面,可以读取多次,最终会形成一个答案。
参考
1.李宏毅机器学习

 博客专家
博客专家