一、mongo批量生成数据
MongoDB存储的是二进制的json(BSON)数据,底层是用js来实现的。
所以在MongoDB中可以将js的for循环代码和我们的数据库做操作指令一起配合来使用,在数据库中批量插入数据。
> for(var i=0;i<1000;i++){
... db.test.insert({_id:i+1,name:'haha'+i})}
二、游标
如果数据库中数据量较大,比如刚刚插入的1000条,我们执行 db.test.find() 的话,
他会将所有的数据都查询出来给我们,如果查询的时候,像python中生成器那样,每次只返回一个数据就比较方便。其实在MongoDB中也有类似生成器的东西,它就是 游标 。
1、游标的定义和声明
mongo的游标相当于python中的迭代器。通过将查询结构定义给一个变量,这个变量就是游标。通过这个游标,我们可以每次获取一个数据。
var cursor_name = db.test.find()
2、游标的操作
> var mycursor = db.test.find().limit(5)
> mycursor.next()
{ "_id" : 1, "name" : "haha0" }
> mycursor.next()
{ "_id" : 2, "name" : "haha1" }
> mycursor.hasNext()//判断游标是否已经取到尽头,|true表示没有到尽头。
true
> print(mycursor.next())//会显示是一个bson格式的数据
[object BSON]
> printjson(mycursor.next())
{ "_id" : 4, "name" : "haha3" }
我们可以写一个while循环来打印游标结果:
> while(mycursor.hasNext()){printjson(mycursor.next())}
{ "_id" : 1, "name" : "haha0" }
{ "_id" : 2, "name" : "haha1" }
.
.
{ "_id" : 14, "name" : "haha13" }
{ "_id" : 15, "name" : "haha14" }
>
游标的toArray()方法,方便我们可以看到所有行
> var mycursor = db.test.find().limit(5)
> mycursor.next()
{ "_id" : 1, "name" : "haha0" }
> mycursor.next()
{ "_id" : 2, "name" : "haha1" }
> mycursor.toArray()//看到所有行
[
{
"_id" : 3,
"name" : "haha2"
},
{
"_id" : 4,
"name" : "haha3"
},
{
"_id" : 5,
"name" : "haha4"
}
]
>> var mycursor = db.test.find().limit(5)
> mycursor.toArray()[2]//看到第二行
{ "_id" : 3, "name" : "haha2" }
3、cursor.forEach(回调函数)
> var getname = function(obj){print(obj.name)}
> var cursor = db.test.find().limit(10)
> cursor.forEach(getname)
haha0
haha1
haha2
haha3
haha4
haha5
haha6
haha7
haha8
haha9
4、分页中的游标应用
一般的,我们假设每页N行,当前是page页,就需要跳过(page-1)*N,再取N行,
在mysql中,用 limit,offset,N来实现;
在MongoDB中,用skip(),limit()函数来实现
> var mycursor = db.test.find().skip(90).limit(10)
> mycursor
{ "_id" : 91, "name" : "haha90" }
{ "_id" : 92, "name" : "haha91" }
{ "_id" : 93, "name" : "haha92" }
{ "_id" : 94, "name" : "haha93" }
{ "_id" : 95, "name" : "haha94" }
{ "_id" : 96, "name" : "haha95" }
{ "_id" : 97, "name" : "haha96" }
{ "_id" : 98, "name" : "haha97" }
{ "_id" : 99, "name" : "haha98" }
{ "_id" : 100, "name" : "haha99" }
三、创建索引
1、作用
- 索引提高查询速度,降低写入速度,[权衡常用的查询字段,不必在太多列上建索引
- 在mongodb中,索引可以按字段升序/降序来创建,便于排序
- 默认是用btree来组织索引文件,2.4版本以后,也允许建立hash索引
2、常用命令
- 查看当前索引状态:db.test.getIndexes()
- 创建普通单列索引:db.test.ensureIndex({field:1/-1}) //1为正序,-1为逆序
- 删除单个索引:db.test.dropIndex({field:1/-1})
- 删除所有索引:db.test.dropIndexes() //_id所在的列的索引不能删除
- 创建多列索引:db.test.ensureIndex({field1:1/-1,field2:1/-1})
多列索引的使用范围更广,因为一般情况下,我们都是通过多个字段来进行查询数据的,这时候单列索引其实用不到。 两个列一起建立索引其实就是将两个列绑定到一起,来创建索引。 - 子文档索引:
1.插入两条带子文档的数据
db.shop. insert({name: 'N0kia' , SPC: {weight: 120 , area: ' taiwan ' } } ) ;
db.shop. insert({name: 'sanxing ' , SPC :{weight: 100 , area: 'hanguo'} } ) ;
2.查询出产地在台湾的手机
db.shop.find({'spc.area':'taiwan'})
3.给子文档加索引
db.shop.ensureIndex({'spc.area':1})
- 唯一索引:{unique:true} ,唯一索引的列不能重复插入
db.collection.ensureIndex({field:1/‐1},{unique:true})
- hash索引
db.collection.ensureIndex({field:'hashed'})
四、MongoDB数据的导入导出
1、常用命令
导入/导出可以操作的是本地的mongodb服务器,也可以是远程的
‐‐host host 主机
‐‐port port 端口
‐u username 用户名
‐p passwd 密码
2、mongoexport 导出json格式的文件
_id列总是导出。导出csv文件的时候,需要指定导出哪些列
‐d 库名
‐c 表名
‐f field1,field2...列名
‐q 查询条件
‐o 导出的文件名
‐‐type csv 导出csv格式(便于和传统数据库交换数据)
#例1、
mongoexport ‐d test ‐c news ‐o test.json
#只导出goods_id,goods_name列
mongoexport ‐d test ‐c goods ‐f goods_id,goods_name ‐o goods.json
# 只导出价格低于1000元的行
mongoexport ‐d test ‐c goods ‐f goods_id,shop_price ‐q ‘{shop_ price:{$lt:200}}’ ‐o goods.json
#csv
mongoexport ‐d shop ‐c goods ‐o goods.csv ‐‐type csv ‐f goods_id,cat_id,g oods_name,shop_price
3、Mongoimport 导入
‐d 待导入的数据库
‐c 待导入的表(不存在会自己创建)
‐‐file 备份文件路径
#导入json
mongoimport ‐d test ‐c goods ‐‐file ./goodsall.json
#导入csv
mongoimport ‐d test ‐c goods ‐‐type csv ‐f goods_id,goods_name ‐‐file ./g oodsall.csv
4、mongodump 导出二进制bson结构的数据及其索引信息
- 导出的文件放在以database命名的目录下
- 每个表导出2个文件,分别是bson结构的数据文件, json的索引信息
- 如果不声明表名, 导出所有的表
‐d 库名
‐c 表名
mongodum -d test [-c 表名] 默认是导出到mongo下的dump目录
5、mongorestore 导入二进制文件
二进制备份,不仅可以备份数据,还可以备份索引,备份数据比较小.速度比较快
mongorestore ‐d shop ‐c goods ‐‐dir ./dump/shop/goods.bson
五、replaction复制集
一般情况下,我们通常在机器上安装了一个数据库,这是我们的数据都是存在这个数据库中的,如果有一天,因为一些不可控因素导致数据库宕机或者数据库的文件丢失,此时损失就很大了。针对于这种问 题,我们希望有一个数据库集,在我们其中一个数据库进行插入的时候,其他数据库也能插入数据,这样 其中一台服务器宕机了,也能够使我们的数据正常存取。
在MongoDB中,是通过replaction复制集来实现此功能的。
在Windows下实现复制集的方法:
- 创建复制集之前,把所有的mongo服务器都关掉。
- 创建三个存储数据库的文件夹,用来保存数据文件。
- 打开三个cmd窗口,分别启动三个mongodb,其中的–replSet就表示创建的数据集的名称,必须指定相同的名称才可以。
mongod --dbpath C:\MongoDB\Server\3.4\data\m1 --logpath C:\MongoDB\Server\3.4\data\logs\mongo1.log --port 27017 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m2 --logpath C:\MongoDB\Server\3.4\data\logs\mongo2.log --port 27018 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m3 --logpath C:\MongoDB\Server\3.4\data\logs\mongo3.log --port 27019 --replSet rs
- 配置
1 var rsconf = {
2 _id:'rs',
3 members:[
4 {_id:0,host:'127.0.0.1:27017'},
5 {_id:1,host:'127.0.0.1:27018'},
6 {_id:2,host:'127.0.0.1:27019'}
7 ]
8 }
这时候我们可以打印rsconf来看一下

printjson(rsconf)
接下来需要将配置初始化
rs.initiate(rsconf)
现在我们看到,现在登录客户端已经不是那台机器,而是rs复制集
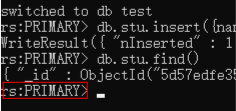
我们在主机上插入一条数据,再从机上必须输入rs.slaveOk()之后才能被允许查看数据
- 删除复制集
rs.remove('127.0.0.1:27019')
删除节点后,如果想再添加,必须重新配置才可以。
1 var rsconf = {
2 _id:'rs',
3 members:[
4 {_id:0,host:'127.0.0.1:27017'},
5 {_id:1,host:'127.0.0.1:27018'},
6 {_id:2,host:'127.0.0.1:27019'}
7 ]
8 }
9 再输入:rs.reconfig(rsconf)
再输入rs.status(),可以看到数据集现在又是三个了。
