fhq treap
简要回顾treap:
treap=tree+heap
它的形态是一棵二叉树,每个点的权值满足二叉搜索树的性质,每个点的随机值满足小根堆的性质
fhq treap的核心操作有两个:分裂和合并
分裂:对于给定的权值k,将一棵树分裂成两个,使得分裂后的两棵树一棵权值全部小于等于k,另一棵权值全部大于k,并且依旧满足分裂前的性质
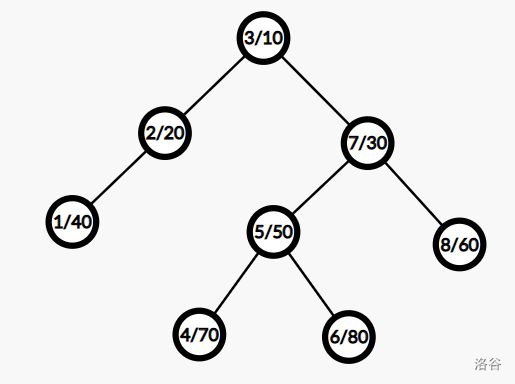
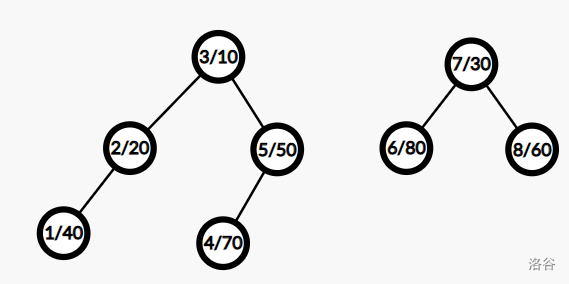
如上图,每一个点前面的数表示权值,后面的数表示随机值
当我们遍历到一个点时,如果它的权值小于k,那么它的左子树会被分到左边的树里,然后我们遍历它的右儿子,如果大于等于k,则把它的右子树分到右边的树里,然后遍历他的左儿子。
比如这里我们令\(k = 5\),那么我们一个子树里面是3的左子树和5的左子树,另一个子树里面是7的右子树和6的右子树
void split(int cnt, int k, int &x, int &y)//注意传址符
{
if(!cnt)//到达递归边界
{
//这个时候有两种情况
//如果是第一次分裂,则初始化0
//如果到了叶子节点,x和y会在回溯的时候改变
x = y = 0;
return;
}
if(T[cnt].val <= k)
{
x = cnt;//加入到x
split(T[cnt].r, k, T[cnt].r, y);
//遍历右子树
//之所以把r放到x的位置上是因为r的左子树也有可能在x中
}
else//和上面反过来
{
y = cnt;
split(T[cnt].l, k, x, T[cnt].l);
}
Update(cnt);
}
合并:将两个子树按照随机值合并(因为要保证树的深度所以要按照随机值)
由于我们已经保证了两个子树权值的大小关系,所以只需每次让随机值小的在上面就行了
int merge(int x, int y)
{
if(x == 0) return y;
if(y == 0) return x;
if(T[x].pri <= T[y].pri)
{//x小,把y接在右边
T[x].r = merge(T[x].r, y);
Update(x);
return x;
}
if(T[x].pri > T[y].pri)
{//y小,把x接在左边
T[y].l = merge(x, T[y].l);
Update(y);
return y;
}
}
第k大:
把握二叉搜索树的性质
int kth(int cnt, int k)
{
if(T[T[cnt].l].siz + 1 == k) return T[cnt].val;//这个数为根
if(T[T[cnt].l].siz >= k) return kth(T[cnt].l, k);//在左区间
else return kth(T[cnt].r, k - T[T[cnt].l].siz - 1);//右区间:排名-左儿子和自己
}
接下来是操作:
if(opt == 1)
{//添加
int x, y;
split(root, a, x, y);//分离<=x和>x
root = merge(merge(x, New(a)), y);//把x添加进去
}
if(opt == 2)
{//删除
int x, y, z;
split(root, a, x, y);//分离<=x和>x
split(x, a - 1, x, z);//在<=x中分离<x和=x
z = merge(T[z].l, T[z].r);//在=x中删除一个x
root = merge(merge(x, z), y);//将剩余的合并
}
if(opt == 3)
{//查询x排名
int x, y;
split(root, a - 1, x, y);//分离<x和>=x
cout << T[x].siz + 1 << endl;//x的排名为<=x的数的个数
root = merge(x, y);//合并
}
if(opt == 4)
{//查询排名x的数
cout<< kth(root, a) << endl;
}
if(opt == 5)
{//求x前驱
int x, y;
split(root, a - 1, x, y);//分离<x和>=x
cout << kth(x, T[x].siz) << endl;//前驱就是<x的数的个数的那个数
root = merge(x, y);//合并
}
if(opt == 6)
{//求x后继
int x, y;
split(root, a, x, y);//分离<=x和>x
cout << kth(y, 1) << endl;//>x中最小的那个数
root = merge(x, y);//合并
}
完整代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 100005;
int iCnt;
struct sTree
{
int l, r, val, pri, siz;
}T[N];
void Update(int cnt)
{
T[cnt].siz = T[T[cnt].l].siz + T[T[cnt].r].siz + 1;
}
int New(int x)
{
T[++iCnt].val = x;
T[iCnt].pri = rand();
T[iCnt].siz = 1;
return iCnt;
}
void split(int cnt, int k, int &x, int &y)//注意传址符
{
if(!cnt)//到达递归边界
{
//这个时候有两种情况
//如果是第一次分裂,则初始化0
//如果到了叶子节点,x和y会在回溯的时候改变
x = y = 0;
return;
}
if(T[cnt].val <= k)
{
x = cnt;//加入到x
split(T[cnt].r, k, T[cnt].r, y);
//遍历右子树
//之所以把r放到x的位置上是因为r的左子树也有可能在x中
}
if(T[cnt].val > k)//和上面反过来
{
y = cnt;
split(T[cnt].l, k, x, T[cnt].l);
}
Update(cnt);
}
int merge(int x, int y)
{
if(x == 0) return y;
if(y == 0) return x;
if(T[x].pri <= T[y].pri)
{//x小,把y接在右边
T[x].r = merge(T[x].r, y);
Update(x);
return x;
}
if(T[x].pri > T[y].pri)
{//y小,把x接在左边
T[y].l = merge(x, T[y].l);
Update(y);
return y;
}
}
int kth(int cnt, int k)
{
if(T[T[cnt].l].siz + 1 == k) return T[cnt].val;
if(T[T[cnt].l].siz >= k) return kth(T[cnt].l, k);
else return kth(T[cnt].r, k - T[T[cnt].l].siz - 1);
}
int root;
int main()
{
int n;
cin >> n;
while(n--)
{
int opt, a;
cin >> opt >> a;
if(opt == 1)
{//添加
int x, y;
split(root, a, x, y);//分离<=x和>x
root = merge(merge(x, New(a)), y);//把x添加进去
}
if(opt == 2)
{//删除
int x, y, z;
split(root, a, x, y);//分离<=x和>x
split(x, a - 1, x, z);//在<=x中分离<x和=x
z = merge(T[z].l, T[z].r);//在=x中删除一个x
root = merge(merge(x, z), y);//将剩余的合并
}
if(opt == 3)
{//查询x排名
int x, y;
split(root, a - 1, x, y);//分离<x和>=x
cout << T[x].siz + 1 << endl;//x的排名为<=x的数的个数
root = merge(x, y);//合并
}
if(opt == 4)
{//查询排名x的数
cout<< kth(root, a) << endl;
}
if(opt == 5)
{//求x前驱
int x, y;
split(root, a - 1, x, y);//分离<x和>=x
cout << kth(x, T[x].siz) << endl;//前驱就是<x的数的个数的那个数
root = merge(x, y);//合并
}
if(opt == 6)
{//求x后继
int x, y;
split(root, a, x, y);//分离<=x和>x
cout << kth(y, 1) << endl;//>x中最小的那个数
root = merge(x, y);//合并
}
}
}