现代计算机存储和处理的信息以二值信号表示。这些微不足道的二进制数字,或者称为位(bit),奠定了数字革命的基础。孤立的讲,单个的位不是非常有用。然而,当把位组合在一起,再加上某种 解释,即给不同的可能 位模式 赋予含义,我们就能表示任何有限集合的元素。
一、数值的表示
1. 1 数值的编码
数值的类型主要分为2种:整数 和 浮点数。 编码的方式主要分为3种:无符号编码、补码编码 和 浮点数编码。
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,以及在存储器中如何排列这些字节。无符号 编码基于传统的二进制表示法,表示大于等于0的数字。
补码 编码是表示有符号整数的最常见的方式。
浮点数 编码是表示实数的 科学计数法 的以二位基数的版本,所以浮点数不能精确保存,而且由于表示的精度有限,浮点运算是不可结合的。
无符号数采用原码存储,有符号数采用补码存储。正数的补码就是他本身,负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1. (即在反码的基础上+1)
[+1] = [0000 0001]原 = [0000 0001]反 = [0000 0001]补
[-1] = [1000 0001]原 = [1111 1110]反 = [1111 1111]补- 1
- 2
- 3
计算机的表示法是用有限数量的位来对一个数字编码,因此,当结果太大以至不能表示时,某些运算就会导致 溢出。例如,大多数计算机(使用32bit表示整数数据int),计算表达式 200*300*400*500 会得出结果 -884 901 888。
1.2 进制转换
编写程序的一个常见任务是在位模式的十进制、二进制、八进制和十六进制表示之间人工进行转换。
1.2.1 二进制,八进制 与 十六进制之间的转换
下面以二进制与十六进制之间的转换为例,其他情况在代码中非另外说明:
1、二进制 -> 十六进制
二进制向十六进制转换时,四位转换成十六进制的一位,运算的顺序是从低位向高位依次进行,高位不足四位用零补。以“1110011”转换成十六进制为例,如下图所示:
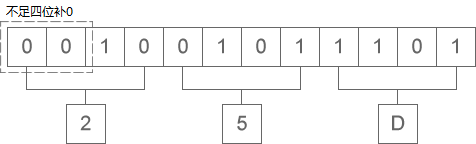
转换的
字长与字节
字长:每个计算机都有一个字长,对于字长为w位的机器而言,虚拟地址范围为0~2w−1,32位的计算机虚拟地址空间被限定为4GB,当然操作系统有办法解决这一问题。
字节:1byte=8bit。
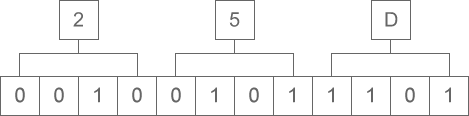
十六进制 -> 二进制
十六进制向二进制转换,就是把十六进制的一位转换成二进制的四位,注意运算的顺序是从低位向高位依次进行。同样以十六进制“0X25D”为例,如下图所示:
2、十进制与十六进制的转换
特殊情况:
如果值x(十进制)是2的n次幂就可以很轻松的通过下面这个公式直接转换为十六进制。
n = i + 4j 其中i在[0,3]范围内- 1
整个转换的过程分为以下几步:
通过计算得出值x为2的n次幂
将n转换为 i + 4j,其中i在[0, 3]范围内
根据i的映射关系计算十六进制的第一位,其映射关系如下:
i = 0 ==> 0、i = 1 ==> 2、i = 2 ==> 4、i = 3 ==> 8
拿到j的值在最后的十六进制值的后面添加j个0
一般情况:
十进制转换为任意进制
十进制转换为其他进制较为简单,只要依次取得余数即可。注意,越先出来的余数是越低位。
例:314156=19634*16+12 (C)19634=1227*16+2 (2)
1227=76*16+11 (B)
76=4*16+12 (C)
4=0*16+4 (4)
故16进制表示为0x4CB2C
任意进制转换为十进制
例:十六进制0x7AF转换为十进制:7*16^2+10*16+15=1967二进制数 1010 转换为十进制: (0 * 2^0) + ( 1 * 2^1) + (0 * 2 ^ 2) + (1 * 2 ^3) = 10。
字数据大小
字长与字节
字长:每个计算机都有一个字长,对于字长为w位的机器而言,虚拟地址范围为0~2w−1,32位字长的计算机虚拟地址空间被限定为4GB,64位字长机器则使得虚拟空间为16GB。当然操作系统有办法解决这一问题。
字节:1byte(字节)=8bit(位)。
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,以及在存储器中如何排列这些字节。
- 对象的地址:在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。如,int类型的变量x的地址为0x100,也就是说,地址表达式&x的值为0x100。那么,x的4个字节将被存储在存储器的0x100、0x101、0x102和0x103位置。
- 字节的排列:排列表示一个对象的字节有两个通用的规则——大端法和小端法。假设变量x类型为int,位于地址0x100处,它的十六进制值为0x01234567。地址范围为0x100~0x103的字节,不同的方法排列顺序如下:

查看不同程序对象的字节表示可以使用如下代码:
#include<bits/stdc++.h>
using namespace std;
typedef char *byte_pointer;
void show_bytes(byte_pointer start, int len)
{
for (int i = 0; i < len; i++)
printf(" %.2x", start[i]);
printf("\n");
}
//利用强制类型转换
void show_int(int x)
{
show_bytes((byte_pointer) &x, sizeof(int));
}
void show_float(float x)
{
show_bytes((byte_pointer) &x, sizeof(float));
}
void show_pointer(void *x)
{
show_bytes((byte_pointer) &x, sizeof(void *));
}
void show_unsigned(unsigned x)
{
show_bytes((byte_pointer) &x, sizeof(unsigned));
}
表示字符串: 利用ASII码
表示代码


布尔代数简介

位级运算(|、&、^、~)
位级运算就是按位进行布尔运算。这些运算能运用到任何“整型”的数据类型上,以下是一些对char数据类型表达式求值的例子:

- 掩码运算:位级运算的一个常见用法就是实现掩码运算。掩码是一串二进制代码对目标字段进行位&运算,屏蔽当前的输入位。
例如:掩码0xFF,x=0x89ABCDEF,x&0xFF将得到0x000000EF。
表达式~0将生成一个全1的掩码,不管机器的字大小是多少。
逻辑运算的一些知识:
- x == y 等价于 !(x ^ y)
- 逻辑运算与位级运算的区别:1、所有非0参数均为True,反之则为False。2、如果对第一个命题求值就能确定表达式结果,那么逻辑运算符就不会再对第二个命题求值(例如:a && 5/a 不会被零除, p && *p++也不会导致间接引用空指针
逻辑右移:逻辑右移在左端补k个0。(左边K位向右搬家)
算数右移:算术右移在左端补k个最高有效位的值。
例子:
对于无符号数据,右移必须是逻辑的。 x<<j<<k等价于(x<<J)<<K 遵从从左到右规则

整数
有符号数的表示
- 原码表示:最高有效位是符号位,其余表示数值。如:
3 = [00000011]
-3 = [10000011] - 反码表示:最高有效位为负权,权重为−(2w−1−1),其余同补码。如:
3 = [00000011]
-3 = [11111100]
表现形式为按位取反,因为最高位相当于掩码。 - 补码表示:最高有效位为负权,权重为−2w−1,符号位设置为1时,表示负数,设置为0时,值为非负。如:
3 = [00000011]
-3 = [11111101]
负数的补码是将其正数各位取反之后再加1。补码的范围是不对称的,TMin没有与之对应的正数。
补码是计算机中最常见的有符号数表示方式。
- 原码表示:最高有效位是符号位,其余表示数值。如:
扩展数字
- 零扩展:在开头补0。具体见p54
- 符号扩展:在开头添加最高有效位。
截断数字:化为二进制后,直接丢弃高位即可。如:
int x = 52191; //1100111111000111 short sx = (short)x; //1100111111000111-->-12345 int y = sx; //-12345- 1
- 2
- 3
整数的运算:补码执行与无符号算术相同的位级实现。对于计算机来说可以按相同方式计算。
浮点数
二进制的小数
首先,我们看下小数的二进制表示。浮点数的表示
IEEE浮点标准用V=(−1)s×2E×M的形式来表示一个数:- 符号(sign):s决定这个数是负数(s=1)还是正数(s=0)。
- 阶码(exponent):E的作用是对浮点数加权,这个权重是2的E次幂(可能是负数)。
- 尾数(significand):M是一个二进制小数。
在单精度浮点格式(float)中,s、exp和frac字段分别为1位、k = 8位和n = 23位,得到一个32位的表示。
在双精度浮点格式(double)中,s、exp和frac字段分别为1位、k = 11位和n = 52位,得到一个64位的表示。根据exp的值,被编码的值可以分成三种不同的情况:
- 规格化的值:
阶码的位表示为ek−1…e1e0
Bias=2k−1−1(单精度是127,双精度是1023)
E=e−Bias
小数字段frac描述为小数值f,其中0≤f<1,其二进制表示为0.fn−1…f1f0
M=1+f - 非规格化的值:
当阶码域为全0时,所表示的数就是非规格化形式。
E=1−Bias
M=f - 特殊值:
当阶码域为全1时出现。当小数域全为0时,得到的值表示无穷,s = 0 时是+ ∞, s = 1时是- ∞。当我们把两个非常大的数相乘,或者除以零时,无穷能够表示溢出的结果。当小数域为非零时,结果值被称为“NaN”,就是“不是一个数”(Not a Number)的缩写。
下图展示了假定的8位浮点格式的示例,其中有k=4的阶码位和n=3的小数位。偏置量Bias=7。规格化E=e−7,非规格化E=−6。小数f的值的范围0,18,…,78。
根据其表现形式,我们可以知道浮点数的表示范围及精度:
浮点数的舍入
IEEE浮点格式定义了四种不同的舍入方式:
其中,向偶数舍入又称为最近舍入,这种方式与四舍五入唯一的不同就是对.5的舍入上,采用取偶数的方式。这样是为了避免统计偏差。默认的舍入方式为向偶数舍入。浮点数的运算
浮点数运算通过一定的步骤,阶码与尾数貌似分别计算,具体暂不做了解。
浮点运算只有有限的范围和精度,而且不遵守普遍的算术属性,比如结合性。使用的时候需要小心。






