深度神经网络实战
数据集选用的是分类数据集
因为:深度神经网络就是层次非常深的神经网络
所以在本文中通过一个for循环添加了20层单元数为100的全连接层,激活函数为relu,具体见如下代码结构。
# tf.keras.models.Sequential()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",
optimizer = keras.optimizers.SGD(0.01),
metrics = ["accuracy"])
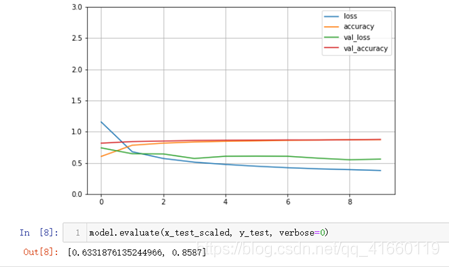
打印出值的变化图后可以看出:上面的深度神经网络一开始训练平缓(learning rate = 0.01 )
深度神经网络一开始训练结果平缓原因:
# 1. 参数众多,训练不充分
# 2. 梯度消失一般发生在深度神经网络里 -> 链式法则 -> 复合函数f(g(x)) 求导
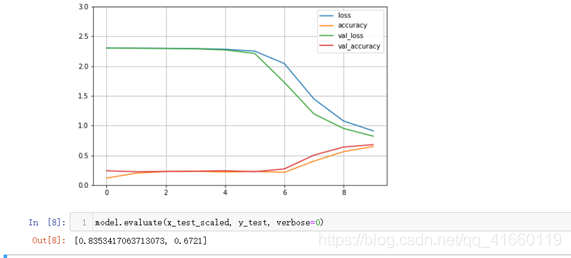
下面这张图是将学习率设为0.001,其余不变的效果
批归一化实战
接下来说明批归一化的实战:(批归一化可以缓解梯度消失,运行时间会慢一点)

# tf.keras.models.Sequential()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.BatchNormalization()) #keras批归一化被实现为一个层次
"""
由于深度学习领域一直存在一个争论,批归一化与激活函数的先后关系到底是什么,于是
在下面补充了另一种方法,由于批归一化与激活函数都已被实现为一个层次,所以两种方法都很简单
"""
"""
model.add(keras.layers.Dense(100))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation('relu'))#keras中激活函数被实现为一个层次
"""
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",
optimizer = keras.optimizers.SGD(0.01),
metrics = ["accuracy"])

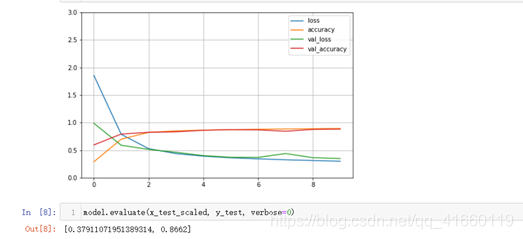
note:此时,learning rate还是0.01,但是可以看到刚才看到的“初始平缓”的现象也没有了,对于这两个原因:
# 1. 参数众多,训练不充分
# 2. 梯度消失一般发生在深度神经网络里 -> 链式法则 -> 复合函数f(g(x)) 求导
第一个是没有变化的,参数数量不变,第二个原因会被批归一化消减一些,因为批归一化可以在一定程度上缓解梯度消失,具体原因为:批归一化可以使每一层的值变得更加规整,从而使导数计算的更加精准。
激活函数实战
着重介绍selu激活函数,selu是自带归一化功能的激活函数,因为它自带了归一化,所以它也能在一定程度上缓解梯度消失的问题
# tf.keras.models.Sequential()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",
optimizer = keras.optimizers.SGD(0.01),
metrics = ["accuracy"])
Dropout实战
note:一般情况下是不给每层都添加dropout的,而是只给最后几层做dropout,来防止过拟合。下面展示只给最后一层做dropout。(在keras中dropout也被实现为了一个layer,因此只需要在layer后面添加dropout_layer,就可以给前面的那一层做dropout)
仔细看下面的代码可以发现,代码中有两个dropout,一个是AlphaDropout,一个是Dropout,那么它们的区别是什么呢?
AlphaDropout是一个更加强大的Dropout,它强大在两个地方:
1. 均值和方差不变 (普通的Dropout在Dropout之后,可能这一层激活值的分布就发生变化了,但AlphaDropout不会)
2. 归一化性质也不变(因为均值和方差不变,所以归一化性质也不变,有了这个性质之后,这个Dropout就可以和批归一化、selu在一块使用,因为它不会导致分布发生变化)
所以:现在大家一般会使用AlphaDropout,而不会使用传统的Dropout。
# tf.keras.models.Sequential()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu"))
model.add(keras.layers.AlphaDropout(rate=0.5)) #rate参数表示丢掉的单元比例是多少,一般为0.5,因为此时子网数目最大
# AlphaDropout: 1. 均值和方差不变 2. 归一化性质也不变
# model.add(keras.layers.Dropout(rate=0.5))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",
optimizer = keras.optimizers.SGD(0.001),
metrics = ["accuracy"])
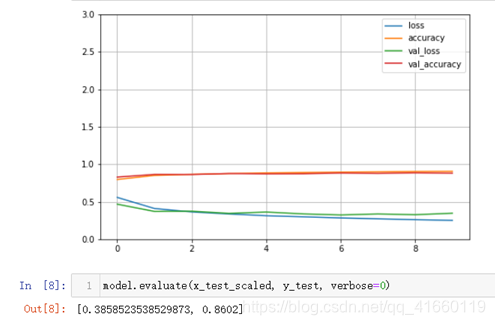
可以看到在最后一层全连接层的前面加了一层dropout层。
运行结果如下: