本篇文章是基础版,而实际上对于MNIST数据集的利用程度还没达到极限,对该模型还可进一步探究(反向查询),有兴趣可以看我另一篇文章
https://blog.csdn.net/CxsGhost/article/details/104829332
——————————————————————————————————————————————————
1. MNIST介绍:
- mnist应该是深度学习最著名的数据集之一,包含70,000张图片,其中60,000张是训练数据,10,000是测试数据。
- 每张图片是10个个位数(0到9)的“手写体”,图片是28 * 28像素,除了数字体部分,其它区域都是空白
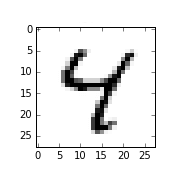
- 若要在神经网络中使用,很自然想到把图片转化为784(28*28)的向量来进行输入
可以在此下载:
http://www.pjreddie.com/media/files/mnist_train.csv(训练数据)
http://www.pjreddie.com/media/files/mnist_test.csv(测试数据)
在Excel中打开是下面这个样子,其中第一列代表本条数据是数字几(target)

2. 搭建前馈神经网络(全连接):
主要思路:
- 784个输入层节点,500个隐藏层节点(可以按照自己的意愿设置,500个时我得到的准确率最高)
- 10个输出层节点:比如对于数字2的一条训练数据,我们可以把target转化成
2: [0.0, 0.0, 0.99, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
这样做的意思就是,指导神经网络在第2个输出节点输出尽可能大的数字,因为sigmoid函数不能输出1,所以就0.99
所以最终输出的10个数据中,最大数所在的位置,就是神经网络给出的判断
(1)需要具备的属性:
- 输入节点数量,隐藏节点数量,输出节点数量。(隐藏层只一层就可以)
- 学习率
- 节点上采用的激活函数(这里我选择sigmoid)
- 输入层和隐藏层间的权重矩阵,隐藏层和输出层之间的权重矩阵
用numpy中normal函数从正态分布中选取初始权重
-
均值:0.0
-
标准差:前一层的节点数量平方根的倒数(比较科学的选法,自行百度详解)
-
矩阵大小:
输入层与隐藏层(self.wih):输入层节点数为列数,隐藏层节点数为行数
隐藏层与输出层(self.who):隐藏层节点数为列数,输出层节点数为行数计算方法如下图(以一个输入中有两个数据为例), W1,1代表第一个节点与下一层的第一个节点间的权重链接
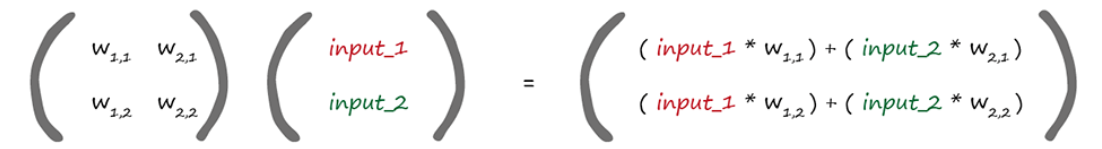
class NeuralNetwork:
def __init__(self, inputnodes, outputnodes,
hiddennodes, learningrate):
# 设置节点数量属性
self.innodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.lr = learningrate
# 按照正态分布设置初始权重矩阵
self.wih = np.random.normal(loc=0.0,
scale=1 / np.sqrt(self.innodes),
size=(self.hnodes, self.innodes))
self.who = np.random.normal(loc=0.0,
scale=1 / np.sqrt(self.hnodes),
size=(self.onodes, self.hnodes))
# 这里scipy.special.expit(),是sigmoid函数,用于正向激活
self.activation_function = lambda x: scipy.special.expit(x)
——————————————————————————————————————————————————
(2)接收数据,更新权重
- 主要方法:梯度下降
- 损失函数:平方损失函数
先把输入数据由行向量转置为列向量,同时把target也转置为列,因为最终输出的是列向量
然后计算输出,结合target更新权重,下面的代码也有注释。
数据是采用一条一条输入进行训练的,矩阵运算的速度非常快
权重更新:
以更新隐藏层和输出层之间的某个权重为例,损失函数是:
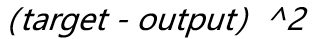
对某一个权重求偏导后(把2省略了):

红色的output是这个权重连接的隐藏层的节点的输出,不是输出节点的输出(上面的式子可以自己推一下)
根据以上公式更新权重即可,代码如下:
def train(self, input_list_1, target_list):
# 转置输入数据,以及目标数据
input_1 = np.array(input_list_1, ndmin=2)
input_1 = np.transpose(input_1, axes=(1, 0))
targets = np.array(target_list, ndmin=2)
targets = np.transpose(targets, axes=(1, 0))
# 计算隐藏层输出,以及最终输出
hidden_inputs_1 = np.dot(self.wih, input_1)
hidden_outputs_1 = self.activation_function(hidden_inputs_1)
final_inputs_1 = np.dot(self.who, hidden_outputs_1)
final_outputs_1 = self.activation_function(final_inputs_1)
# 计算输出层损失,并反向传播给隐藏层
output_errors = targets - final_outputs_1
hidden_errors = np.dot(np.transpose(self.who, axes=(1, 0)), output_errors)
# 对两组权重进行梯度下降,E(out - target) * sigmoid * ( 1 - sigmoid ) *(矩阵点积) O(hidden)
self.who += self.lr * np.dot((output_errors * final_outputs_1 * (1.0 - final_outputs_1)),
np.transpose(hidden_outputs_1, axes=(1, 0)))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs_1 * (1.0 - hidden_outputs_1)),
np.transpose(input_1, axes=(1, 0)))
(3)预测输入:
这部分代码没什么好说的,把输入数据转置一下然后逐步计算,返回输出数据
def query(self, inputs_list_2):
# 把输入转化成矩阵并转置
inputs_2 = np.array(inputs_list_2, ndmin=2)
inputs_2 = np.transpose(inputs_2, axes=(1, 0))
# 计算输出结果
hidden_inputs_2 = np.dot(self.wih, inputs_2)
hidden_outputs_2 = self.activation_function(hidden_inputs_2)
final_inputs_2 = np.dot(self.who, hidden_outputs_2)
final_outputs_2 = self.activation_function(final_inputs_2)
return final_outputs_2
至此神经网络各项功能基本就完成了
3. 数据预处理:
再回头看训练数据(以下是一部分截图):
- 范围是0 ~ 255,并且绝大多数都是0。而根据sigmoid函数的性质,输入这么大的数会导致输出都趋近于1,效果很差,所以进要进行归一化
- 输入过多的0会导绝大多数权重连接失效,从而很难进行权重更新,所以我们加上0.01来保底
- 根据前文主要思路中所说,target不同的值,转化成不同的target矩阵

代码:
# 读取数据到dataframe
train_data = pd.read_csv("MNIST_all/mnist_train.csv", header=None)
# 把label和input先分离
train_data_targets = train_data.iloc[:, 0].values
train_data_inputs = train_data.values
train_data_inputs = np.delete(train_data_inputs, obj=0, axis=1)
# 缩放input的数据范围,来适用于sigmoid
train_data_inputs = train_data_inputs / 255.0 + 0.01
# 把target转化为标记矩阵,然后转置
data_targets = np.zeros(shape=(len(train_data_targets), 10))
for t in range(len(train_data_targets)):
data_targets[t][train_data_targets[t]] = 0.99
train_data_targets = data_targets
以上就是主要的几块代码
——————————————————————————————————————————————————
最后创建实例,输入数据进行训练,然后按相同的方式处理test数据,查看学习效果
- 学习率最优值差不多是在:0.1 ~ 0.2
- 隐藏层节点数量在100到500表现都还不错(500最好)
- 迭代次数在5次的时候性能比较好
以上是可以自行更改的,每个人的机器上可能最终得到的性能各不相同
完整代码如下:
import numpy as np
import scipy.special
import pandas as pd
class NeuralNetwork:
def __init__(self, inputnodes, outputnodes,
hiddennodes, learningrate):
# 设置节点数量属性
self.innodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.lr = learningrate
# 按照正态分布设置初始权重矩阵
self.wih = np.random.normal(loc=0.0,
scale=1 / np.sqrt(self.innodes),
size=(self.hnodes, self.innodes))
self.who = np.random.normal(loc=0.0,
scale=1 / np.sqrt(self.hnodes),
size=(self.onodes, self.hnodes))
# 这里scipy.special.expit(),是sigmoid函数,用于正向激活,numpy中并未提供
self.activation_function = lambda x: scipy.special.expit(x)
def train(self, input_list_1, target_list):
# 转置输入数据,以及目标数据
input_1 = np.array(input_list_1, ndmin=2)
input_1 = np.transpose(input_1, axes=(1, 0))
targets = np.array(target_list, ndmin=2)
targets = np.transpose(targets, axes=(1, 0))
# 计算隐藏层输出,以及最终输出
hidden_inputs_1 = np.dot(self.wih, input_1)
hidden_outputs_1 = self.activation_function(hidden_inputs_1)
final_inputs_1 = np.dot(self.who, hidden_outputs_1)
final_outputs_1 = self.activation_function(final_inputs_1)
# 计算输出层损失,并反向传播给隐藏层
output_errors = targets - final_outputs_1
hidden_errors = np.dot(np.transpose(self.who, axes=(1, 0)), output_errors)
# 对两组权重进行梯度下降,E(out - target) * sigmoid * ( 1 - sigmoid ) *(矩阵点积) O(hidden)
self.who += self.lr * np.dot((output_errors * final_outputs_1 * (1.0 - final_outputs_1)),
np.transpose(hidden_outputs_1, axes=(1, 0)))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs_1 * (1.0 - hidden_outputs_1)),
np.transpose(input_1, axes=(1, 0)))
def query(self, inputs_list_2):
# 把输入转化成矩阵并转置
inputs_2 = np.array(inputs_list_2, ndmin=2)
inputs_2 = np.transpose(inputs_2, axes=(1, 0))
# 计算输出结果
hidden_inputs_2 = np.dot(self.wih, inputs_2)
hidden_outputs_2 = self.activation_function(hidden_inputs_2)
final_inputs_2 = np.dot(self.who, hidden_outputs_2)
final_outputs_2 = self.activation_function(final_inputs_2)
return final_outputs_2
# 读取数据到dataframe
train_data = pd.read_csv("MNIST_all/mnist_train.csv", header=None)
# 把label和input先分离
train_data_targets = train_data.iloc[:, 0].values
train_data_inputs = train_data.values
train_data_inputs = np.delete(train_data_inputs, obj=0, axis=1)
# 缩放input的数据范围,来适用于sigmoid
train_data_inputs = train_data_inputs / 255.0 + 0.01
# 把target转化为标记矩阵,然后转置
data_targets = np.zeros(shape=(len(train_data_targets), 10))
for t in range(len(train_data_targets)):
data_targets[t][train_data_targets[t]] = 0.99
train_data_targets = data_targets
# 确定每层的节点数量,学习率
input_nodes = 784
hidden_nodes = 500
output_nodes = 10
# 经测试发现,学习率最优值约在0.1到0.2之间
learn_rate = 0.15
# 创建NeuralNetwork实例,并逐条数据训练
DNN = NeuralNetwork(input_nodes, output_nodes,
hidden_nodes, learn_rate)
print("神经网络搭建完成,开始训练....")
number = 0
while True:
# 对原始数据,旋转后的数据依次进行训练
for each_train_data in zip(train_data_inputs, train_data_targets):
each_input = each_train_data[0]
each_target = each_train_data[1]
DNN.train(each_input, each_target)
number += 1
if number == 5: # 训练5次,这时候正确率差不多是峰值
break
print("训练完成,测试效果")
# 读取并处理测试数据集
test_data = pd.read_csv("MNIST_all/mnist_test.csv", header=None)
test_data_targets = test_data.iloc[:, 0].values
test_data_inputs = np.delete(test_data.values, obj=0, axis=1) / 255.0 + 0.01
# 查看预测效果
pre_right = 0
for each_test in range(len(test_data_targets)):
pre_target = DNN.query(test_data_inputs[each_test])
if pre_target.argmax() == test_data_targets[each_test]:
pre_right += 1
accuracy = pre_right / len(test_data_targets) * 100
print("正确率为:{0:.2f}%".format(accuracy))
