用一句话证明你的JVM水平很牛~

GC的基础知识
1.什么是垃圾
C语言申请内存:malloc free
C++: new delete
c/C++ 手动回收内存
Java: new ?
自动内存回收,编程上简单,系统不容易出错,手动释放内存,容易出两种类型的问题:
- 忘记回收
- 多次回收
没有任何引用指向的一个对象或者多个对象(循环引用)
2.如何定位垃圾
- 引用计数(ReferenceCount) Python等轻量级语言

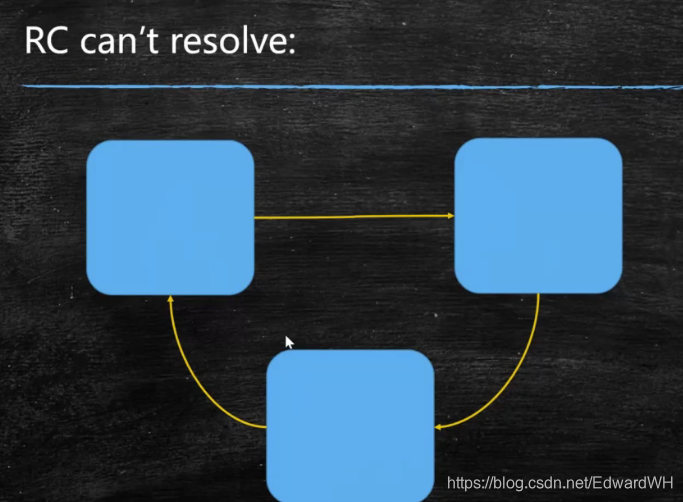
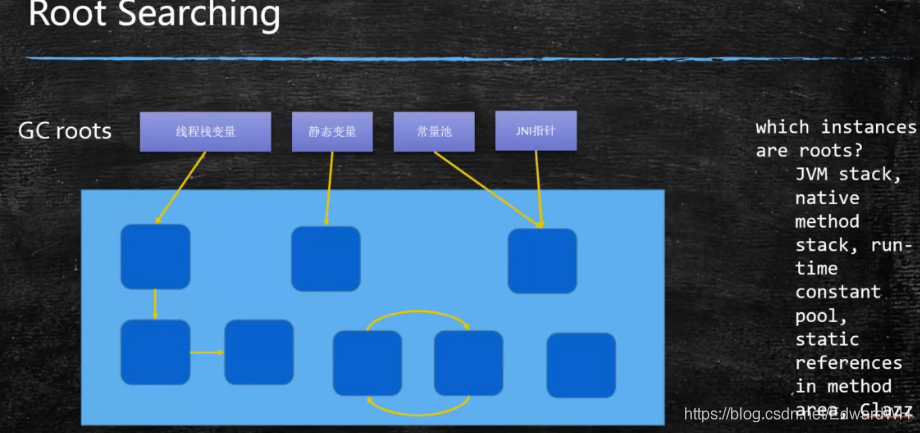
- 根可达算法(RootSearching) Hotspot
3.常见的垃圾回收算法
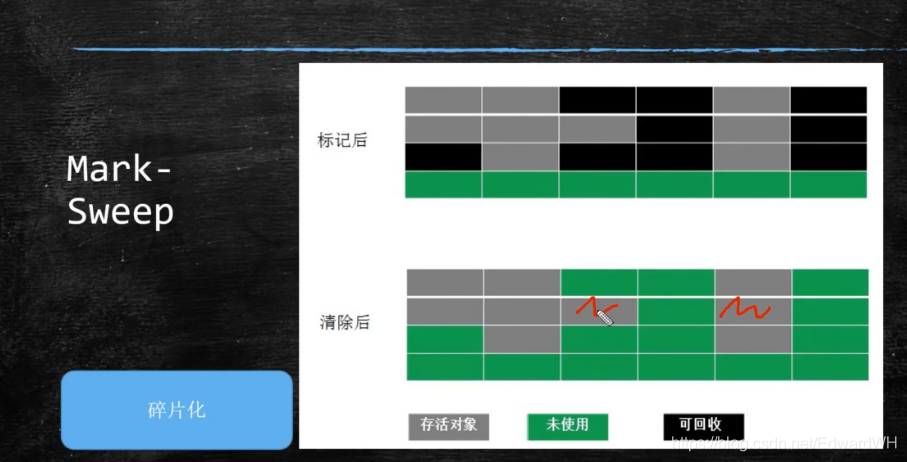
- 标记清除(mark sweep) - 位置不连续 产生碎片 效率偏低(两遍扫描)
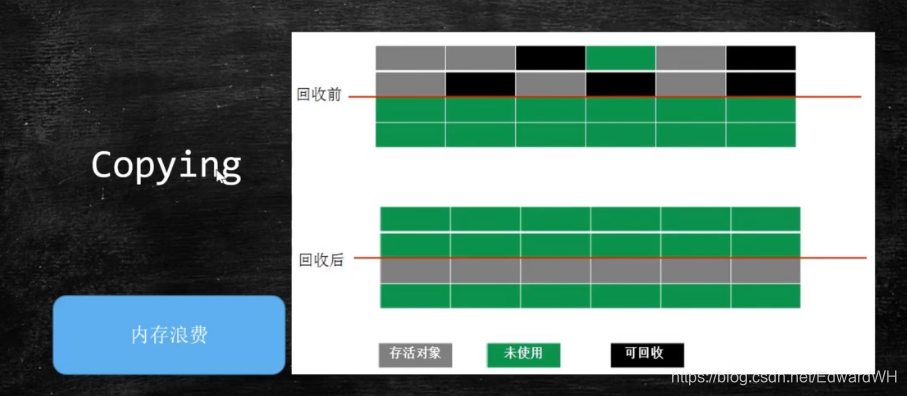
- 拷贝算法 (copying) - 没有碎片,浪费空间
- 标记压缩(mark compact) - 没有碎片,效率偏低(两遍扫描,指针需要调整)
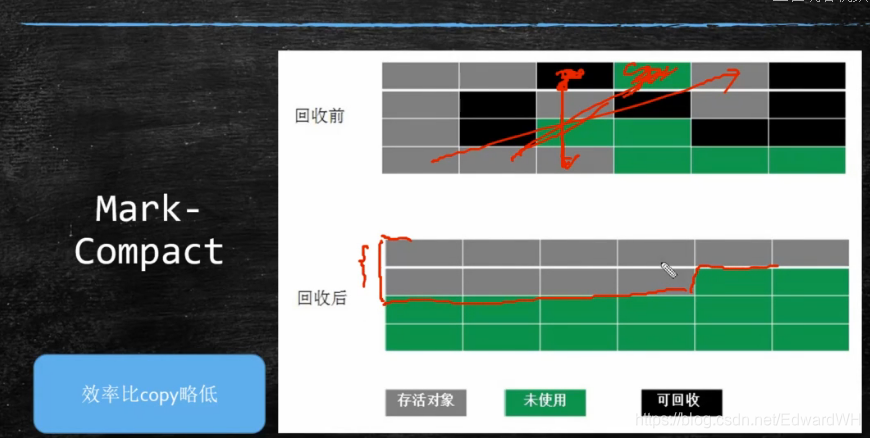
4.JVM内存分代模型(用于分代垃圾回收算法)
-
部分垃圾回收器使用的模型
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型
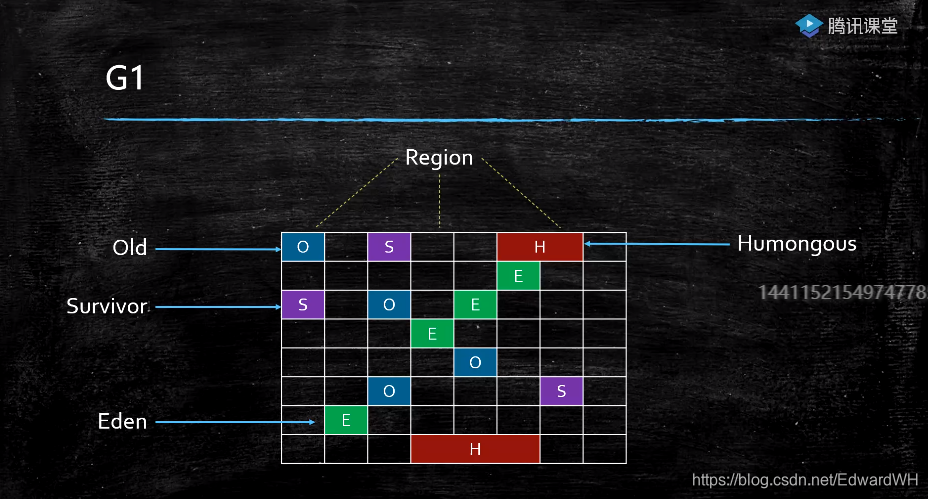
G1是逻辑分代,物理不分代
除此之外不仅逻辑分代,而且物理分代
-
新生代 + 老年代 + 永久代(1.7)Perm Generation/ 元数据区(1.8) Metaspace
- 永久代 元数据 - Class
- 永久代必须指定大小限制 ,元数据可以设置,也可以不设置,无上限(受限于物理内存)
- 字符串常量 1.7 - 永久代,1.8 - 堆
- MethodArea逻辑概念 - 永久代、元数据
-
新生代 = Eden + 2个suvivor区
- YGC回收之后,大多数的对象会被回收,活着的进入s0
- 再次YGC,活着的对象eden + s0 -> s1
- 再次YGC,eden + s1 -> s0
- 年龄足够 -> 老年代 (15 CMS 6)
- s区装不下 -> 老年代
-
老年代
- 顽固分子
- 老年代满了FGC Full GC

-
GC Tuning (Generation)
- 尽量减少FGC
- MinorGC = YGC
- MajorGC = FGC
-
对象分配过程图
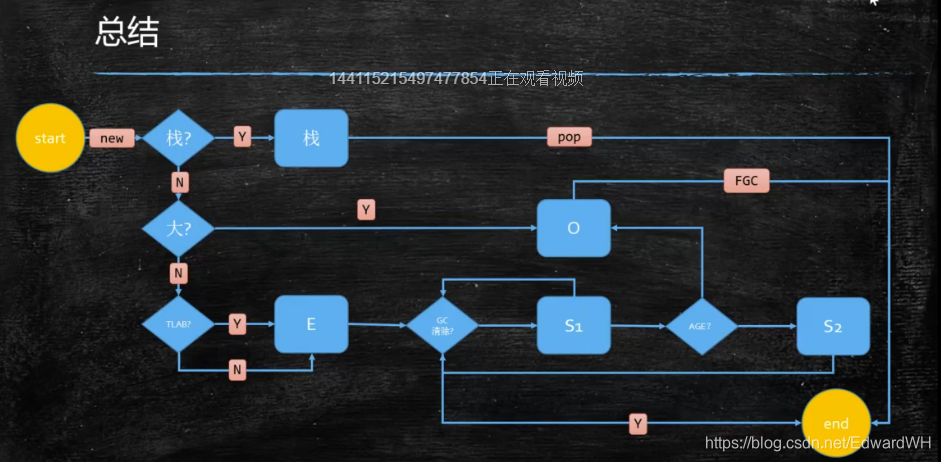
-
动态年龄:(不重要)
https://www.jianshu.com/p/989d3b06a49d -
分配担保:(不重要)
YGC期间 survivor区空间不够了 空间担保直接进入老年代
参考:https://cloud.tencent.com/developer/article/1082730
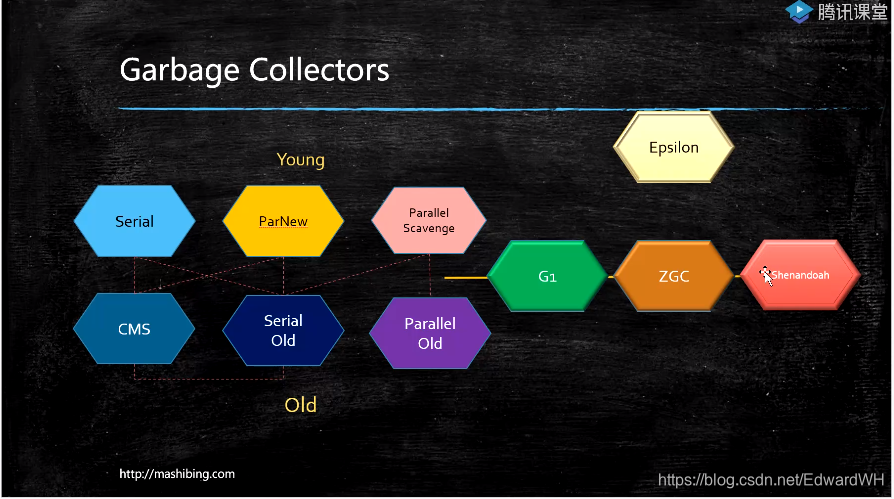
10种GC垃圾回收器
- 垃圾回收器的发展路线,是随着内存越来越大的过程而演进
从分代算法演化到不分代算法
Serial算法 几十兆
Parallel算法 几个G
CMS 几十个G - 承上启下,开始并发回收 -
.- 三色标记 - - JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS
并发垃圾回收是因为无法忍受STW - Serial 年轻代 串行回收
- PS 年轻代 并行回收
- ParNew 年轻代 配合CMS的并行回收
- SerialOld
- ParallelOld
- ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms)
CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定
CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收
想象一下:
PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW)
几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC
算法:三色标记 + Incremental Update - G1(200ms - 10ms)
算法:三色标记 + SATB - ZGC (10ms - 1ms) PK C++
算法:ColoredPointers + LoadBarrier - Shenandoah
算法:ColoredPointers + WriteBarrier - Eplison
- PS 和 PN区别的延伸阅读:
▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73 - 垃圾收集器跟内存大小的关系
- Serial 几十兆
- PS 上百兆 - 几个G
- CMS - 20G
- G1 - 上百G
- ZGC - 4T - 16T(JDK13)
1.8默认的垃圾回收:PS + ParallelOld
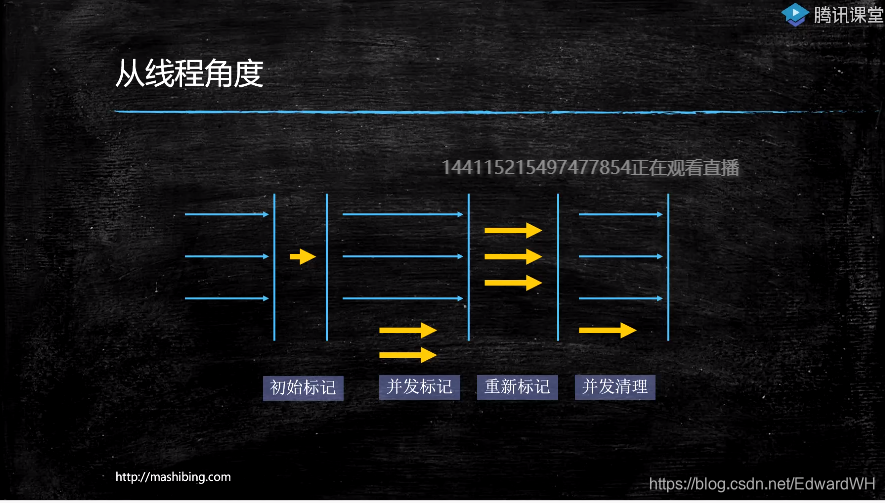
CMS工作的四个阶段:
main方法里的对象,是root对象,在初始的STP阶段,它们会被注有初始标记,它们会形成对象图,在工作过程中产生大量的垃圾。
在工作过程中,不需要STP,没用的垃圾会被标为并发标记。
重新标记,会STP来,重新标记,避免之前发生的漏标和错标。
最后,在并发过程中进行清理。
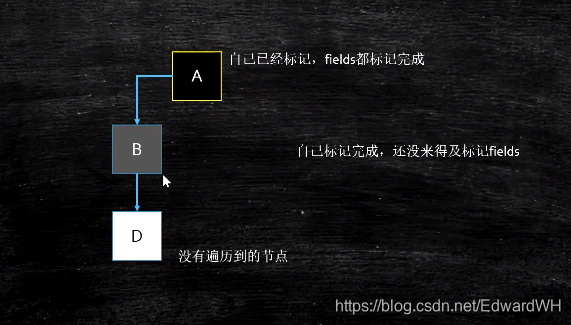
CMS和G1都是采用三色标记。
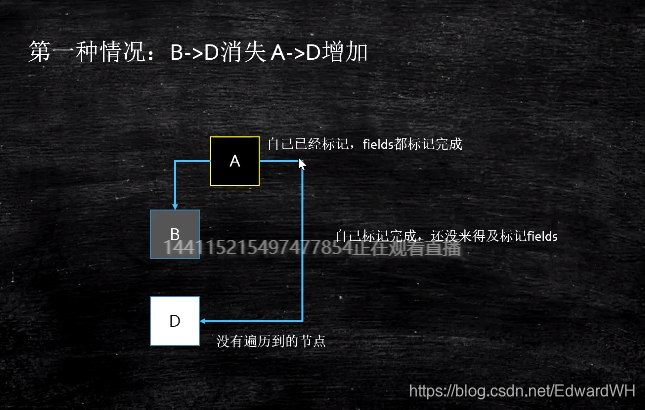
如上情况,D会被漏标。
CMS的解决方案:
Incremental Update
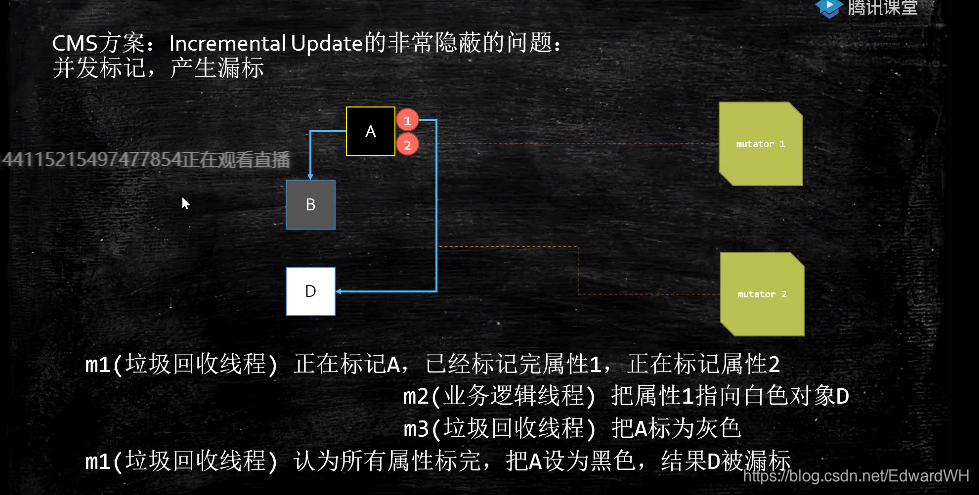
但是,并发状态下,依然会漏标。
G1(Garbage First)的解决方案:
Snapshot At the Begining
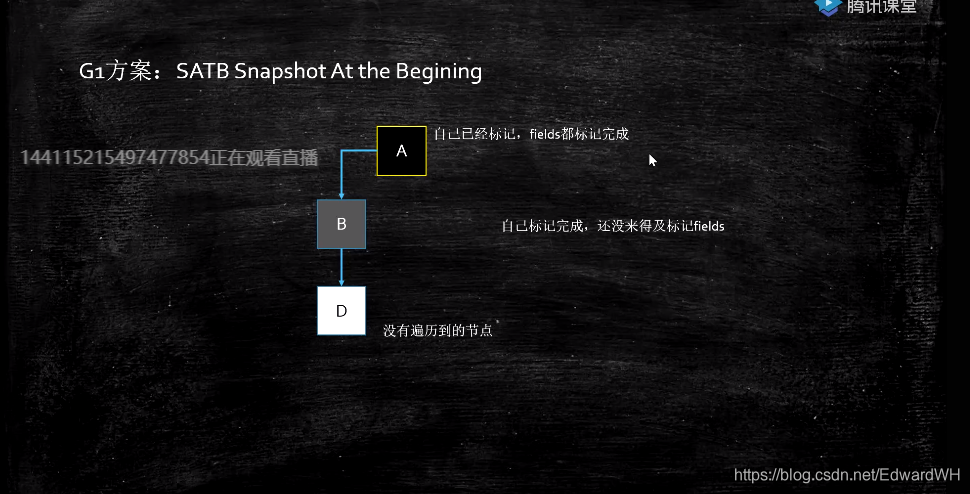
当B->D消失时,把这个引用推到了GC堆栈,保证还能被GC扫描到。
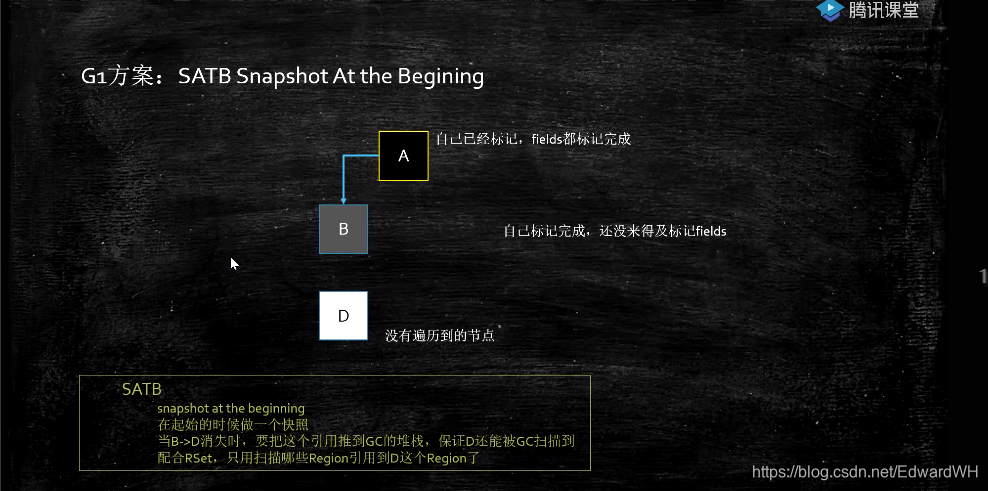
G1 Rset浪费空间,
ZGC:
性能强大,号称Zero Paused GC

常见垃圾回收器组合参数设定:(1.8)
-
-XX:+UseSerialGC = Serial New (DefNew) + Serial Old
- 小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
-
-XX:+UseParNewGC = ParNew + SerialOld
- 这个组合已经很少用(在某些版本中已经废弃)
- https://stackoverflow.com/questions/34962257/why-remove-support-for-parnewserialold-anddefnewcms-in-the-future
-
-XX:+UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old
-
-XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】
-
-XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
-
-XX:+UseG1GC = G1
-
Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC
- java +XX:+PrintCommandLineFlags -version
- 通过GC的日志来分辨
-
Linux下1.8版本默认的垃圾回收器到底是什么?
- 1.8.0_181 默认(看不出来)Copy MarkCompact
- 1.8.0_222 默认 PS + PO
JVM调优第一步,了解JVM常用命令行参数
-
JVM的命令行参数参考:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
-
HotSpot参数分类
标准: - 开头,所有的HotSpot都支持
非标准:-X 开头,特定版本HotSpot支持特定命令
不稳定:-XX 开头,下个版本可能取消
java -version
java -X
java -XX:+PrintFlagsWithComments //只有debug版本能用
- 区分概念:内存泄漏memory leak,内存溢出out of memory
- java -XX:+PrintCommandLineFlags HelloGC
- java -Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC HelloGC
PrintGCDetails PrintGCTimeStamps PrintGCCauses - java -XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags HelloGC
- java -XX:+PrintFlagsInitial 默认参数值
- java -XX:+PrintFlagsFinal 最终参数值
- java -XX:+PrintFlagsFinal | grep xxx 找到对应的参数
- java -XX:+PrintFlagsFinal -version |grep GC
- java -XX:+PrintFlagsFinal -version | wc -l
共728个参数
什么是调优
- 根据需求进行JVM规划和预调优
- 优化运行JVM运行环境(慢,卡顿)
- 解决JVM运行过程中出现的各种问题(OOM)
调优前的基础概念:
- 吞吐量:用户代码时间 /(用户代码执行时间 + 垃圾回收时间)
- 响应时间:STW越短,响应时间越好
所谓调优,首先确定,追求啥?吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量…
问题:
科学计算,吞吐量。数据挖掘,thrput。吞吐量优先的一般:(PS + PO)
响应时间:网站 GUI API (1.8 G1)
调优,从规划开始
-
调优,从业务场景开始,没有业务场景的调优都是耍流氓
-
无监控(压力测试,能看到结果),不调优
-
步骤:
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
- 吞吐量 = 用户时间 /( 用户时间 + GC时间) [PS]
- 选择回收器组合
- 计算内存需求(经验值 1.5G 16G)
- 选定CPU(越高越好)
- 设定年代大小、升级年龄
- 设定日志参数
- -Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
- 或者每天产生一个日志文件
- 观察日志情况
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
优化环境
- 有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G
的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G
的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了- 为什么原网站慢?
很多用户浏览数据,很多数据load到内存,内存不足,频繁GC,STW长,响应时间变慢 - 为什么会更卡顿?
内存越大,FGC时间越长 - 咋办?
PS -> PN + CMS 或者 G1
- 为什么原网站慢?
- 系统CPU经常100%,如何调优?(面试高频)
CPU100%那么一定有线程在占用系统资源,- 找出哪个进程cpu高(top)
- 该进程中的哪个线程cpu高(top -Hp)
- 导出该线程的堆栈 (jstack)
- 查找哪个方法(栈帧)消耗时间 (jstack)
- 工作线程占比高 | 垃圾回收线程占比高
- 系统内存飙高,如何查找问题?(面试高频)
- 导出堆内存 (jmap)
- 分析 (jhat jvisualvm mat jprofiler … )
- 如何监控JVM
- jstat jvisualvm jprofiler arthas top…
