k线系统优化项目背景
目前k线数据延迟率高,15分钟线及以上数据延迟高达5分钟以上,历史k线数据只能取到800条数据,无法一直取到800条以后的数据。由于k线系统是生成逻辑是通过数据库扫库的方式,一则延迟率高,二则增加了数据库的读取压力。
原方案
下图为现有k线数据产生处理逻辑,分别由kline job(k线计算生成任务),kline web api(api 接口服务)组成

- kline job(k线计算生成任务)
主要使用功能就是通过扫描存在数据库委托成功的订单,生产1分钟 k线数据,通过一分钟k线,从数据库取生成其他k线数据
- 入库
每30秒扫描fklinesource2数据,生产一分钟k线写入fklinebase2表
每2分钟扫描fklinebase2表数据,生产5分钟k线 写入fklinecycle2表
每5分钟扫描fklinebase2表数据,生产15、30、60分钟k线和日k周k写入fklinecycle2表 - redis缓存:
每隔1分钟从fklinecycle2表读取除一分钟以外的k线数据,写入reids
每隔40秒从fklinebase2表读取1分钟k线数据 写入redis
- kline web api(api接口服务)
为app、web客户端提供k线数据,数据实时从redis读取
优化方案
下图为优化后k线服务方案,分别由rabbit mq(实时推送成交单)、kline job(k线计算生成)、kline web api(对外提供接口服务)、infunxDB(时序数据库->持久化k线)
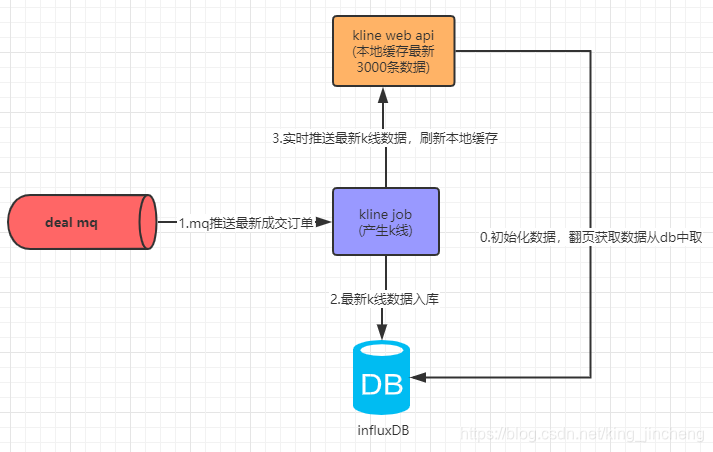
-
rabbit mq
实时推送最新成交委托,推送到kline job 消费 保证了成交数据的可靠性、及时性 -
kline job
- 接收 rabbit mq实时成交数据
- 实时计算生成k 线数据
- 计算得到的数据实时入库到influxdb
- 与kline web api 建立socket 连接 实时推送最新k线数据
-
influxdb
持久化k线数据,支持高并发写入数据。时序数据库排行榜top1 -
kline web api
初始时默认加载 3000条数据到内存数据,与kline job 建立socket 连接接收最新k线数据,保证内存中实时数据的准确性。当数据请求大于3000条数据时,从influxdb中读取历史数据,历史读取数据默认内存缓存5分钟,有效减少influxdb压力
优缺点对比
- 使用rabbit mq 推送成交订单的方式获取最新成交单,不需要通过扫库的方式 读取最新成交单,有效的提高了k线生产的实时性,降低对数据库的压力,无需多次 重复扫描
- 通过socket连接web api接口服务,缓存到系统内存,为客户端读取数据时可以有效的 实时获取到k线的变化
- 历史数据可以通过influxdb读取数据,突破了原方案只能读取800条数据的限制,可以看到更加多的历史数据
