DQL数据查询(重中之重点)
1.DQL:
(Data Query Language:数据查询语言)
·所有的查询都在用它:select。
·不论简单,复杂的查询,都可以做。
·数据库中最最核心,最重要的语言。
·数据库中使用频率最高的语言。
Select格式:
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
2.指定查询字段
格式:select 字段1,字段2…… from 表名
-- 查询表格信息:
-- select 字段 from 表名
select * from `student`; -- studnet 表的全部信息。
-- 查询指定字段
select `id`, `name` from `student`; -- studnet 表的id, name信息。
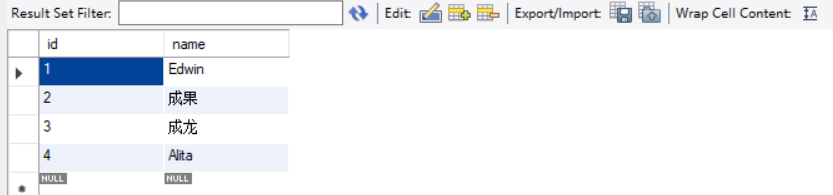
另命名
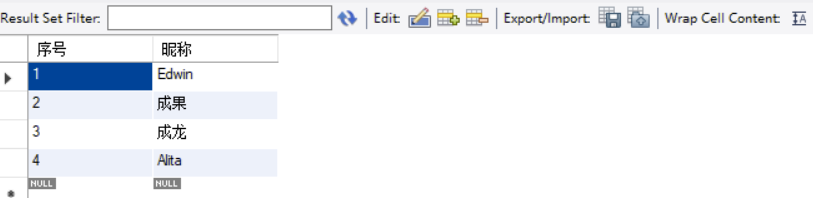
-- 重命名序列,或者表格,(即起别名)查询指定字段
select `id` as 序号, `name` as 昵称 from `student` as Table1;
-- studnet 表的id, name信息,分别叫序号,昵称。
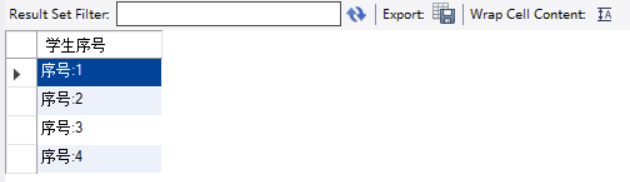
-- 调用函数 Concat(a,b)
select Concat('序号:',id) as 学生序号 from `student` as Table1;-- id前加“序号:”,列名叫“学生序号”
as:用于原数据库的列名不是很容易读懂,添加一个用户容易懂的。
去重复:
情景分析:一个用户仅有一个ID,但是可以申请多个账号在线时,想要调取用户的数目。
-- 查询一下某个数据库中用户
SELECT * FROM User; -- 会查询用户全部的信息
SELECT `UserNo` FROM User; -- 查询有哪些用户在线,
SELECT DISTINCT `UserNo` FROM User; -- 发现重复数据,通过ID去重,重复用户信息只显示一次
--用户使用时长+ 1 小时查看
SELECT `UserTime` +1 AS '加时后’FROM User
数据库的列(表达式)
-- 查询版本号。(调用函数)
select version();
-- 用来计算数学式(调用表达式)
select 7*77-777 as output;
-- 查询自增的步长(调用变量)
select @@auto_increment_increment
3.Where条件字句
作用:检索符合条件的值。
搜索条件是由一个或多个表达式组成。结果为布尔值。
逻辑运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and 或 && | a and b 或 a && b | 逻辑与,两个都true,结果才true |
| or 或 || | a or b 或 a || b | 逻辑或,其中一个true,结果就true |
| Not 或 ! | not a 或 !a | 逻辑非,假作真时真亦假 |
And/&&
-- id 在1到3之间
select `id`, `name` from `student` where id>=1 and id <=3;
select `id`, `name` from `student` where id>=1 && id <=3;
select `id`, `name` from `student` where id between 1 and 3;
Or/||
-- id 在1或3
select `id`, `name` from `student` where id>=1 or id <=3;
select `id`, `name` from `student` where id>=1 || id <=3;
Not/!
-- id 不是3的
select `id`, `name` from `student` where id != 3;
select `id`, `name` from `student` where not id = 3;
模糊查询:比较运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| Is Null | A is null | 如果操作符为Null,则结果为真 |
| Is Not Null | B is not null | 如果操作符不为Null,则结果为真 |
| Between | A | 如果C在D和E之间,则结果为真 |
| Like | F like G | SQL匹配,如果F匹配G,则结果为真 |
| In | H in (H1,H2,H3…) | 假设H为H1,H2,H3……中某一个值,则结果为真 |
1.like:
-- 查询名字以A开头的用户,
-- like结合%,(%代表0到任意个字符,不定数目)(_代表一个字符)
select `id`, `name` from `student` where name like 'A%';
-- 查询名字以成开头的用户,且姓后只有一个字;下划线代表。
select `id`, `name` from `student` where name like '成_';
-- 查询姓刘的同学,名字后面只有两个字的;两个下划线代表。
select `id`, `name` from `student` where name like '成__';
-- 查询名字中代“龙”的用户
select `id`, `name` from `student` where name like '%龙%';
2.in:
-- In 的使用,注意:in()的括号里是确定的值,不能用%或_来代替。
-- 查询用户ID在4到7之间的
select `id`, `name` from `student` where id in(4,5,6,7);
select `id`, `name` from `student` where address in('中国','荷兰');
3.null/not null:
-- null 和 not null
select `id`, `name` from `student`
where birthday is null or address is null or email is null;
-- 查询某项存在的用户 ->计算机思维:非空
select `id`, `name` from `student`
where birthday is not null;
-- 查询某项存不在的用户 ->计算机思维:空
select `id`, `name` from `student`
where email is null;
4.连表查询:Join
七种Join理论:(了解)

情景分析:
表格1,:员工信息表,具有姓名,性别,出生年月,详细住址,电子邮箱,等信息。
表格2,:项目表,具有项目简介,成员组成,项目详细计划,等信息。
要求输出:员工姓名,员工性别,员工出生年月,员工参与项目,项目详情。
思路:
1.分析需求,分析查询的字段来自哪些表(连接查询)
2.确定使用哪种连接查询?(在7种里面选择)
3.确定交叉点(这两个表中哪个数据是相同的)
判断的条件: 员工表的中 StaffNo = 项目表StaffNo
1.Inner Join
格式:左表 inner join 右表
Select S.StaffNo,StaffName,StaffSex,StaffProject,ProjectDetails
-- 不明确S.StaffNo会报错,原因即为不明确所查找项目
from Staff as S -- 简称为S
inner join Project as P -- 简称为P
where S.StaffNo = P.StaffNo
2.Right Join
格式:左表 right join 右表
Select S.StaffNo,StaffName,StaffSex,StaffProject,ProjectDetails
-- 不明确S.StaffNo会报错,原因即为不明确所查找项目
from Staff S -- 简称为S,as可以省略
right join Project P -- 简称为P,as可以省略
on S.StaffNo = P.StaffNo -- Where 和 On的效果相同,都是用来判断条件的。
3.Left Join
格式:左表 left join 右表
Select S.StaffNo,StaffName,StaffSex,StaffProject,ProjectDetails
-- 不明确S.StaffNo会报错,原因即为不明确所查找项目
from Staff S -- 简称为S,as可以省略
left join Project P -- 简称为P,as可以省略
on S.StaffNo = P.StaffNo -- Where 和 On的效果相同,都是用来判断条件的。
| 操作 | 描述 |
|---|---|
| inner join | 如果联合表中有一个存在即可,就返回结果。 |
| left join | 即使右表中没有匹配,也会从左表中返回结果 |
| right join | 即使左表中没有匹配,也会从右表中返回结果 |
左连接:以左表为基准。右链接:以右表为基准。
4.附加条件
Select …… from …… join …连接的表… where / on + 判断条件 ( where + 附加条件)
join …连接的表… on …判断条件… 是一个固定格式,称作连接查询,
where判断条件,称作等值查询。
一个查询语句,只能有一个where条件。
Eg:
Select S.StaffNo,StaffName,StaffSex,StaffProject,ProjectDetails
from Staff S
left join Project P
on S.StaffNo = P.StaffNo
where StaffNo between 7 and 77;
5.多连表
除了以上两个表的信息,还需要调用项目运行中的用户姓名和联系方式。
现在需要三表链接。
Select S.StaffNo,StaffName,StaffSex,StaffProject,ProjectDetails,UserName,UserPhone
from Staff S
right join Project P
on S.StaffNo = P.StaffNo
inner join User U
on U.ProjectNo = P.ProjectNo;
小结:
我要查询哪些数据 select ……
从那几个表中查FROM表 xxx Join 连接的表 on 交叉条件
假设存在一种多张表查询,慢慢来,可以先查询两张表,然后再慢慢增加。
5.自连接
自己的表和自己的表连接,核心:一张表拆分成两个一样的表来用。
-- 范例表:
CREATE TABLE `category` (
`categoryid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主题id',
`pid` INT(10) NOT NULL COMMENT '父id',
`categoryName` VARCHAR(50) NOT NULL COMMENT '主题名字',
PRIMARY KEY (`categoryid`)
) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
-- 插入数据
INSERT INTO `category` (`categoryid`, `pid`, `categoryName`) VALUES
('2','1','信息技术'),
('3','1','软件开发'),
('4','3','数据库'),
('5','1','美术设计'),
('6','3','web开发'),
('7','5','ps技术'),
('8','2','办公信息');
父类:
| categoryid | categoryName |
|---|---|
| 2 | 信息技术 |
| 3 | 软件开发 |
| 5 | 美术设计 |
子类:
| pid | categoryid | categoryName |
|---|---|---|
| 3 | 4 | 数据库 |
| 2 | 8 | 办公信息 |
| 3 | 6 | web开发 |
| 5 | 7 | ps技术 |
操作:查询父子对应关系。
| 父类 | 子类 |
|---|---|
| 信息技术 | 办公信息 |
| 软件开发 | 数据库 |
| 软件开发 | web开发 |
| 美术设计 | ps技术 |
代码实现:
select a.categoryName as '父栏目',b.categoryName as '子栏目'
from category as a,category as b
where a.categoryid = b.pid;
同一个表,在as了不同的名字后,就被视为不同的表格来处理。
6.排序(Order by)和分页(limit)
排序:
升序:ASC 降序:DESC
SELECT id,name,pwd,sex
FROM school.student
-- join ……
-- where ……
order By id desc;

分页:
形如:

目的:
环节数据库的压力,给人更好的使用体验。
相对应,有一种“瀑布流”的页面方法,形如:百度图片,抖音视频等。

加载后可以一同展示给用户。
格式: limit + 初始值 + 页面大小
Eg:同上的排序一样的数据库,开启分页,每页只显示3个数据。
limit 0,3 ——>页面里含有1-3。
SELECT id,name,pwd,sex
FROM school.student
-- join ……
-- where ……
order By id desc
limit 0,3;
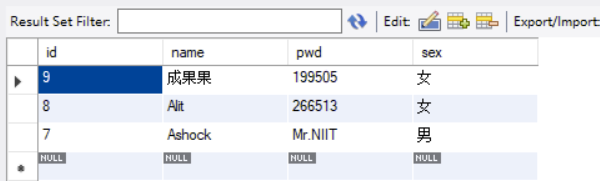
limit 1,3 ——>页面里含有2-4。
SELECT id,name,pwd,sex
FROM school.student
-- join ……
-- where ……
order By id desc
limit 1,3;
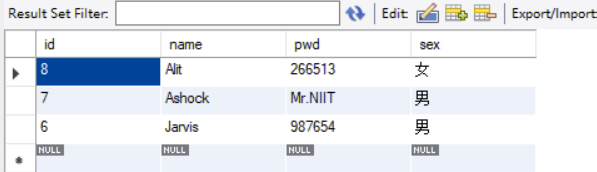
limit 3,3 ——>页面里含有4-6。
SELECT id,name,pwd,sex
FROM school.student
-- join ……
-- where ……
order By id desc
limit 3,3;
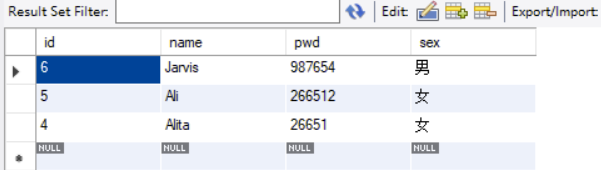
网页分页的作用:
显示当前页,总页数,每个页面的大小。
eg:每个页面5条
第一页 limit 0 ,5
第二页 limit 5 ,5
第三页 limit 10,5
……
第N页 limit (n-1)*pagesize,pagesize
– pagesize:页面的大小
– (n-1)*pagesize:起始值
– n:当前页码
– 数据总数/页面大小 = 总页数。
7.子查询
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
简单的讲,就是where判断的条件,是需要计算得出的。其本质就是在where语句中嵌套一个子查询语句。
格式: where(select …… form ……)
情景分析:
表格1,Student:学生表,包含学生姓名,学号,年龄,性别,住址等。
表格2,Result:成绩表,包含学生学号,科目,成绩等。
表格3,Subject,课程表,包含课程id,课程名,以及课时等。
范例1:查询“数据结构-1”的所有考试结果,要求输出:学号,课程编号,成绩,等。进行降序排列。
1.0常规查询。
select r.SubjectNo,StudentNo,StudentResult -- 注意不要形成模棱两可的 SubjectNo
from result r
inner join subject sub
on r.SubjectNo = sub.SubjectNo
where SubjectName = '数据结构-1'
order by StudentResult Desc;
2.0子查询。
select StudentNo,SubjectNo,StudentResult
from result
where SubjectNo = (
select SubjectNo from subject
where SubjectName = '数据结构-1'
);
-- 原本应该使用result.SubjectNo = subject.SubjectNo,
-- 此处直接使用result的序号,与查询所有带“数据结构-1”的学生学号相等的方法。
查询所有带“数据结构-1”的学生学号。
select StudentNo from subject where SubjectName = '数据结构-1'
范例2:查询分数不少于80分的同学。
1.0常规查询
select distinct s.StudentNo,StudentName,StudentResult
from student s
inner join result r
on r.StudentNo = s.StudentNo
where StudentResult > 80;
2.0子查询,在“1.0”的基础上,增加一个科目,查询的学科为:高等数学-2。
select distinct s.StudentNo,StudentName
from studnt s
inner join result r
on r.StudentNo = s.StudentNo
where StudentResult > 80 and SubjectNo = (
select SubjectNo from subject
where SubjectName = '高等数学-2'
);
3.0改造“2.0”,使用双重子查询
此方法的查询顺序是由里及外的,类似于一层一层地拨白菜。
select StudentNo,StudentName from student where StudentNo in(
select StudentNo from result where StudentResult > 80 and SubjectNo = (
select SubjectNo from subject where SubjectName = '高等数学-2'
)
)
8.分组和过滤
情景分析:
成绩表Result中含有:学生姓名,学号,科目,成绩等。
输出每个科目的名称,平均值,最大值,最小值。
-- 查询不问课程的平均分,最高分,最低分,平均分大于80
--核心: (根据不同的课程分组)
SELECT subjectName, AVG(StudentResult) AS平均分,MAX(StudentResult) AS最高分,MIN(StudentResult) AS
最低分
FROM result r
INNER JOIN subject sub
ON r.SubjectNo = sub.SubjectNo
GROUP BY r.subjectNo -- 通过什么字段来分组
-- 如果需要判断均分大于80的,使用在GROUP BY前的where是会报错的,进行分组后的条件判断使用having,如下:
HAVING 平均分 > 80
9.Select 小结
select 的查询,最重要的一点是要注意语句的先后顺序。
Select格式:
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
中文分析:
select 去重复 查询字段 from 查询表--(查询字段和查询表均可起别名)
XXX join XXX(要连接的表) on 等值判断
where (具体的条件值,或字查询语句)
group by (通过某个字段来分组)
having (过滤分组后的信息,通过此条件来再次细分,条件等价于where ,只是位置不同)
order by (通过某个字段来排序,升/降)
limit,startlndex,pagesize...
参考文献
《【狂神说Java】MySQL最新教程通俗易懂》
2020.05.14
