什么是kafka?
我们先看一下维基百科是怎么说的:
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。看完这个说法,是不是有点一脸蒙蔽,
再看看其他大神的理解:Kafka 是由 Linkedin 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
总的来说就是他就是发布订阅消息的引擎系统,在做集群的时候需要依靠zookeeper。
kafka的术语
- topic(主题): 用来对消息分类,每一个进入kafka的消息都会被放入某一个topic下
- 通俗理解一下:比如说是我们的业务系统有一个流程是,顾客买了东西需要给顾客发送一个电子优惠卷,将发优惠卷和完成这个订单流程我们做一个异步操作,我们使用kafka 将这个订单的消息发给kafka,发优惠卷模块来消费这个队列。那这个发优惠卷订单消息都在同一个topic里。消费者也就从这个topic进行消费
- Broker 用来实现数据存储的主服务器
- 当我们把订单信息发送到队列中的时候,kafka会将这个消息分批次此久化,消息发送给page cache 然后broker一批一批的进行存储
- partition(分区) 每个topic中的消息会被分为若干个partition,以提高消息的处理速度还有就是容错能力
- 当我们把订单消息抛给kafka时我们会定义一个主题其还会定义一个分区,或者说是一个分区算法。也就是将topic这个主题队列分成N个队列。
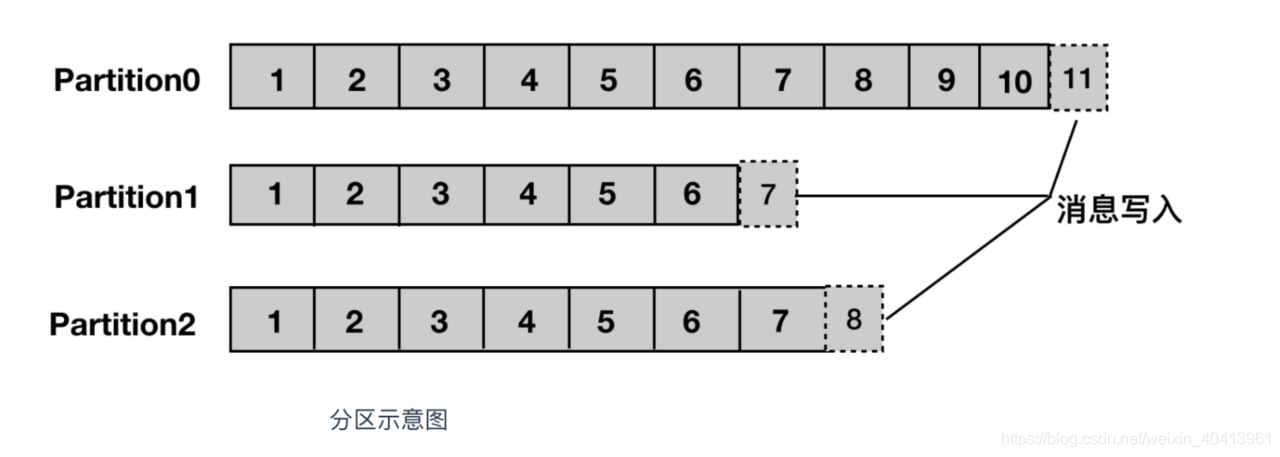
- 当我们把订单消息抛给kafka时我们会定义一个主题其还会定义一个分区,或者说是一个分区算法。也就是将topic这个主题队列分成N个队列。
- producer (消息生产者):订单消息发送者就是生产者
- consumer (消息消费者):优惠券发送模块就是消费者,消费订单消息生成优惠券
- consumer group : 生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。
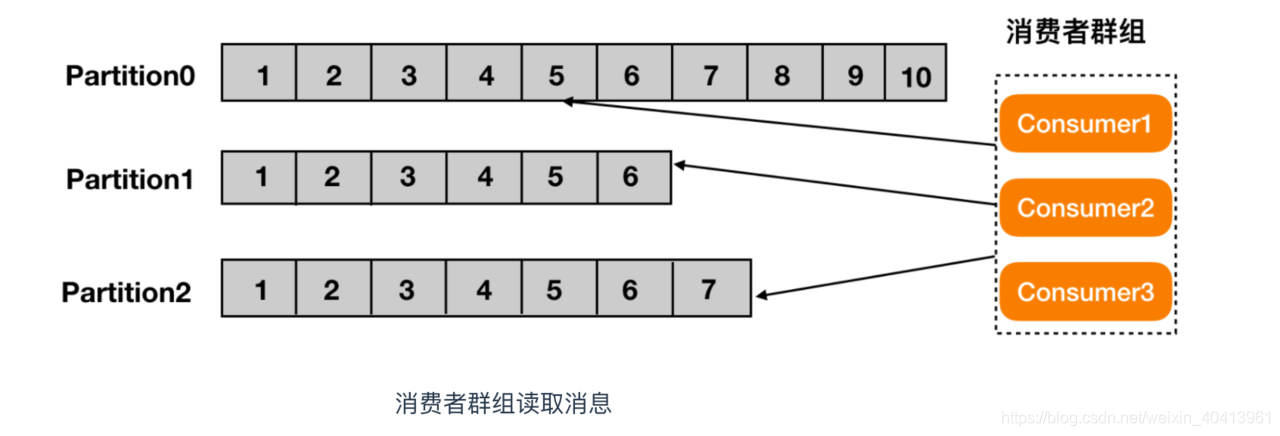
kafka的消息队列
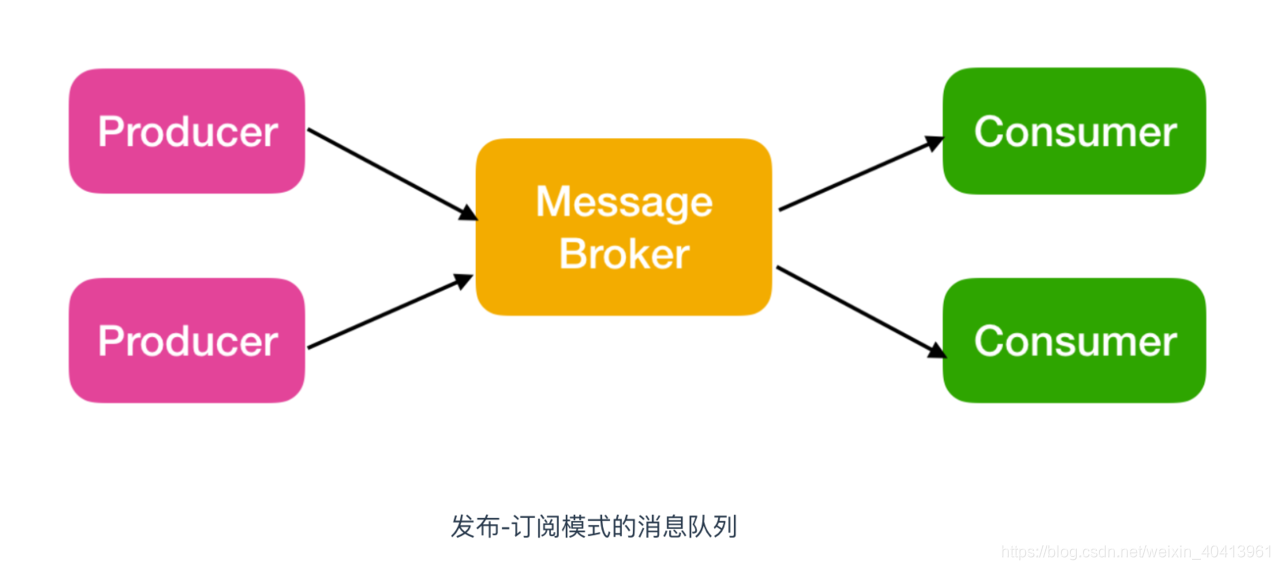
kafka的消息队列分为两种:
- 点对点模式(生产者的消息只由一个用户来消费)

- 发布订阅模式(一个生产者或者多个生产者对应一个或者多个消费者(消费者群组))
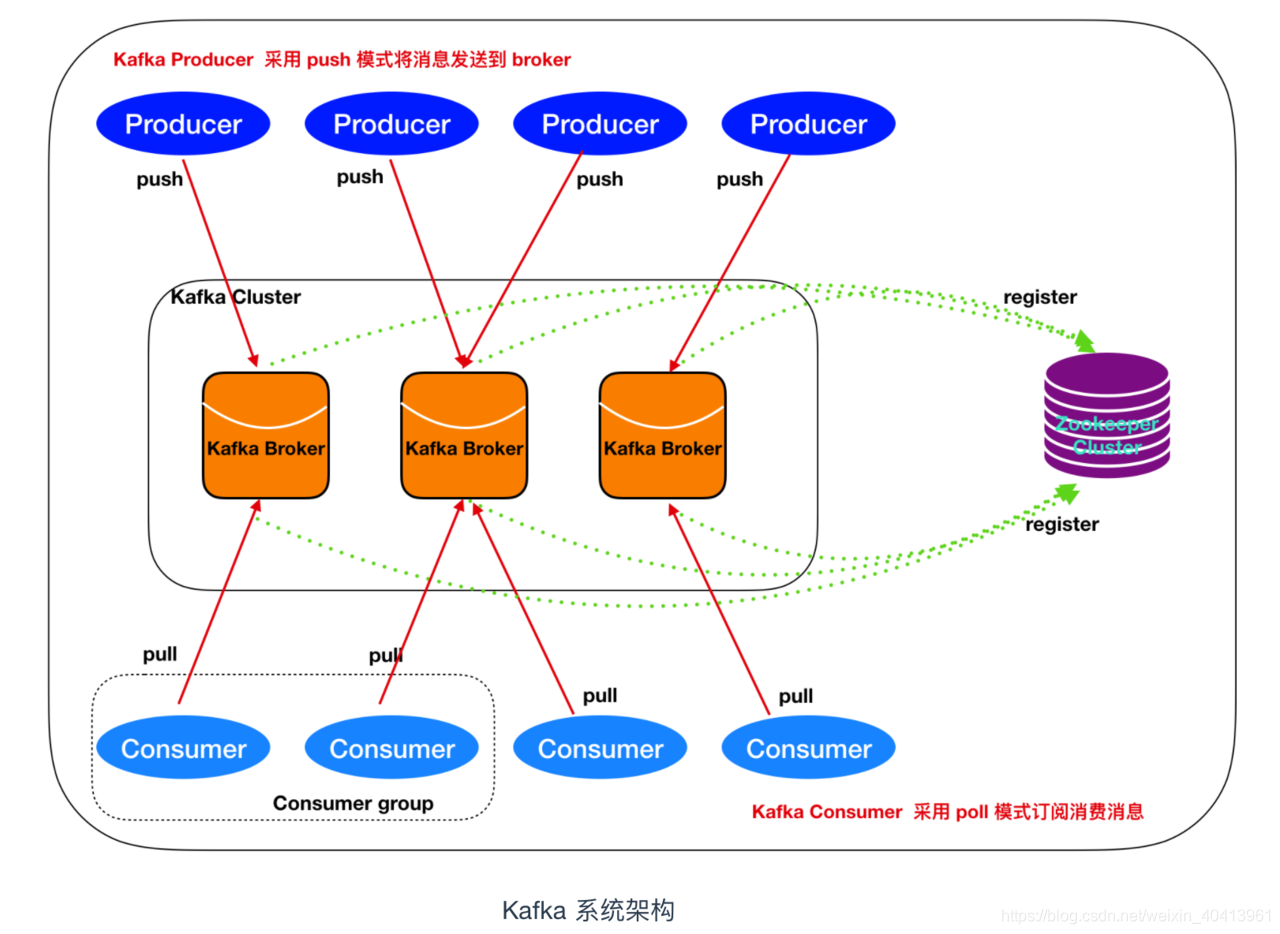
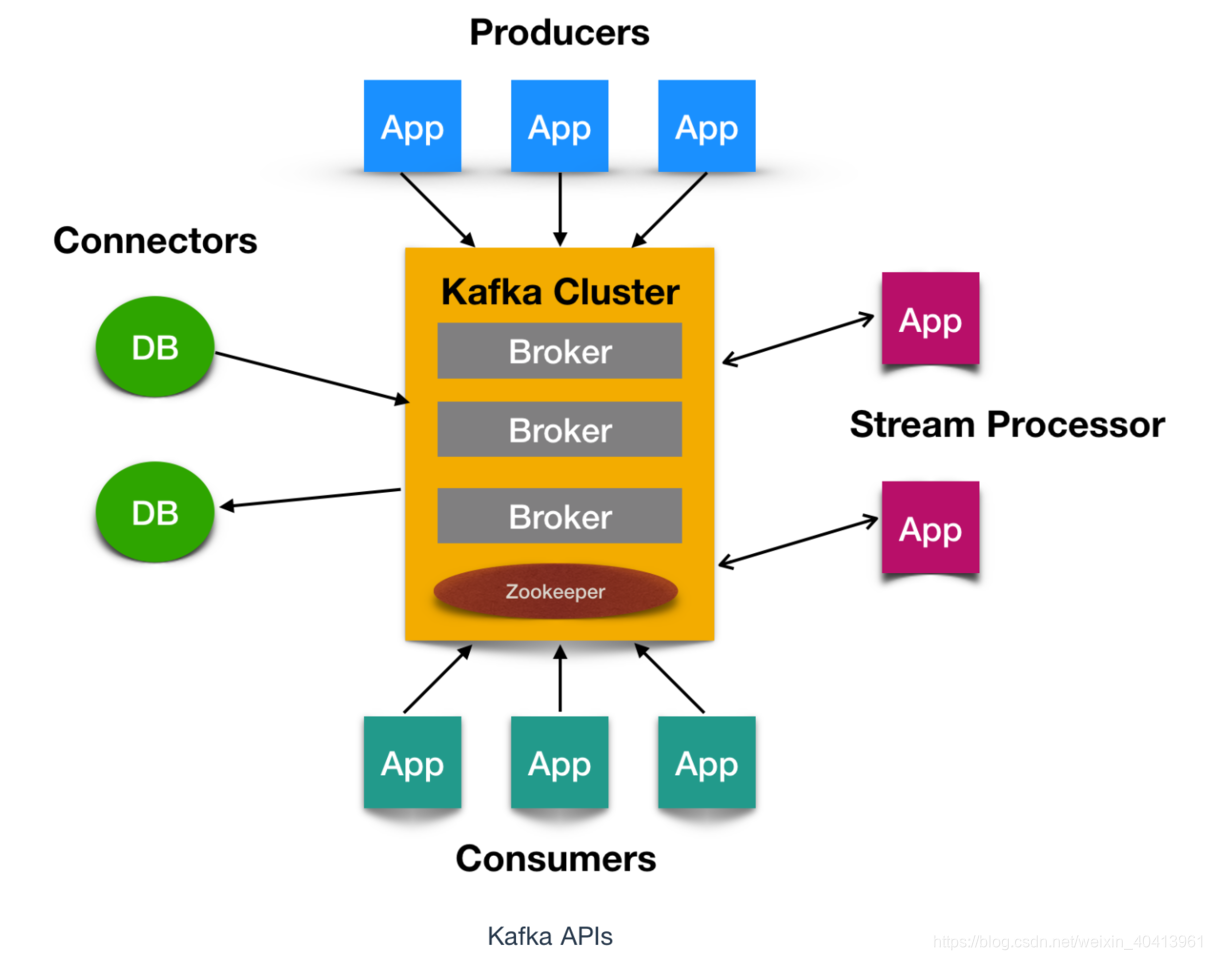
kafka的系统架构图
kafka核心API
核心 API
Kafka 有四个核心API,它们分别是
- Producer API,它允许应用程序向一个或多个 topics 上发送消息记录
- Consumer API,允许应用程序订阅一个或多个 topics 并处理为其生成的记录流
- Streams API,它允许应用程序作为流处理器,从一个或多个主题中消费输入流并为其生成输出流,有效的将输入流转换为输出流。
- Connector API,它允许构建和运行将 Kafka 主题连接到现有应用程序或数据系统的可用生产者和消费者。例如,关系数据库的连接器可能会捕获对表的所有更改
kafka 设计特性
- 高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
- 高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
- 持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储。
- 容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
- 高并发: 支持数千个客户端同时读写
参考:https://juejin.im/post/5ddf5659518825782d599641#heading-21
https://baike.tw.wjbk.site
