决策树模型是一种很简单但是却很经典的机器学习模型,经历多次的改进和发展,现在已经有很多成熟的树模型,比如早期的ID3算法、现在的C45模型、CART树模型等等,决策树一个很大的优点就是可解释性比较强,当然这也是相对于其他模型来说的,决策树模型在训练完成后还可以通过绘制模型图片,详细了解在树中每一个分裂节点的位置是使用什么属性进行的,本文是硕士论文撰写期间一个简单的小实验,这里整理出来,留作学习记录,下面是具体的实现:
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能:使用决策树模型来对鸢尾花数据进行分析预测
绘制DT模型
'''
import os
import csv
import csv
from sklearn.tree import *
from sklearn.model_selection import train_test_split
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
import pydotplus
from sklearn.externals.six import StringIO #生成StringIO对象
import graphviz
os.environ["PATH"]+=os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/'
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
def read_data(test_data='fake_result/features_cal.csv',n=1,label=1):
'''
加载数据的功能
n:特征数据起始位
label:是否是监督样本数据
'''
csv_reader=csv.reader(open(test_data))
data_list=[]
for one_line in csv_reader:
data_list.append(one_line)
x_list=[]
y_list=[]
label_dict={'setosa':0,'versicolor':1,'virginica':2}
for one_line in data_list[1:]:
if label==1:
biaoqian=label_dict[one_line[-1]]
#biaoqian=int(one_line[-1])
y_list.append(int(biaoqian)) #标志位
one_list=[float(o) for o in one_line[n:-1]]
x_list.append(one_list)
else:
one_list=[float(o) for o in one_line[n:]]
x_list.append(one_list)
return x_list, y_list
def split_data(data_list, y_list, ratio=0.30):
'''
按照指定的比例,划分样本数据集
ratio: 测试数据的比率
'''
X_train, X_test, y_train, y_test = train_test_split(data_list, y_list, test_size=ratio, random_state=50)
print '--------------------------------split_data shape-----------------------------------'
print len(X_train), len(y_train)
print len(X_test), len(y_test)
return X_train, X_test, y_train, y_test
def DT_model(data='XD_new_encoding.csv',rationum=0.20):
'''
使用决策树模型
'''
x_list,y_list=read_data(test_data=data,n=1,label=1)
X_train,X_test,y_train,y_test=split_data(x_list, y_list, ratio=rationum)
DT=DecisionTreeClassifier()
DT.fit(X_train,y_train)
y_predict=DT.predict(X_test)
print 'DT model accuracy: ', DT.score(X_test,y_test)
dot_data=StringIO()
export_graphviz(DT,out_file=dot_data,class_names=iris.target_names,feature_names=iris.feature_names,filled=True,
rounded=True,special_characters=True)
graph=pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('iris_result.png')
if __name__ == '__main__':
DT_model(data='iris.csv',rationum=0.30)
输出结果为:
--------------------------------split_data shape----------------------------------- 105 105 45 45 DT model accuracy: 0.9555555555555556 [Finished in 1.6s]
其中,iris.csv是sklearn中的鸢尾花数据,具体的保存方法在我之前的博客中已经有了,感兴趣的话可以看一下
DT模型如下:
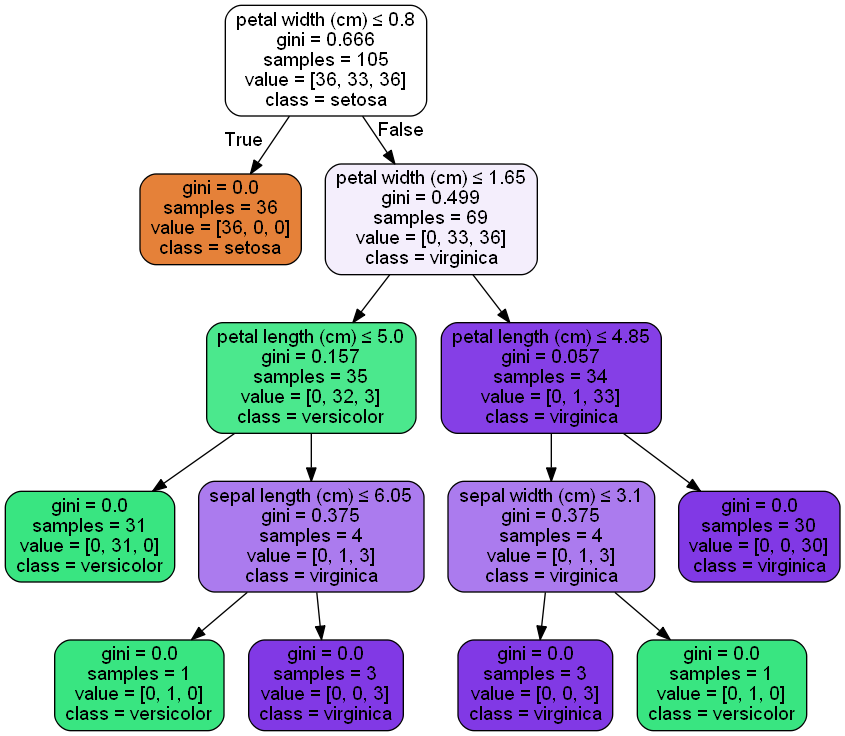
直观看起来还是挺漂亮的,仔细看的话足够清晰了,对于详细分析数据而言是很有帮助的。
下面是决策树模型图构建过程中的原始数据
digraph Tree {
node [shape=box] ;
0 [label="X[3] <= 0.8\ngini = 0.666\nsamples = 105\nvalue = [36, 33, 36]"] ;
1 [label="gini = 0.0\nsamples = 36\nvalue = [36, 0, 0]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="X[3] <= 1.65\ngini = 0.499\nsamples = 69\nvalue = [0, 33, 36]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
3 [label="X[2] <= 5.0\ngini = 0.157\nsamples = 35\nvalue = [0, 32, 3]"] ;
2 -> 3 ;
4 [label="gini = 0.0\nsamples = 31\nvalue = [0, 31, 0]"] ;
3 -> 4 ;
5 [label="X[0] <= 6.05\ngini = 0.375\nsamples = 4\nvalue = [0, 1, 3]"] ;
3 -> 5 ;
6 [label="gini = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
5 -> 6 ;
7 [label="gini = 0.0\nsamples = 3\nvalue = [0, 0, 3]"] ;
5 -> 7 ;
8 [label="X[2] <= 4.85\ngini = 0.057\nsamples = 34\nvalue = [0, 1, 33]"] ;
2 -> 8 ;
9 [label="X[1] <= 3.1\ngini = 0.375\nsamples = 4\nvalue = [0, 1, 3]"] ;
8 -> 9 ;
10 [label="gini = 0.0\nsamples = 3\nvalue = [0, 0, 3]"] ;
9 -> 10 ;
11 [label="gini = 0.0\nsamples = 1\nvalue = [0, 1, 0]"] ;
9 -> 11 ;
12 [label="gini = 0.0\nsamples = 30\nvalue = [0, 0, 30]"] ;
8 -> 12 ;
}
如果需要pdf版本的模型图也可以,下面是生成的PDF数据(因无法上传文件,这里添加的图片的后缀名,使用时直接删除图片后缀即可)

扫描二维码关注公众号,回复:
1122106 查看本文章
