Map
HashMap
HashMap KV键值对 数据结构见下图。HashMap的插入的过程是首先计算key的hash值然后跟数组长度做 与运算 得到一个索引值
插入数组的这个索引值进去,如果当前这个索引值没有node直接CAS插入,如果当前这个有node就是发生了hash碰撞之后就加synchronized的锁在链表后面加入这个node或者红黑树加这个node。
1.8的HashMap的数据结构就是 数组 + 链表 + 红黑树 在链表长度超过8的时候并且map的size超过64的时候会转换成红黑树。
链表转红黑树不是单向的,在红黑树的节点小于6的情况下会从红黑树转换成链表,这个操作在扩容(resize)的时间进行。
链表转换红黑树逻辑
// 链表转红黑树的阈值
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转回链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 转红黑树对size最小的要求
static final int MIN_TREEIFY_CAPACITY = 64;
为什么要从红黑树转回链表这个我也不懂?有懂的大佬也可以评论区解析下。
红黑树的特性
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。[这里指到叶子节点的路径]
补充一些概念
- hash值相等的equals不一定相等。
- equals相等的话hash这个一般来说一定要相等,除非你乱搞。
- hashMap 没有put之前都是不会创建对应的node节点的,算是中lazy加载吧。
- 默认的加载因子是0.75 这个东西没啥事就别改了。
- hashmap的扩容机制1.7跟1.8的也是不一样。1.7的扩容从旧的移动到新的数组然后重新计算hash值。
扩容机制
1.7的扩容机制
扩容的时候需要重新Hash取模然后再重新放入新的数组里面
1.8的扩容机制
用一位来确定是在原地位置还是原地+OldCap位置 扩容参考
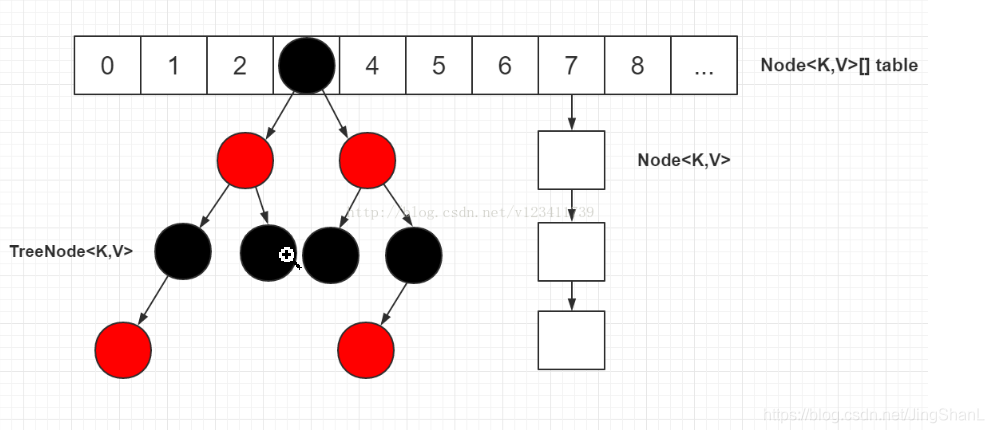
HashMap数据结构图
Hashtable
这个就很厉害了,都是synchronized基本上所有对外的方法的搞得性能很低不建议用。
ConcurrentHashMap
这个东西讲起来就更厉害了,HashMap是不安全的这个是一个安全的Map。那他这个比HashTable强在哪里呢?
读是没有加锁的可以并发的去读取,put的时候 synchronized + CAS 去掉了1.7的分段锁这种概念,如果索引到的数组上为null直接CAS插入如果有值则加synchronized 然后进行插入,插入的时候不允许key为null 或者value为null 。1.8的锁粒度是非常小类似mysql的行数,它也是只锁定了一个node节点。所以并发操作性能很高。
因为是分段锁 插入、读取、更新都是可以并发执行但是有些要锁住全局的size()和containsValue()
为什么放弃ReentrantLock(1.7的分段锁)用synchronizedConcurrentHashMap 1.8为什么要使用CAS+Synchronized取代Segment+ReentrantLock
initTable()方法
/**
* 用于控制table初始化和resize的参数
* -1表示初始化
* 其他负数+1表示正在进行resize的线程数,为了与-1区别开
* 0代表默认状态
* 在初始化之后,该值表示下次需要resize时map内元素的个数
*/
private transient volatile int sizeCtl;
// 初始化时与sizeCtl值相等,为0
private static final long SIZECTL;
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
// 如果正在初始化中当前线程做出让步
Thread.yield(); // lost initialization race; just spin
// CAS设置如果设置成功就去更新不成功继续自旋
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
计数 addCount
这个方法一共做了两件事,更新baseCount的值,检测是否进行扩容。
在Java 7中ConcurrentHashMap对每个Segment单独计数,想要得到总数就需要获得所有Segment的锁,然后进行统计。由于Java 8抛弃了Segment,显然是不能再这样做了,而且这种方法虽然简单准确但也舍弃了性能。
Java 8声明了一个volatile变量baseCount用于记录元素的个数,对这个变量的修改操作是基于CAS的,每当插入元素或删除元素时都会调用addCount()函数进行计数。ConcurrentHashMap的计数设计与LongAdder类似。在一个低并发的情况下,就只是简单地使用CAS操作来对baseCount进行更新,但只要这个CAS操作失败一次,就代表有多个线程正在竞争,那么就转而使用CounterCell数组进行计数,数组内的每个ConuterCell都是一个独立的计数单元。
参考文献
HashMap最小树形化阈值MIN_TREEIFY_CAPACITY
Java集合:HashMap详解(JDK 1.8)
Map 大家族的那点事儿 ( 7 ) :ConcurrentHashMap ( 下 )
ConcurrentHashMap源码导读之initTable()方法
ConcurrentHashMap 1.7和1.8区别【这个写的很好】
ConcurrentHashMap 1.8为什么要使用CAS+Synchronized取代Segment+ReentrantLock