springboot 2.1.5整合elasticsearch6.3.0
搭建环境如下:
- springboot 2.1.5
- elasticsearch 版本6.3.0
- kibana 版本6.3.0
- IK Analyzer for Elasticsearch 版本 6.3.0
- 如需设置账户密码登录要购买es的商业版
- jdk1.8
安装elasticsearch6.3.0
下载地址:es6.3.0
下载安装解压后就可以
启动es 进入安装目录下的bin 运行elasticsearch.bat 出现如下表示启动成功
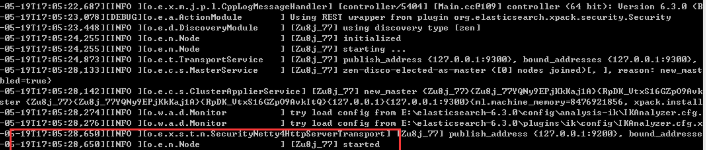
在浏览器中访问默认的端口号 9200

以下步骤根据个人需求 可以将es安装成windows的服务
安装服务
elasticsearch-service.bat install
删除已安装的es服务
elasticsearch-service.bat remove
启动es服务
elasticsearch-service.bat start
停止服务
elasticsearch-service.bat stop

安装kibana6.3.0
下载地址:kibana下载
下载安装解压
由于是6.X版本不支持修改配置文件来汉化,而且汉化过程不可逆,所以根据个人需求进行汉化
汉化地址:https://github.com/anbai-inc/Kibana_Hanization
启动kibana 前提是es已经是启动状态,否则会报错,进入安装目录下的bin 运行kibana .bat 如下启动成功
访问默认端口5601 成功

安装ik分词器
下载地址:ik分词器下载 版本选择6.3.0
下载解压到es安装目录下的plugins 新建一个ik文件夹
重新启动es kibana
es启动过程中出现 表示插件加载成功

springboot 整合es
springboot版本2.1.5
注意版本冲突 springboot2.1.5 支持的es版本es和kibana版本不对连接不上

- es依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 版本如下

3. 配置类
# 指定默认集群名和ip端口
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
-
新建实体类
@Doucument 进行数据存储的基本单元 以json格式存储的记录,indexName 指定创建存储的索引名
@Mapping 指定resources下面的json文件 来定义分词规则
@Id 一定要加在主键上
@Field 指定分词器的名称,只配置了ik分词器
@Data @Document(indexName = "testmapping") @Mapping(mappingPath = "course_mapping.json") public class demo implements Serializable { private static final long serialVersionUID = 1L; @Id @ApiModelProperty("课程id") private Integer cid; @ApiModelProperty("课程名") //analyzer:分词器名称 //ik_max_word:会将文本做最细粒度的拆分 //ik_smart:会将文本做最粗粒度的拆分 @Field(analyzer = "ik_max_word", searchAnalyzer = "ik_max_word", type = FieldType.Text) private String name; @ApiModelProperty("教师id") private Integer teacherId; } -
在resources下面建立指定的json文件
在需要分词的属性下加上 analyzer和search_analyzer 并指定分词格式
{ "demo": { "properties": { "cid": { "type": "long" }, "name": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "teacherId": { "type": "long" } } } }存储优化分词,就是将ElasticSearch文档中字段值按照一定的切分规则分为多个待匹配靶点,只有搜索关键词命中其中的靶点才会将该字段值对应的文档放在返回结果中。
检索优化分词,就是将用户输入的搜索关键词按照一定的切分规则分为多个靶点,然后根据这些靶点去匹配ElasticSearch中的所有待匹配靶点。根据这些靶点的匹配程度,ElasticSearch会计算得分,根据匹配度即得分情况从高到底返回搜索结果。如果一个靶点都没有匹配上,得分为0即不返回任何结果。
以"中华人民共和国国歌"为例,ik分词的两种分词规则的效果如下:
ik_max_word分词效果:“中华”,“中华人民”,“中华人民共和国”,“人民”,“人民共和国”,“共和”,“共和国”,“华人”,“国”,“国歌”。ik_smart分词效果:“中华人民共和国”,“国歌”。
上面的具体分词效果可以在kibana中查看
POST testmapping/_analyze { "field": "name", "text": "中华人民共和国国歌" }

-
编写接口继承ElasticsearchRepository<T, T>传入实体类、主键类型,就可以调用封装的方法
-
编写自己的测试类
-
第一步创建索引
@Autowired private ElasticsearchTemplate template; //通过template // createIndex 创建索引 template.createIndex(T.class); // 设置索引对应字段的分词规则(根据***.json中的设置开始生效) template.putMapping(T.class); -
增
通过刚刚的继承了ElasticsearchRepository的接口调用方法
interface.saveAll(Iterable<? extends T> entities) interface.save(S entity)
-

- 删
```java
deleteById(ID id)
delete(T entity)
deleteAll(Iterable<? extends T> entities)
deleteAll()
//删除索引
template.deleteIndex(T.class)
```

-
查
findById(Id id) existsById(ID id); findAll(); findAllById(Iterable<ID> ids); -
混合分页排序查询
混合搜索指模糊,单个字段查询,匹配所有的,多个字段匹配某一个值,可以设置权重
权重官方解释:权重解释
权重就影响上面提到的匹配度,分数:
查询时的权重提升 是可以用来影响相关度的主要工具,任意类型的查询都能接受 boost 参数。将 boost 设置为 2 ,并不代表最终的评分 _score 是原值的两倍;实际的权重值会经过归一化和一些其他内部优化过程。尽管如此,它确实想要表明一个提升值为 2 的句子的重要性是提升值为 1 语句的两倍。在实际应用中,无法通过简单的公式得出某个特定查询语句的 “正确” 权重提升值,只能通过不断尝试获得。需要记住的是 boost 只是影响相关度评分的其中一个因子;它还需要与其他因子相互竞争。选择权重,检查结果,如此反复。
//混合查询使用 /** * matchQuery : 单个字段查询 * matchAllQuery : 匹配所有 * multiMatchQuery : 多个字段匹配某一个值 * wildcardQuery : 模糊查询 * boost : 设置权重,数值越大权重越大 **/ // 下面可以多个选择 DisMaxQueryBuilder disMaxQueryBuilder = QueryBuilders.disMaxQuery(); // 单个字段查询 QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("cname",reqQueryDto.getCname().toLowerCase()); // wildcardQuery : 模糊查询 QueryBuilder wildcardCodeQuery = QueryBuilders.wildcardQuery("cname", reqQueryDto.getCname().toLowerCase()); disMaxQueryBuilder.add(wildcardCodeQuery).add(matchQueryBuilder); SearchQuery searchQuery = new NativeSearchQueryBuilder() // 指定查询方式 .withQuery(disMaxQueryBuilder) // 分页 .withPageable(PageRequest.of(reqQueryDto.getPage(), reqQueryDto.getSize())) // 排序规则 .withSort(SortBuilders.fieldSort("cid").order(SortOrder.DESC)) .build(); Page<Course> search = courseInterface.search(searchQuery);