本篇文章依然是进程、线程方面的内容,主要讲进程间的通信、进程队列、进程同步、进程池、进程同步和回调函数
进程间通信
进程就是两个独立的内存空间在运行,这两块空间之间的通信就是内存通信。但因为是独立的,所以无法公用全局变量,只能通过队列来通信
1、无法取到值(线程队列)
import queue
import multiprocessing
def foo(q):
q.put(520)
q.put('Zahi')
if __name__ == '__main__':
q= queue.Queue() #创建一个队列
p= multiprocessing.Process(target=foo,args=(q,)) #实例化进程对象
p.start() #启动进程
#取队列的值
print(q.get())
print(q.get())
#因为是两块独立的内存空间,所以无法直接从队列中取到值
2、进程队列
queue模块中的队列是针对线程的,所以在进程里无效,应该用multiprocessing模块里的队列,也就是multiprocessing.Queue()
import queue
import multiprocessing
import time
def foo(q):
time.sleep(1)
q.put('520,%s' %time.ctime())
q.put('Zahi,%s' %time.ctime())
if __name__ == '__main__':
#创建一个进程队列
q= multiprocessing.Queue()
#实例化进程对象,并将队列传入函数
p= multiprocessing.Process(target=foo,args=(q,))
p.start() #启动进程
#取队列的值
print(q.get())
print(q.get())

上面说了多进程是开辟多个内存空间,因此对资源的消耗是非常大的,我们应该谨慎使用多进程。下面有一个管道,也是进行进程间通信的
3、管道
from multiprocessing import Process, Pipe
def f(conn):
#子管道发送消息
conn.send([99, {"name":"Zahi"}, 'hello'])
#子管道接收消息
response=conn.recv()
print("response",response)
conn.close()
print("子管道:",id(conn))
if __name__ == '__main__':
#创建两个管道,作为双向管道收发消息
parent_conn, child_conn = Pipe()
print("父管道:",id(child_conn)) #输出管道id号
#实例化进程对象,并传入子管道
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) #输出来自子管道发来的消息
parent_conn.send("儿子你好!")
p.join()

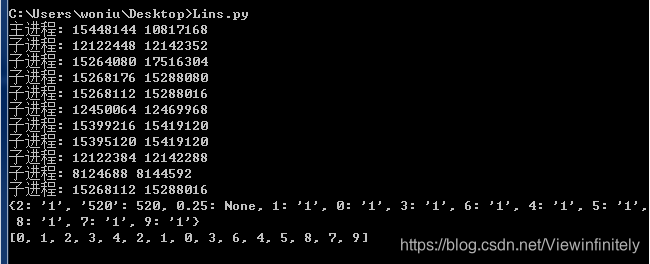
4、进程数据共享——Managers
即一个进程去改变另外一个进程的数据
from multiprocessing import Process, Manager
#修改数据的一个函数
def f(d, l, n):
d[n]= '1'
d['520']= 520 #在子进程中往manager字典里有加了一个{'520':520}
d[0.25]= None #又加一个布尔值{0.25:None}
l.append(n) #往manager列表里追加键值对
print("子进程:",id(d),id(l))
if __name__ == '__main__':
#一个IO管理
with Manager() as manager:
#创建manager字典和列表,用来传值
d = manager.dict()
l = manager.list(range(5))
print("主进程:",id(d),id(l))
p_list = [] #一个普通的列表,装多进程对象
for i in range(10):
p = Process(target=f, args=(d,l,i)) #传入manager字典、列表和进程号数
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
进程同步
用进程锁将锁住的进程变成串行,就像线程一样一个一个执行,因为一个锁同一时刻只能运行一个进程
from multiprocessing import Process, Lock
def f(l, i):
l.acquire() #启动锁
print('我是进程 %s'%i)
l.release() #释放锁
if __name__ == '__main__':
#创建一个进程锁
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()

进程池
1、概念
控制同时运行的进程的个数,也就是最大并行数。
进程池内部会维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
2、注意:
(1)Pool.apply():进程池内是串行
(2)Pool.apply_async():进程池内是并行
(3)close必须放在join前面:
Pool.close()
Pool.join()
3、测试代码
from multiprocessing import Process,Pool
import time,os
def Foo(i):
time.sleep(1) #1秒中打印一个内容
print(i)
if __name__ == '__main__':
#创建一个大小为5的进程池,表示可同时跑5个进程
pool = Pool(5)
for i in range(100):
#进程池对象的方法apply_async()
pool.apply_async(func=Foo, args=(i,))
#在进程池内close必须放在join前面
pool.close()
pool.join()
print('-------------------end-----------------------')
4、测试结果

可以看到,这串数字会每五个五个得输出
回调函数
1、概念
(1)某个动作或者函数执行成功后再去执行的函数,
(2)callback回调函数是主进程在调用,
(3)回调函数的参数是是子进程函数的返回值
2、测试代码
from multiprocessing import Process,Pool
import time,os
def Foo(i):
time.sleep(1) #1秒中打印一个内容
print(i)
#print('子进程:',os.getpid())
return '回调函数:%s'%i
#创建一个回调函数
def Bar(arg):
print(arg)
#print('主进程:',os.getpid())
if __name__ == '__main__':
#创建一个大小为5的进程池,表示可同时跑5个进程
pool = Pool(5)
for i in range(100):
#进程池对象的方法apply_async()
pool.apply_async(func=Foo, args=(i,),callback=Bar)
#回调函数设置为Bar,表示每一个进程执行结束后就会调用一次Bar函数
#在进程池内close必须放在join前面
pool.close()
pool.join()
print('-------------------end-----------------------')
3、测试结果

可以看到,函数内每输出的一个数字,就会返回一个回调函数的执行结果