这里写自定义目录标题

一、模块
1、什么是模块
模块:就是包含了一定功能的一个组件[组成的部件,类似零件!]
Python编程语言中,每个Python文件都是一个独立的模块,Python文件就是模块
2、模块的代码规范
一般来讲,开发项目的时候,需要将不同的功能进行划分
比如:
项目:学生管理系统
程序入口: main.py
视图模块: views.py 学生登录界面 系统界面
后台处理:seriveces.py 处理账户检测,用户输入处理
数据存储:data.py 上级调用我,我反馈数据
在创建项目的时候严格,遵循调用原则,划分谁是上级,谁是下级,不能下级调用上级的资源,比如 你一个数据存储调用程序入口!这。。。QAQ
- 当然可以理解成:程序入口调用视图模块,然后调用后台处理,后台处理调用数据储存。
- 实际开发中,可能视图模块也会调用数据存储,上级调用下级可以,可以跨级调用,比如用户登录界面 显示用户名称,这不就需要调用数据的吗
3、模块化开发的优点
模块化开发项目,相对于传统的开发一个学生管理系统:
- 便于维护,出现bug 可以明确知道在什么地方修改
- 便于升级附加新功能
二、模块如何引入另外一个模块
1、绝对引入
下面的方法,使用的时候是在一个目录路径下
import 模块名
import 模块名 as 别名[自己取的名字]
from 模块 import 变量/函数 # 不推荐的方法
使用方法:
import run 引入模块run
import eat as a 引入模块eat
from student import name 引入模块student中的name
from student import show_info_student 引入模块student中的 show_info_student 函数
import run #引入模块run
run.show_runner_info() # 调用run模块中的展示跑步者信息
print(run.name) # 调用run模块中跑步者的名字
import eat as a #引入模块eat 起名 a
a.show_eating_info()
print(a.name)
from student import name #引入模块student中的name
print(name) # 直接打印
from student import show_info_student #引入模块中show_info_student 函数
show_info_student() #直接使用
2、相对引入
大型项目开发会出的情况:
- 创建了很多文件夹
- 可能当前py文件引入的模块在另外个文件夹中,路径不在一块!
我们先来了解下命令方式路径表示:
. 一个点表示当前文件
.. 二个点表示上一级文件夹
使用方法,两个…也是如此,也可以加路径:
# 从当前文件中导入views模块
from . import views
# 别名法
from . import views as v
# 相对引入具体数据 引入变量 和 函数 [ 不推荐这种方法]
from .views import name,show_login
使用方法都是导入的模块名.[变量/函数],直接引入[变量/函数]直接使用即可,可以参考绝对引入。
三、包
1、什么是包

每个文件夹都能当成一个包,在大型项目开发的时候,都基本具备这种操作方式,每个包中包含了_ _ init _ _.py文件,里面内容可以里面为空
我们来看下图,也看直接看总图:
将mypackage展开,发现又多了两个文件夹,以及两个文件
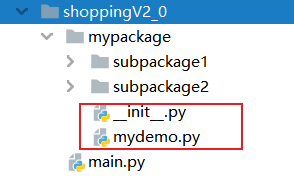
展开subpackage1和subpackage2

2、包的引入操作
2.1 绝对引入 [ 不推荐]
# 引入mypackage包中的mydemo模块
from mypackage import mydemo
# 引入mypackage包中的子包subpackage1中的subdemo1模块
from mypackage.subpackage1 import subdemo1
print(mydemo.name)
mydemo.test()
print(subdemo1.name)
subdemo1.test()

mypackage 文件中[程序包中的文件] mydemo.py 模块
"""
mypackage包
mydemo.py模块
"""
name = "mypackage程序包中的mydemo.py模块"
def test():
print("mypackage包中的test()函数执行了.")
subpackage1 文件中[程序包中的文件] subdemo1.py 模块
"""
subpackage1包
subdemo1.py模块
"""
name = "subpackage1程序包中的subdemo1.py模块"
def test():
print("subpackage1包中的test()函数执行了.")
2.1.1 别名引入
当然,包的引入也可以别名引入
# from mypackage import mydemo as md
# 引入mypackage包中的子包subpackage1中的subdemo1模块
# from mypackage.subpackage1 import subdemo1 as sd1
# from mypackage.subpackage2 import subdemo2 as sd2
# print(md.name)
# print(sd1.name)
# print(sd2.name)
2.1.2 直接引入 [ 需要搞清楚]
直接引入的时候,需要注意的事项!!!!特别重要,否则出错!!!
你想想,我直接引入了文件夹,然后使用的为啥不能点文件夹进去找到对应的文件
- 我仅仅是导入了 import mypackage
- 使用如:print(mypackage.subpackage1.subdemo1.name) 没有这种用法
- 而之前的直接引入,正确的是是from mypackage.subpackage1 import subdemo1
- 说明个问题 不能导入文件夹[虽然也是包] ,不能在执行的时候继续引入
import mypackage
print(mypackage.mydemo.name) # ?不能直接使用
print(mypackage.subpackage1.subdemo1.name) # ?不能直接使用
如何真想这么用了?也就是直接引用,需要修改每个文件中的代码
- 需要在mypackage包中的__init__.py模块中,指定那些模块可以被引入
- 修改mypackage/_ _ init _ _.py模块
添加代码:
from . import mydemo
from . import subpacakge1 - 修改subpackage1/ _ _ init _ _ .py模块中代码
添加代码:
from . import subdemo1.py
可以看到可以执行了

2.1.3 偷懒引入
很多代码都能看到,将mypackage一次性注入
main.py 中
# 将mypackage包中的所有数据一次性引入
from mypackage import *
print(mydemo.name)
print(subpackage1.subdemo1.name)
-
需要在mypackage包中的__init__.py模块中,指定那些模块可以被引入
-
修改mypackage/_ _ init _ _.py模块
添加代码:
_ _ all _ _ = [“mydemo”,“subpackage1” ] -
修改subpackage1/ _ _ init _ _ .py模块中代码
添加代码:
from . import subdemo1 正确
_ _ all _ _ = [“subdemo1”] 这样写mian.py执行 报错
针对于报错的地方,我有点不太明白,为什么懒人引入,这样搞最后一个包,初始化不能这样写
难道 form 文件名 import *,只能对于下一个包,然后最里面的包初始化都得直接引入嘛- -,有点迷

2.2 相对引入 [推荐]
多好用啊,前面花里呼哨,它不香嘛,其实看个人和具体情况使用,千万别有这种思想
from .mypackage import mydemo
print(mydemo.name)
四、内建模块 [ 列举常用的 ]
1、random 模块
import random
# randint():生成指定范围内的随机数
num = random.randint(1,10)
print(num)
# random(): 生成0-1直接的随机小数
print(random.random())
# uniform(): 生成指定范围内的随机小数
print(random.uniform(1,10))
# randrange: 生成指定范围内的随机整数,可以指定步长
print(random.randrange(1,10,2))
# random.shuffle(): 可以打乱序列
lst = [1,2,3,4,5]
random.shuffle(lst)
print(lst)
# choice(): 随机返回列表中的一个元素
lst = [1,2,3,4,5]
print(random.choice(lst))
# choices(): 随机取出指定个数元素
print(random.choices(lst,k=2))
# shuff()打乱列表顺序
random.shuffle(lst)
print(lst)

2、sys 模块
import sys
# - sys.version 返回解释器的版本号
print(sys.version)
# - sys.path 返回模块的搜索路径
print(sys.path)
# - sys.argv 接受命令行下的参数
3、string 模块
string 模块提供了系统中字符串的基本操作方式,描述了当前编程语言中使用到的字符 分类
import string
print(dir(string))
['Formatter', 'Template', '_ChainMap',
'_TemplateMetaclass', '__all__', '__builtins__',
'__cached__', '__doc__', '__file__', '__loader__',
'__name__', '__package__', '__spec__', '_re', '_string',
'ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords',
'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation',
'whitespace']
import string
# 字母大小写
print(string.ascii_letters)
# 字母小写
print(string.ascii_lowercase)
# 字母大写
print(string.ascii_uppercase)
# 数字
print(string.digits)
# 哈希
print(string.hexdigits)
还有好多,可以自己玩

4、time 模块
在 Python 中,通常有这三种方式来表示时间
- 时间戳、时间元组(struct_time)、格式化的时间字符串
- 时间戳(timestamp) 时间戳表示的是从 1970 年 1 月 1 日 00:00:00 开始到现在的秒值。返回的是 float 类型 格式化的时间字符串(Format String): ‘1999-12-06’ 时间元组(struct_time)
- struct_time 元组共有 9 个元素共九个元素:(年,月,日,时,分,秒,一周的第几日,一 年中第几天,夏令时)
小结:
- 时间戳是计算机能够识别的时间;
- 时间字符串是人能够看懂的时间;
- 时间元组则是用来操作时间的;
时间元组属性:

%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24 小时制小时数(0-23)
%I 12 小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地 A.M.或 P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身

import time
# 时间戳
print(time.time())
# 时间元组
ret = time.localtime()
print(ret)
print(ret[-2])
# 当前时间字符串
ret = time.localtime()
ret2 = time.strftime("%Y/%m/%d %H:%M:%S",ret)
print(ret2)
# 时间字符串转换为时间元组 strptime(时间字符串,"格式定义")
# 2019-08-08是2019年的第多少天?
ret = time.strptime("2019-08-08","%Y-%m-%d")
print(ret[-2])
执行结果
