对RCNN系列的解读与认识
针对RCNN的解读与认识
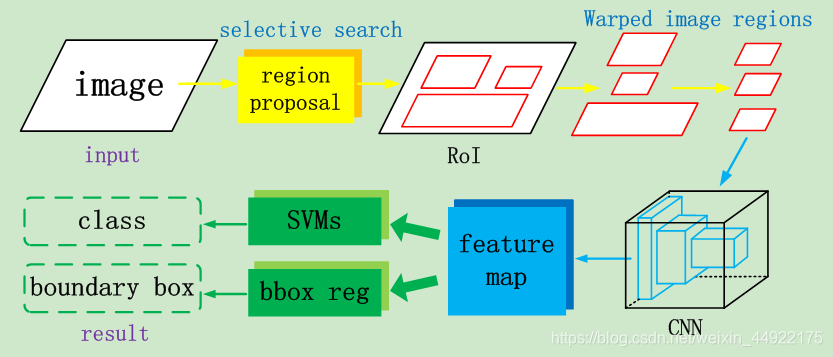
RCNN检测目标所遵循的简要步骤:
- 将图像作为输入;
- 使用一些proposals(如:选择性搜索方法)获得感兴趣区域(RoI);
- 对所有这些区域调整尺寸,并将每个区域传递给卷积神经网络(迁移学习);
- CNN为每个区域提取特征,二分类SVM用于将这些区域划分为不同的类别;
- 边界框回归(bbox reg)用于预测每个已识别区域的边界框。
RCNN模型局限性:
- 基于选择性搜索算法为每个图像提取2000个候选区域,耗时;
- 使用串行式CNN为每个图像区域提取特征,耗时;
- RCNN整个物体检测过程用到三种模型:
1)CNN模型用于特征提取;
2)线性SVM分类器用于识别目标的类别;
3)回归模型用于merge边界框。
三个模型是分别训练的,并且在训练的时候,对于存储空间的消耗很大。
针对Fast RCNN的解读与认识
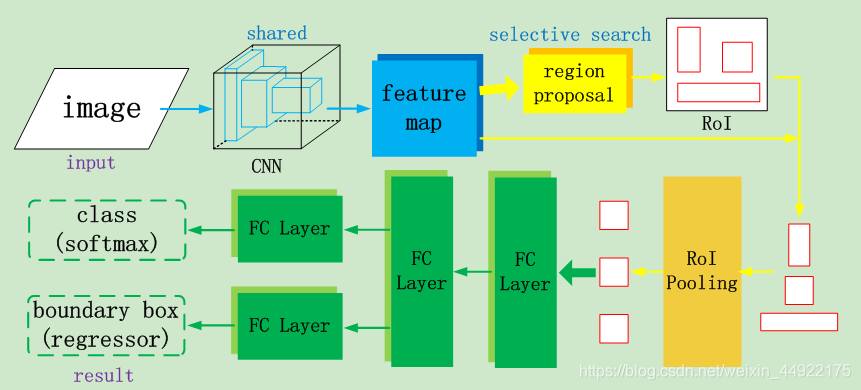 Fast RCNN检测目标所遵循的简要步骤:
Fast RCNN检测目标所遵循的简要步骤:
- 首先将图像作为输入;
- 将图像直接传递给卷积神经网络,生成感兴趣的区域(RoI);
- 对所有这些区域上应用RoI Pooling,以调整每个区域的尺寸。然后,将每个区域传递给全连接层的网络(FC Layer)。
- 最后,使用softmax层输出类别;
- 以及并行使用线性回归层,用于预测每个已识别区域的边界框。
解决问题:
- 将每个图像中的1个而不是2000个区域传递给卷积神经网络,
- 并使用一个模型来实现提取特征、分类和生成边界框。
Fast RCNN模型局限性:
- 仍然使用选择性搜索作为查找感兴趣区域的提议方法,耗时。
针对Faster RCNN的解读与认识
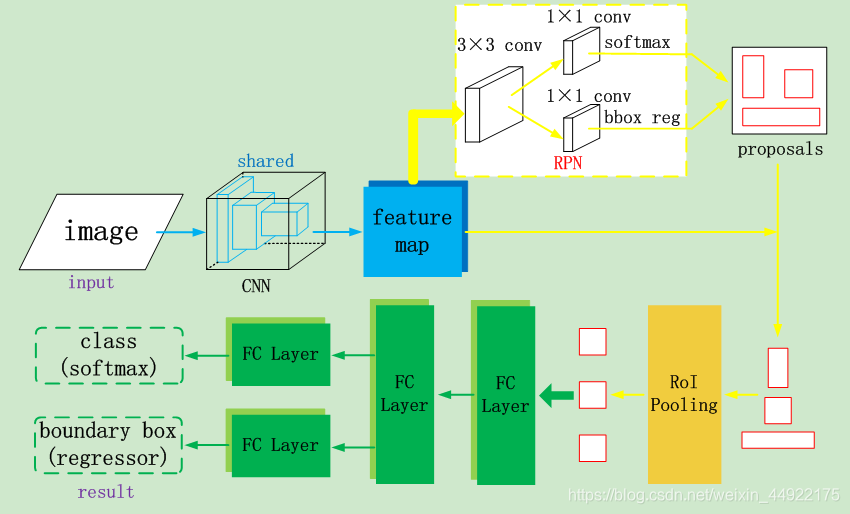
Faster RCNN检测目标所遵循的简要步骤:
- 首先将图像作为输入;
- 将图像直接传递给卷积神经网络,生成该图像的特征图(feature map);
- 在这些特征图上应用区域提议网络(RPN),预测proposals区域及其分数;
- 对所有这些区域上应用RoI Pooling,以调整每个区域的尺寸。
- 然后,将每个区域传递给全连接层的网络(FC Layer)。
- 最后,使用softmax层输出类别;
- 以及并行使用线性回归层,用于预测每个已识别区域的边界框。
解决问题:
- 用Region Proposal Network代替selective search,在生成RoI区域时,时间可大幅缩减。
Faster RCNN模型局限性:
- 该算法需要多次通过单个图像来提取到所有对象;
- 由于不是端到端的算法,不同的系统一个接一个地工作,整体系统的性能进一步取决于先前系统的表现效果。