❖掌握 ⬧ 概念结构设计、逻辑结构设计 (画ER图,转换关系模型)
❖了解 ⬧ 需求分析、物理设计、运行维护
❖重点⬧ 概念结构设计、逻辑结构设计
❖难点 ⬧ 概念结构向逻辑结构转换
❖第一节 数据库设计概述
❖数据库设计
⬧ 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构,并据此建立数据库及其应用系统,使之能够有效地存储和管理数据,满足各种用户的应用需求,包括信息管理要求和数据操作要求
⬧ 目标:为用户和各种应用系统提供一个信息基础设施和高效率的运行环境
数据库设计的特点
据库建设的基本规律
⬧ 三分技术,七分管理,十二分基础数据
⬧ 管理
➢数据库建设项目管理
➢企业(即应用部门)的业务管理
⬧ 基础数据
➢收集、入库
➢更新新的数据
❖结构(数据)设计和行为(处理)设计相结合
⬧ 将数据库结构设计和数据处理设计密切结合
数据库设计方法
❖手工与经验相结合方法
❖规范设计法
⬧ 基本思想:过程迭代和逐步求精
❖常见的设计方法
⬧ 新奥尔良(New Orleans)方法
⬧ 基于E-R模型的数据库设计方法
⬧ 3NF(第三范式)的设计方法
⬧ ODL(Object Definition Language)方法
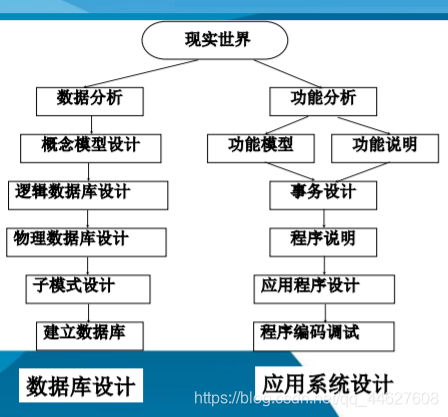
数据库设计的基本步骤
❖数据库设计分6个阶段
⬧ 需求分析
⬧ 概念结构设计
⬧ 逻辑结构设计
⬧ 物理结构设计
⬧ 数据库实施
⬧ 数据库运行和维护
❖需求分析和概念设计独立于任何数据库管理系统(都是一样的)
❖逻辑设计和物理设计与选用的DBMS密切相关
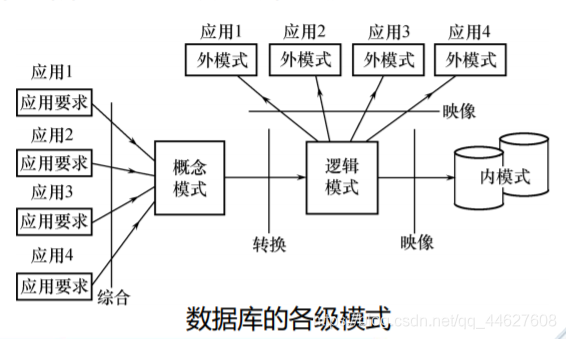
数据库设计过程中的各级模式
❖第二节 需求分析
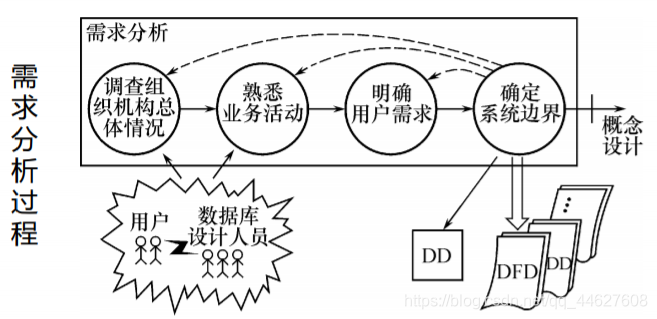
需求分析的任务
❖详细调查现实世界要处理的对象
❖充分了解原系统(手工系统或计算机系统)
❖明确用户的各种需求
❖确定新系统的功能
❖充分考虑今后可能的扩充和改变
❖调查的重点是“数据”和“处理”,获得用户对数据库要求
⬧ 信息要求
⬧ 处理要求
⬧ 安全性与完整性要求
❖需求分析的难点:确定用户最终需求
需求分析的方法
❖调查用户需求,与用户达成共识,然后分析表达这些需求
❖调查用户需求的具体步骤
⬧ 调查组织机构情况
⬧ 调查各部门的业务活动情况
⬧ 在熟悉业务活动的基础上,协助用户明确对新系统的各种要求
⬧ 确定新系统的边界
数据字典
❖数据字典的用途
⬧ 进行详细的数据收集和数据分析所获得的主要结果
❖数据字典的内容
⬧ 数据项
⬧ 数据结构
⬧ 数据流
⬧ 数据存储
⬧ 处理过程
❖第三节 概念结构设计
概念结构设计概述
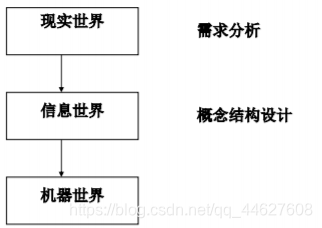
❖什么是概念结构设计
⬧ 需求分析阶段描述的用户应用需求是现实世界的具体需求
⬧ 将需求分析得到的用户需求抽象为信息结构即概念模型的过程就是概念结构 设计
⬧ 概念结构是各种数据模型的共同基础,它比数据模型更独立于机器、更抽象,从而更加稳定
⬧ 概念结构设计是整个数据库设计的关键
❖概念结构设计的特点
⬧ 能真实、充分地反映现实世界
⬧ 易于理解
⬧ 易于更改
⬧ 易于向关系、网状、层次等各种数据模型转换
信息世界中的基本概念
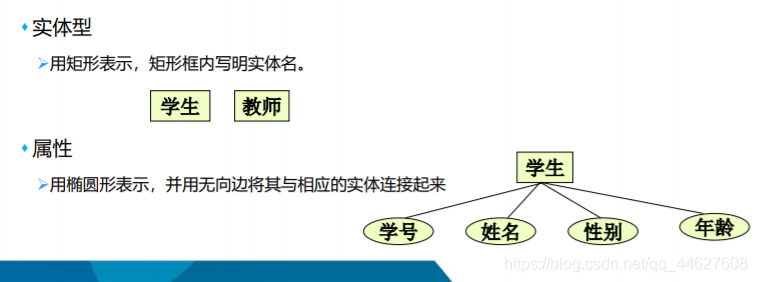
❖实体(Entity)
⬧ 客观存在并可相互区别的事物称为实体
⬧ 可以是具体的人、事、物或抽象的概念
❖属性(Attribute)
⬧ 实体所具有的某一特性称为属性
⬧ 一个实体可以由若干个属性来刻画
⬧ 例如:(李明,男,1972,江苏,计算机系,1990)
❖码(Key)
⬧ 唯一标识实体的属性集称为码
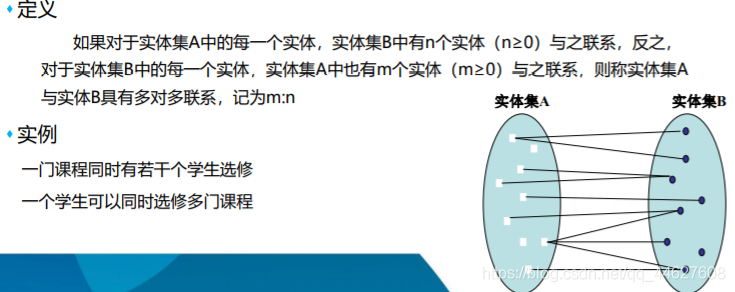
❖联系(Relationship)
⬧ 现实世界中事物内部以及事物之间的联系在信息世界中反映为实体内部的联
系和实体之间的联系
⬧ 根据联系涉及的实体数量可分为
➢一个实体型 |一对一联系(1:1)
➢多个实体型 |一对多联系(1:n)
➢两个实体型 |多对多联系(m:n)
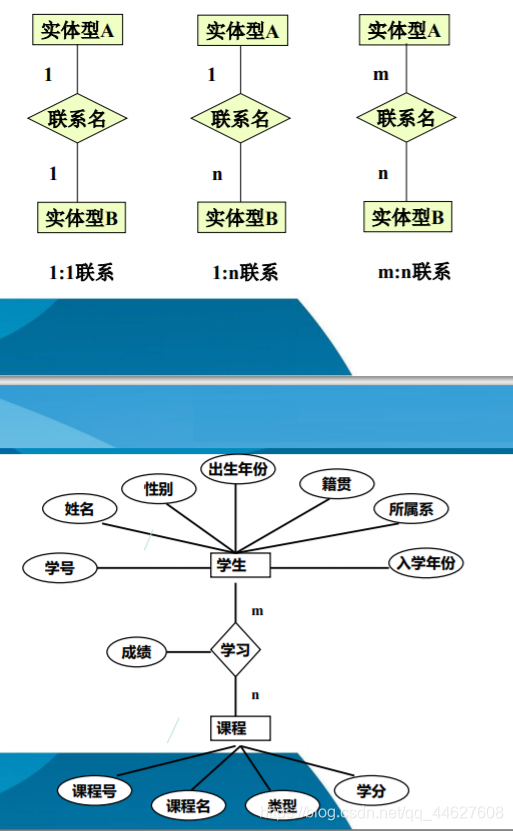
两个实体型之间的联系
❖一对一联系(1:1)

一对多联系(1:n)

多对多联系(m:n)
E-R图
❖联系
⬧ 联系本身:
用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时
在无向边旁标上联系的类型(1:1、1:n或m:n)
⬧ 联系的属性:
联系本身也是一种实体型,也可以有属性。如果一个联系具有属性,则这些属性
也要用无向边与该联系连接起来
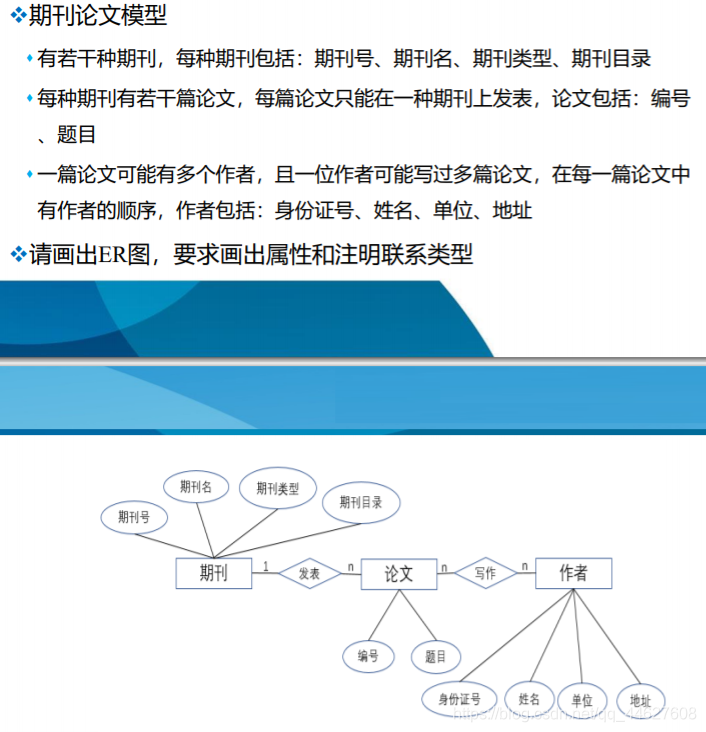
两个以上实体型之间的联系
❖多个实体型间的一对多联系
⬧ 若实体集E1,E2,…,En存在联系,对于实体集Ej(j=1,2,…,i-1,i+1,…,n)中的给定实体,最多只和Ei中的一个实体相联系,则我们说Ei与E1,E2,…,Ei-1,Ei+1,…,En之间的联系是一对多的
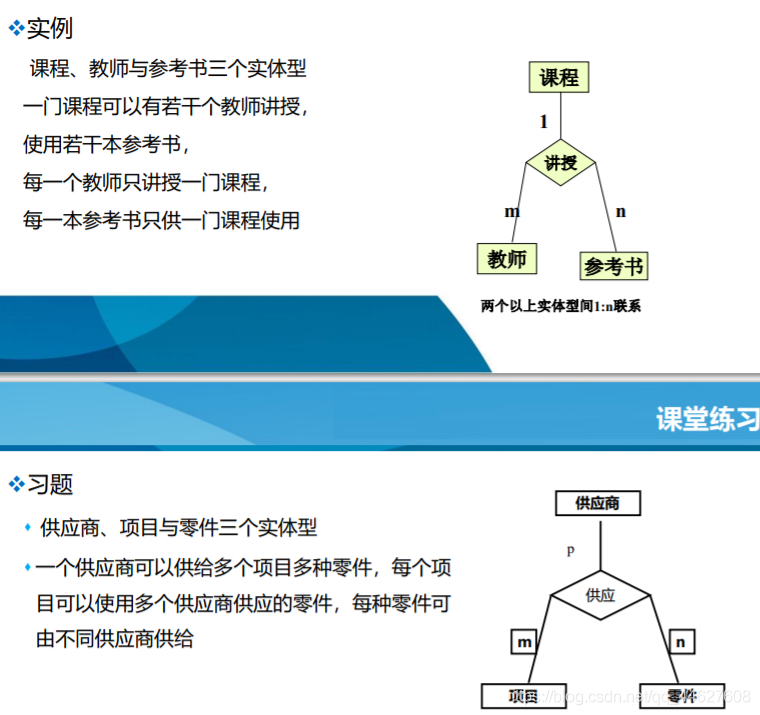
m n p 之间不要任何框框
单个实体型内的联系

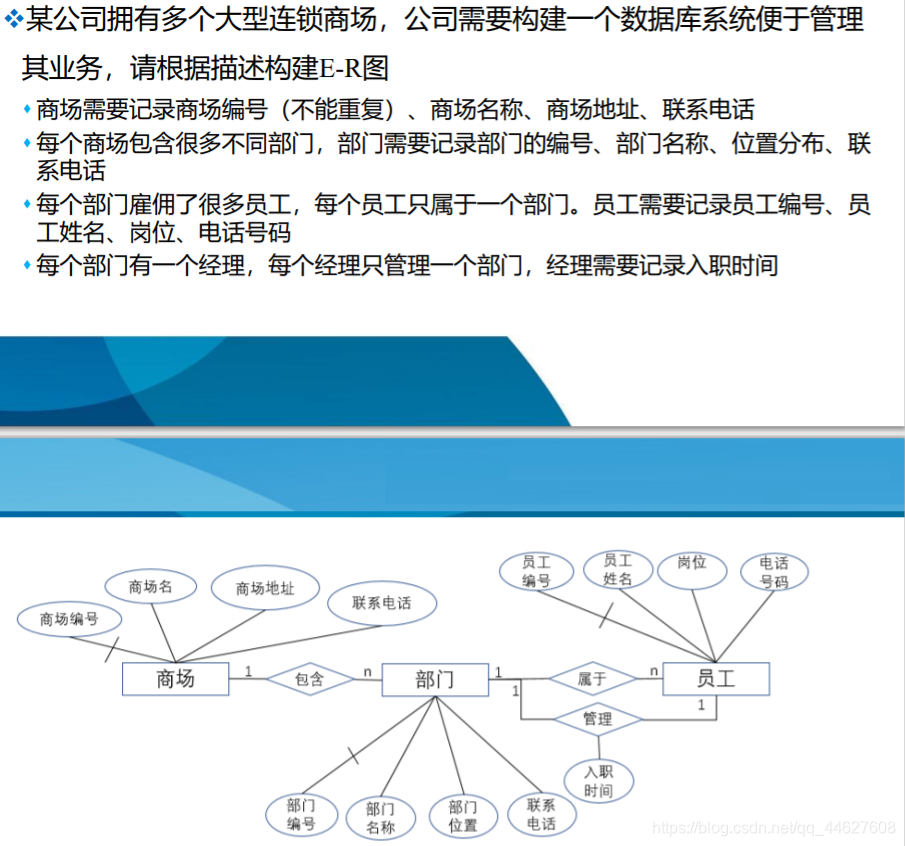
实体与属性的划分原则
❖原则
⬧ 现实世界的事物能作为属性对待的尽量作为属性对待
❖两条准则
⬧ 属性不能再具有需要描述的性质。即属性必须是不可分的数据项,不能再由另一些属性组成
⬧ 属性不能与其他实体具有联系。联系只发生在实体之间
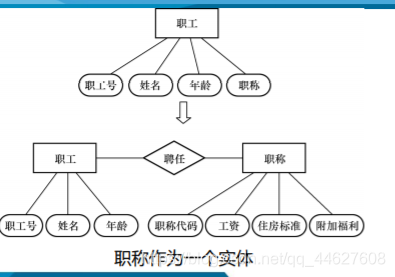
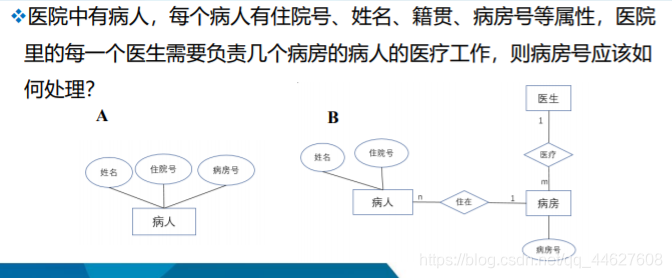
例2:教师是一个实体,有教工号、姓名、年龄等属性,通常职称也作为教师
实体的属性,但在如果职称与教师的工资、岗位津贴、福利等挂钩,即职称
与其他的实体之间有联系,则根据准则2,把职称作为实体来处理会更合适
些
E-R图的集成
❖各个局部视图即分E-R图建立好后,还需要对它们进行合并,集成为一个整体的数据概念结构即总E-R图
❖视图集成方法
⬧ 多个分E-R图一次集成
➢一次集成多个分E-R图
➢通常用于局部视图比较简单时
⬧ 逐步集成
➢用累加的方式一次集成两个分E-R图
集成局部E-R图的步骤
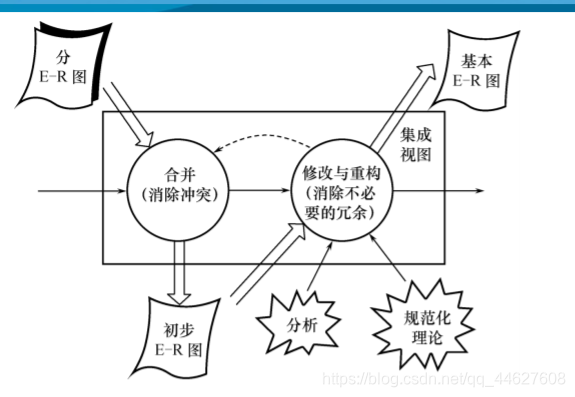
❖合并
❖合并分E-R图,生成初步E-R图
⬧ 各分E-R图存在冲突
➢各个局部应用所面向的问题不同
由不同的设计人员进行设计
各个分E-R图之间必定会存在许多不一致的地方
➢合并分E-R图的主要工作与关键所在:合理消除各分E-R图的冲突
❖修改与重构(重点)
❖冲突的种类(重点)
⬧ 属性冲突
⬧ 命名冲突
⬧ 结构冲突
❖两类属性冲突
⬧ 属性域冲突
➢属性值的类型
➢取值范围
➢取值集合不同
⬧ 属性取值单位冲突
例1: 由于学号是数字,因此某些部门(即局部应用)将学号定义为整数形式,而由于学号不用参与运算,因此另一些部门(即局部应用)将学号定义为字符型形式
例2:学生的身高,有的以米为单位,有的以厘米为单位,有的以尺为单位
两类命名冲突
⬧ 同名异义:不同意义的对象在不同的局部应用中具有相同的名字
⬧ 异名同义(一义多名):同一意义的对象在不同的局部应用中具有不同的名字命名冲突
例: 局部应用A中将教室称为房间
局部应用B中将学生宿舍称为房间
❖三类结构冲突
⬧ 同一对象在不同应用中具有不同的抽象
⬧ 同一实体在不同分E-R图中所包含的属性个数和属性排列次序不完全相同
⬧ 实体之间的联系在不同局部视图中呈现不同的类型
消除不必要的冗余,设计基本E-R图
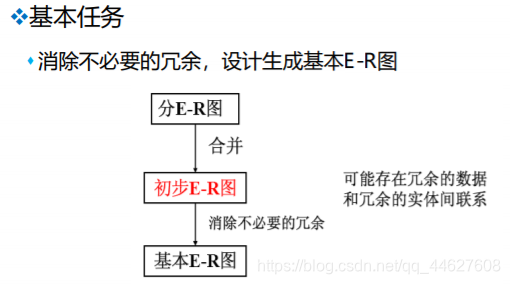
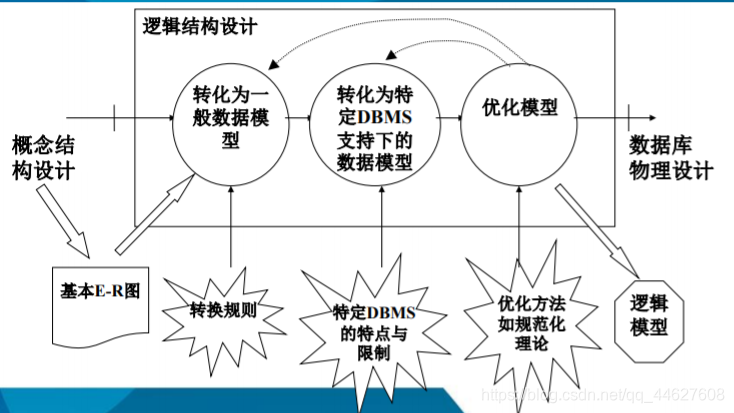
❖第四节 逻辑结构设计
❖逻辑结构设计的任务
⬧ 把概念结构设计阶段设计好的基本E-R图转换为与选用DBMS产品所支持的数据模型相符合的逻辑结构
❖逻辑结构设计的步骤
⬧ 将概念结构转化为一般的关系、网状、层次模型
⬧ 将转换来的关系、网状、层次模型向特定DBMS支持下的数据模型转换
⬧ 对数据模型进行优化
E-R图向关系模型的转换
❖E-R图向关系模型的转换要解决的问题
⬧ 如何将实体型和实体间的联系转换为关系模式
⬧ 如何确定这些关系模式的属性和码
❖转换内容
⬧ 将E-R图转换为关系模型:将实体、实体的属性和实体之间的联系转换为关系 模式
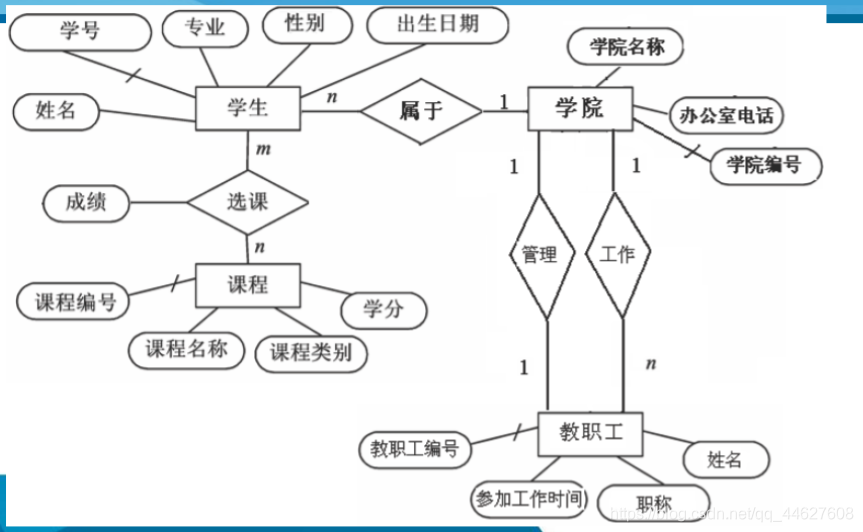
转换原则
1. 一个实体型转换为一个关系模式

2.一个M:N的联系转换为一个关系模式

3. 一个1:n联系可以转换为一个独立的关系模式
❖一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的
关系模式合并(一般都合并)
⬧ 转换为一个独立的关系模式
➢关系的属性:与该联系相连的各实体的码以及联系本身的属性
➢关系的码:n端实体的码
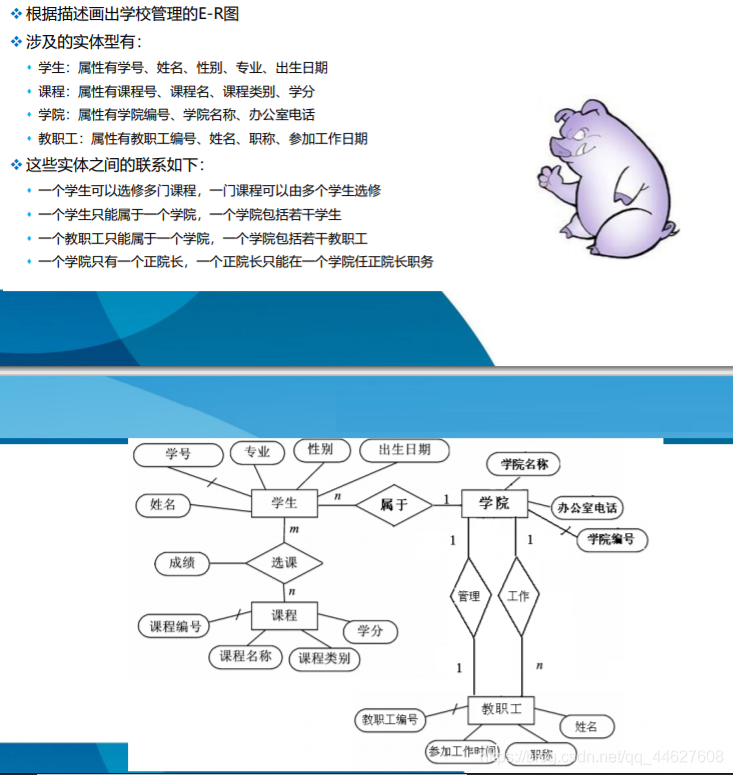
学院学生(学院编号,学号)
学院教职工(学院编号,教职工编号)
.
1:n 联系中,把1的主码扔给n表,在n表中作外码。
⬧ 与n端对应的关系模式合并
➢合并后关系的属性:在n端关系中加入1端关系的码和联系本身的属性
➢合并后关系的码:不变
⬧ 可以减少系统中的关系个数,一般情况下更倾向于采用这种方法
4. 一个1:1联系可以转换为一个独立的关系模式
❖一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对
应的关系模式合并
⬧ 转换为一个独立的关系模式
➢关系的属性:与该联系相连的各实体的码以及联系本身的属性
➢关系的候选码:每个实体的码均是该关系的候选码
⬧ 与某一端的关系模式合并
➢合并后关系的属性:加入另一端关系的码和联系本身的属性
➢合并后关系的码:不变
❖具有相同码的关系模式可合并
⬧ 目的:减少系统中的关系个数
⬧ 合并方法:将其中一个关系模式的全部属性加入到另一个关系模式中,然后
去掉其中的同义属性(可能同名也可能不同名),并适当调整属性的次序
.
最终结果:
学生(学号,姓名,性别,专业,出生日期,学院编号)
课程(课程编号,课程名称,课程类别,学分)
学院(学院编号,学院名称,办公室电话,院长教职工编号)
教职工(教职工编号,姓名,参加工作时间,职称,学院编号)
选课(学号,课程号,成绩)
数据模型的优化
❖数据库逻辑设计的结果不是唯一的
❖得到初步数据模型后,还应该适当地修改、调整数据模型的结构,以进一步提高数据库应用系统的性能,这就是数据模型的优化
❖关系数据模型的优化通常以规范化理论为指导
❖优化数据模型的方法
⬧ 确定数据依赖
⬧ 消除冗余的联系
⬧ 确定所属范式
⬧ 按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境这些
模式是否合适,确定是否要对它们进行合并或分解
⬧ 按照需求分析阶段得到的各种应用对数据处理的要求,对关系模式进行必要的分解,
以提高数据操作的效率和存储空间的利用率
设计用户子模式
定义用户外模式时应该注重的问题,包括三个方面
⬧ 使用更符合用户习惯的别名
⬧ 针对不同级别的用户定义不同的View ,以满足系统对安全性的要求
⬧ 简化用户对系统的使用
小结
❖任务
⬧ 将概念结构转化为具体的数据模型
❖逻辑结构设计的步骤
⬧ 将概念结构转化为一般的关系、网状、层次模型
⬧ 将转化来的关系、网状、层次模型向特定DBMS支持下的数据模型转换
⬧ 对数据模型进行优化
⬧ 设计用户子模式
综合练习1

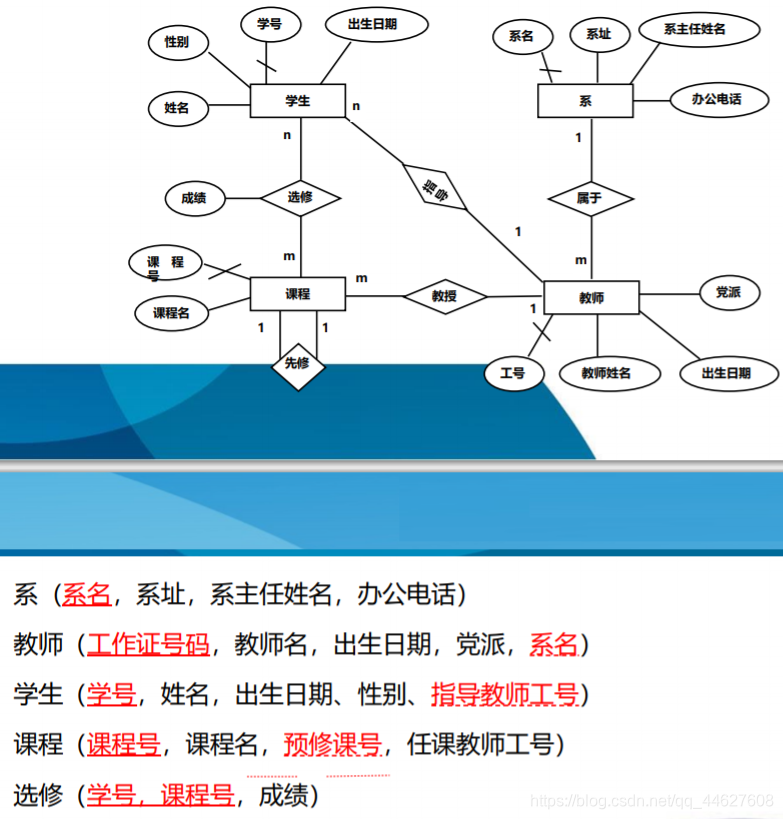
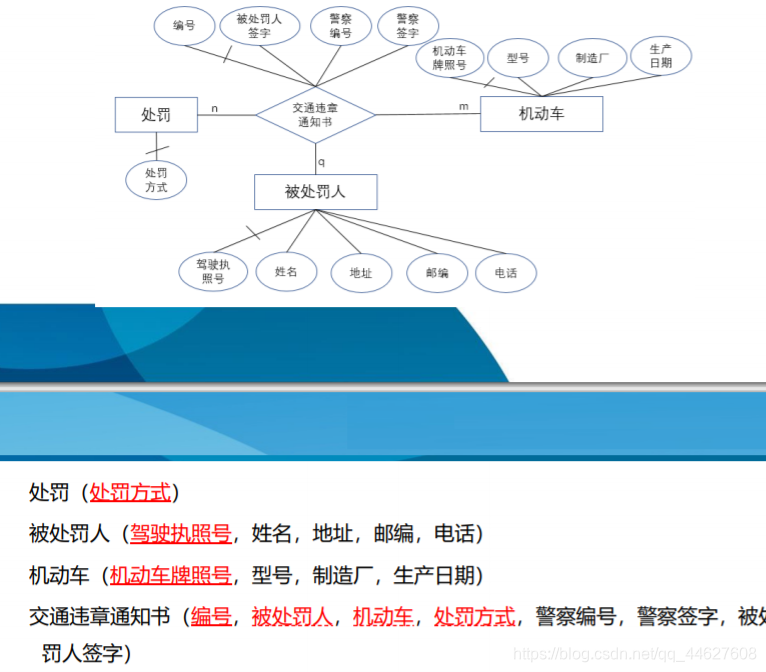
综合练习2

❖第五节 数据库的物理设计
数据库的物理设计
❖什么是数据库的物理设计
⬧ 数据库在物理设备上的存储结构与存取方法称为数据库的物理结构,它依赖于给定的计算机系统
⬧ 为一个给定的逻辑数据模型选取一个最适合应用环境的物理结构的过程,就是数据库的物理设计
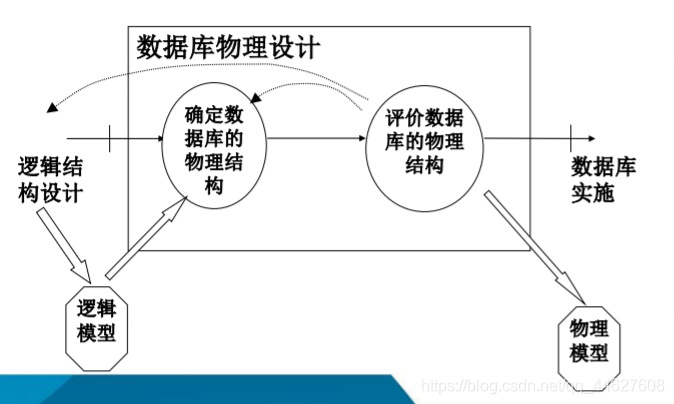
❖设计物理数据库结构的准备工作
⬧ 充分了解应用环境,详细分析要运行的事务,以获得选择物理数据库设计所需参数
⬧ 充分了解所用RDBMS的内部特征,特别是系统提供的存取方法和存储结构
关系模式存取方法选择
❖数据库系统是多用户共享的系统,对同一个关系要建立多条存取路径才能满足多用户的多种应用要求
❖物理设计的第一个任务就是要确定选择哪些存取方法,即建立哪些存取路径
❖DBMS常用存取方法
⬧ 索引方法,目前主要是B+树索引方法
经典存取方法,使用最普遍
⬧ 聚簇(Cluster)方法
⬧ HASH方法
❖选择索引存取方法的主要内容
根据应用要求确定
⬧ 对哪些属性列建立索引
⬧ 对哪些属性列建立组合索引
⬧ 对哪些索引要设计为唯一索引
索引存取方法的选择
❖选择索引存取方法的一般规则
⬧ 如果一个(或一组)属性经常在查询条件中出现,则考虑在这个(或这组)属性上建立索引(或组合索引)
⬧ 如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引
⬧ 如果一个(或一组)属性经常在连接操作的连接条件中出现,则考虑在这个(或 这组)属性上建立索引
❖关系上定义的索引数过多会带来较多的额外开销
⬧ 维护索引的开销
⬧ 查找索引的开销
聚簇存取方法的选择
什么是聚簇
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相同值的元组集中存放在连续的物理块称为聚簇
⬧ 许多关系型DBMS都提供了聚簇功能
❖聚簇的用途
⬧ 大大提高按聚簇属性进行查询的效率
⬧ 节省存储空间
❖聚簇的局限性
⬧ 聚簇只能提高某些特定应用的性能
⬧ 建立与维护聚簇的开销相当大
➢对已有关系建立聚簇,将导致关系中元组移动其物理存储位置,并使此关系上原有的索引
无效,必须重建
➢当一个元组的聚簇码改变时,该元组的存储位置也要做相应移动
聚簇的适用范围
⬧ 既适用于单个关系独立聚簇,也适用于多个关系组合聚簇
⬧ 当通过聚簇码进行访问或连接是该关系的主要应用,与聚簇码无关的其他访
问很少或者是次要的时,可以使用聚簇
确定数据库的存储结构
❖确定数据库物理结构的内容
⬧ 确定数据的存放位置和存储结构
➢关系
➢索引
➢聚簇
➢日志
➢备份
⬧ 确定系统配置
❖DBMS产品一般都提供了一些存储分配参数
⬧ 同时使用数据库的用户数
⬧ 同时打开的数据库对象数
⬧ 使用的缓冲区长度、个数
⬧ 时间片大小
⬧ 数据库的大小
⬧ 装填因子
⬧ 锁的数目
评价物理结构
❖评价内容
⬧ 对数据库物理设计过程中产生的多种方案进行细致的评价,从中选择一个较
优的方案作为数据库的物理结构
❖评价方法
⬧ 定量估算各种方案
➢ 存储空间、 存取时间、 维护代价
⬧ 对估算结果进行权衡、比较,选择出一个较优的合理的物理结构
⬧ 如果该结构不符合用户需求,则需要修改设计
❖第六节 数据库实施和维护
❖数据库实施的工作内容
⬧ 用DDL定义数据库结构(数据库定义语言)
⬧ 组织数据入库
⬧ 编制与调试应用程序
⬧ 数据库试运行
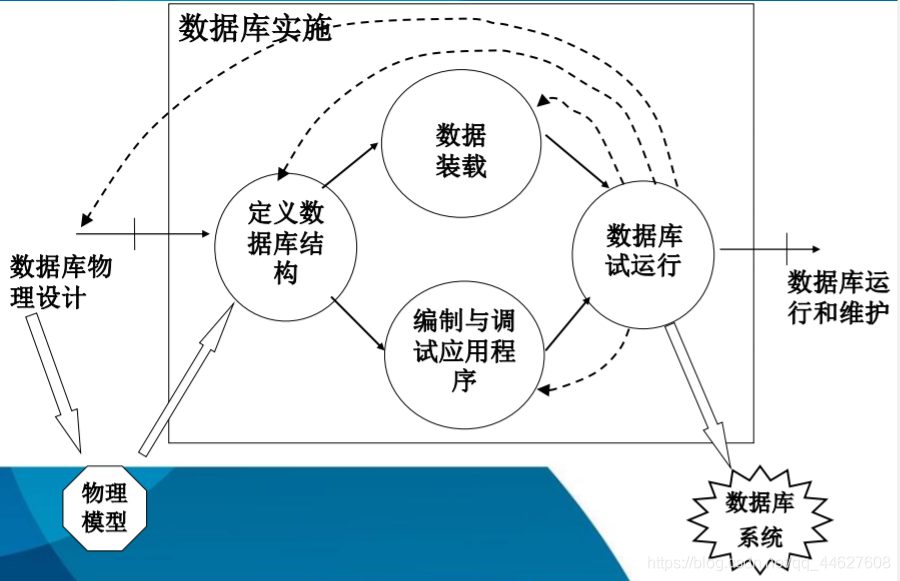
数据库运行与维护
❖数据库试运行结果符合设计目标后,数据库就可以真正投入运行了
❖数据库投入运行标志着开发任务的基本完成和维护工作的开始
❖对数据库设计进行评价、调整、修改等维护工作是一个长期的任务,也是设计工作的继续和提高
⬧ 应用环境在不断变化
⬧ 数据库运行过程中物理存储会不断变化
❖在数据库运行阶段,对数据库经常性的维护工作主要是由DBA完成的,包括
⬧ 数据库的转储和恢复
⬧ 数据库的安全性、完整性控制
⬧ 数据库性能的监督、分析和改进
⬧ 数据库的重组织和重构造