文章目录:
- 1、全局排序 (order by)
- ① 使用order by排序的子句在select 结尾处。
- ②案例实操:
- 2、区内排序 (sort by )分区字段 (distribute by)
- 设置reduces 个数:
- set mapreduce.job.reduces = 3;
- distribute by 分区字段 store by 排序字段 联合使用
- ②案例实操:不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapreduce.job.reduces>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
- ③输出结果:排序字段是NBA.name 可以看出是乱序。
- 3、distribute by
- ① 类似于MapReduce中分区partation,对数据进行分区,结合sort by进行使用 distribute by控制在map端如何拆分数据给reduce端。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。
- ② 二者结合使用的效果:
- 4、当分区条件和排序条件相同使用(cluster by)
- ②案例实操:
- 5、group by:对检索的数据进行单纯的分组,一般和聚合函数一起使用。
- 6、partition by:用来辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
- ① row_number() over ( partition by order by )
- select nba.id, nba.name, nba.city, row_number() over( partition by nba.name order by nba.id desc ) from nba;
- ② count(字段) over (partition by..... order by ....desc)
- hive (test_db)> select nba.id,nba.name,nba.city,count(nba.city) over (partition by nba.name order by nba.id desc) from nba;
- select nba.id,nba.name,nba.city,max(nba.id) over (partition by nba.name order by nba.id desc) from nba;
- max(id)over(parition by name order by id ) 的意思是通过name分组 在每一个组当中使用id排序 最后求出最大的id
- 7、总结:
1、全局排序 (order by)
order by:全局排序 只有一个reduce;多个reduce无用
① 使用order by排序的子句在select 结尾处。
降序:desc
升序:asc 不需要指定,默认是升序
②案例实操:

结果:
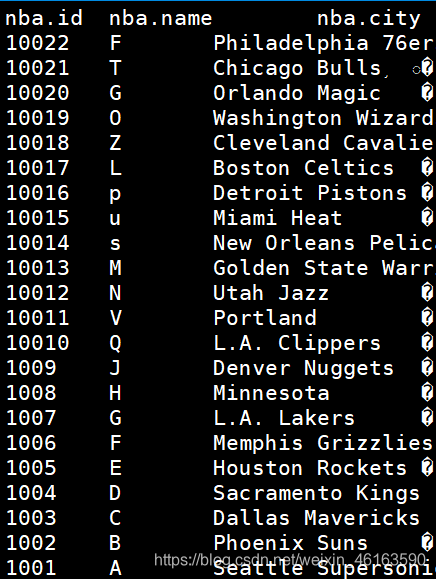
2、区内排序 (sort by )分区字段 (distribute by)
设置reduces 个数:
set mapreduce.job.reduces = 3;
distribute by 分区字段 store by 排序字段 联合使用
②案例实操:不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapreduce.job.reduces>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
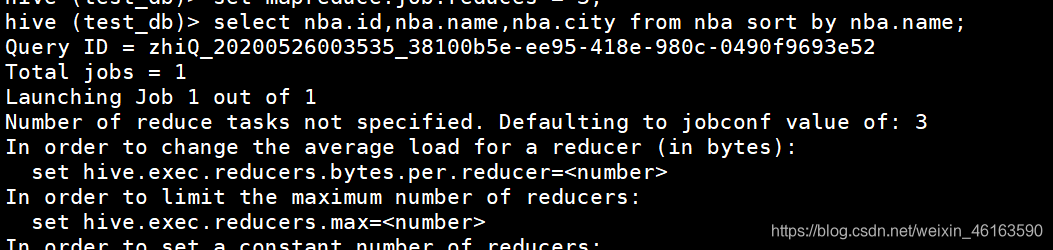
③输出结果:排序字段是NBA.name 可以看出是乱序。
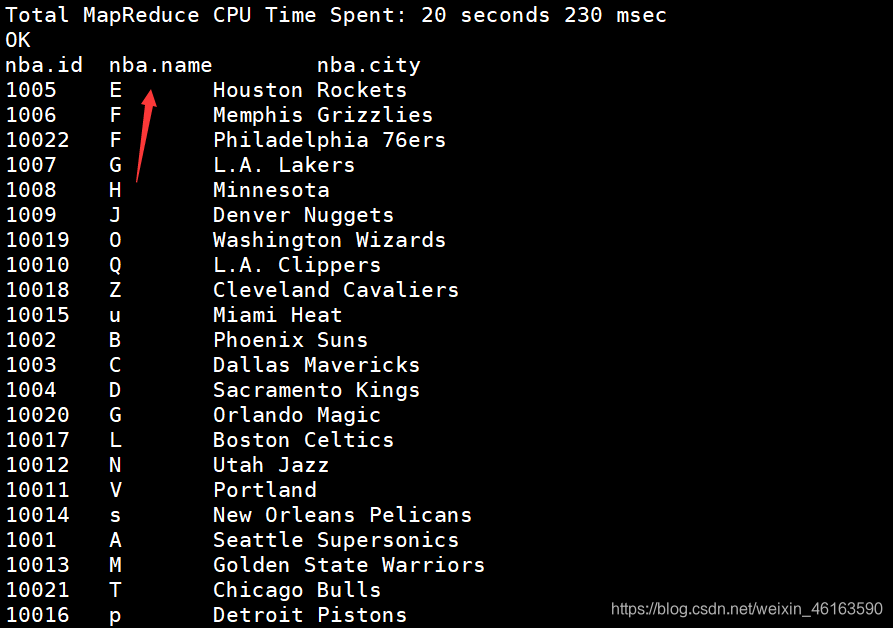
3、distribute by
① 类似于MapReduce中分区partation,对数据进行分区,结合sort by进行使用 distribute by控制在map端如何拆分数据给reduce端。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。
② 二者结合使用的效果:
hive (test_db)> select nba.id,nba.name,nba.city from nba distribute by nba.name sort by nba.id;
结果:
4、当分区条件和排序条件相同使用(cluster by)
① 当分区条件和排序条件相同使用cluster by .
Cluster by 除了具有distribute by的功能外,还会对该字段进行排序。当distribute by和sort by 字段相同时,可以使用cluster by 代替
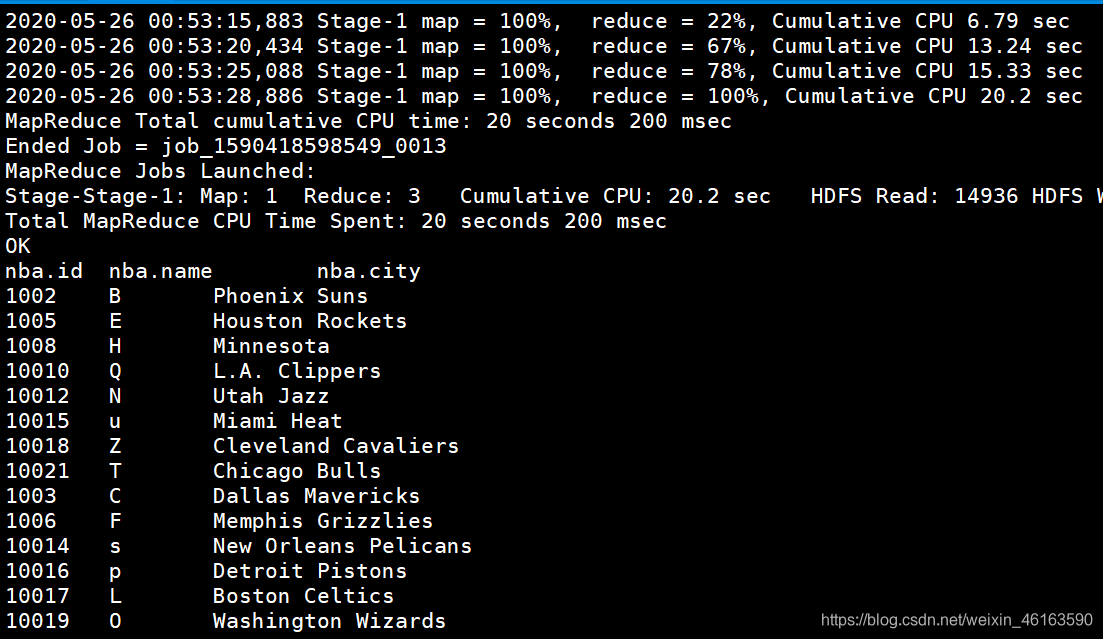
②案例实操:
我是按照 :nba.name 字母升序排序的,默认数据是乱序。
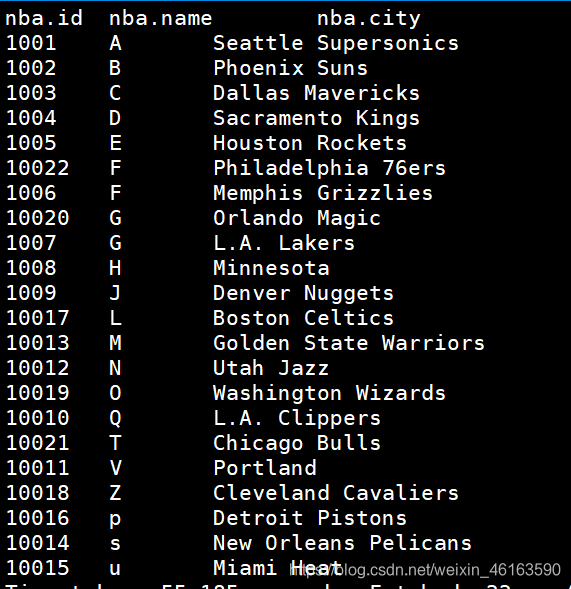
结果出来如下:
5、group by:对检索的数据进行单纯的分组,一般和聚合函数一起使用。
6、partition by:用来辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
① row_number() over ( partition by order by )
select nba.id, nba.name, nba.city, row_number() over( partition by nba.name order by nba.id desc ) from nba;
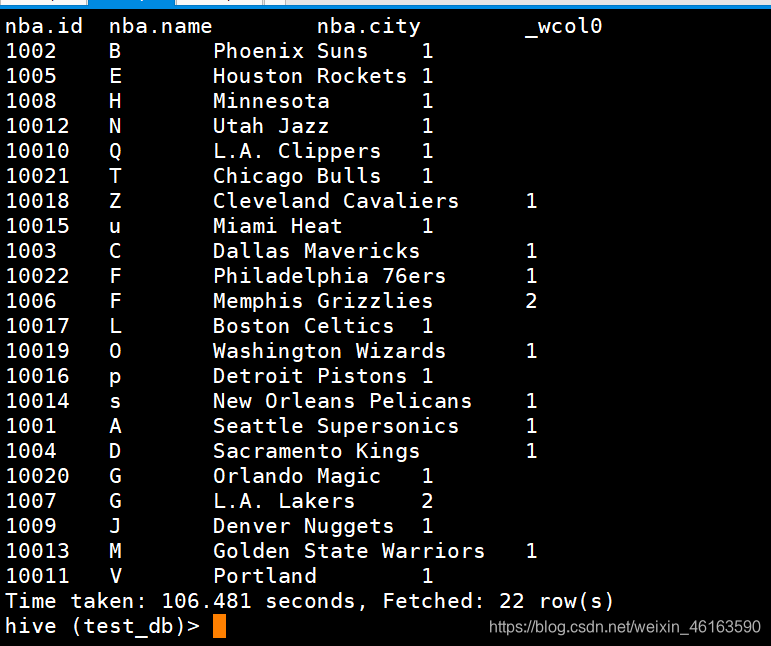
② count(字段) over (partition by… order by …desc)
hive (test_db)> select nba.id,nba.name,nba.city,count(nba.city) over (partition by nba.name order by nba.id desc) from nba;
结果: 
select nba.id,nba.name,nba.city,max(nba.id) over (partition by nba.name order by nba.id desc) from nba;
max(id)over(parition by name order by id ) 的意思是通过name分组 在每一个组当中使用id排序 最后求出最大的id
7、总结:
1、今天学到一招:在我们hive中 使用over子句窗口函数时要在over 前加聚合函数,不然报错,亲自实战。
2、在聚合函数前面不要忘记加逗号
3、聚合函数如下:
max()
min()
count()
sum()
AVG()
【转载注明出处,还望尊重原创 】
【作者水平有限,如有错误欢迎指正 .】
如果我的博客对你有帮助、如果你喜欢我的博客内容,请
“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
