目录
一.配置
1.安装eclipse和JDK
2.在eclipse中配置JDK
3.windows下安装hadoop环境
4.配置hadoop的环境变量(系统环境变量)
创建一个实验文件(windows下),将下面两个包解压在当前文件下
将hadoop-common-2.2.0-bin-master/bin下的hadoop.dll和winutils.exe复制到hadoop-2.6.4/bin下
添加环境变量
HADOOP_HOME=D:\hadoop\hadoop-2.6.4(即上面那个文件的路径)
Path=D:\hadoop\hadoop-2.6.4\bin
5.在工程中导入hadoop环境需要的jar包
方法:右键工程-->properties-->Java Build Path-->Add External JARs添加即可
D:\hadoop\hadoop-2.6.4\share\hadoop目录下的四个子目录下的包
common hdfs mapreduce yarn
D:\hadoop\hadoop-2.6.4\share\hadoop\common所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\common\lib 所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\hdfs所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\hdfs\lib 所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\mapreduce所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\mapreduce\lib 所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\yarn所有jar包
D:\hadoop\hadoop-2.6.4\share\hadoop\yarn\lib 所有jar包
在工程的src下创建包org.apache.hadoop.io.nativeio,将NativeIO.java文件(戳这里获取)放在里面
二.实操
1.步骤
wordCount运行(统计各单词频次)
1.新建本地文件words(centos下的mydata下)
2.在文件系统中新建目录/in(hadoop fs -mkdir /in)
3.把words文件上传到/in(hadoop fs -put words /in)
4.运行wordcount
5.查看结果(hadoop fs -cat /output/result/part-r-00000)
result下有两个文件(SUCCESS和part-r-00000),part-r-00000为结果文件
2.代码
(1)Test
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Test {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
FileSystem fs=FileSystem.get(conf);
System.out.println(fs.getUri());
System.out.println(fs.mkdirs(new Path("hdfs://master:9000/input")));
fs.close();
}
}(2)WorldCount
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDemo {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
//创建Configuration对象,用于获取配置信息
Configuration conf = new Configuration();
//创建job对象
Job job = Job.getInstance(conf);
//设置Jar包的类
job.setJarByClass(WordCountDemo.class);
//设置运行Map和Reduce的类
job.setMapperClass(MapDemo.class);
job.setReducerClass(ReduceDemo.class);
//设置最终结果的Key与Value的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出路径
FileInputFormat.addInputPath(job, new Path("hdfs://master:9000/in/words"));//读取文件路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/output/result"));//结果文件路径
//提交job
job.waitForCompletion(true);
}
/**
* KEYIN:表示输入的Key的数据类型,输入的Key是每行文本的偏移量
* VALUEIN:表示输入的Value的数据类型,输入的Value是每行文本的内容
* KEYOUT:表示Map产生的中间结果的Key的数据类型
* VALUEOUT:表示map产生的中间结果的Value的数据类型
* @author Administrator
*
*/
public static class MapDemo extends Mapper<LongWritable,Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String[] lines = value.toString().split(" ");
for (String word : lines) {
//在Map函数中,将每个单词出现次数记录为1,比如:<hive ,1>
//map产生的中间结果是一个键值对的形式,<hive,1>
context.write(new Text(word), new IntWritable(1));
}
//System.out.println("这是Map函数");
}
}
/**
* KEYIN表示reduce函数输入的key的数据类型
* VALUEIN表示reduce函数输入的value的数据类型
* KEYOUT表示最终结果的key的数据类型
* VALUEOUT表示最终结果的value的数据类型
* @author Administrator
*
*/
public static class ReduceDemo extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text k2, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
int sum=0;
for (IntWritable count : values) {
sum+=count.get();
}
//System.out.println("这是Reduce函数");
context.write(k2, new IntWritable(sum));
}
}
}
三.错误解决
说下我遇到的两个错误及解决办法
错误1
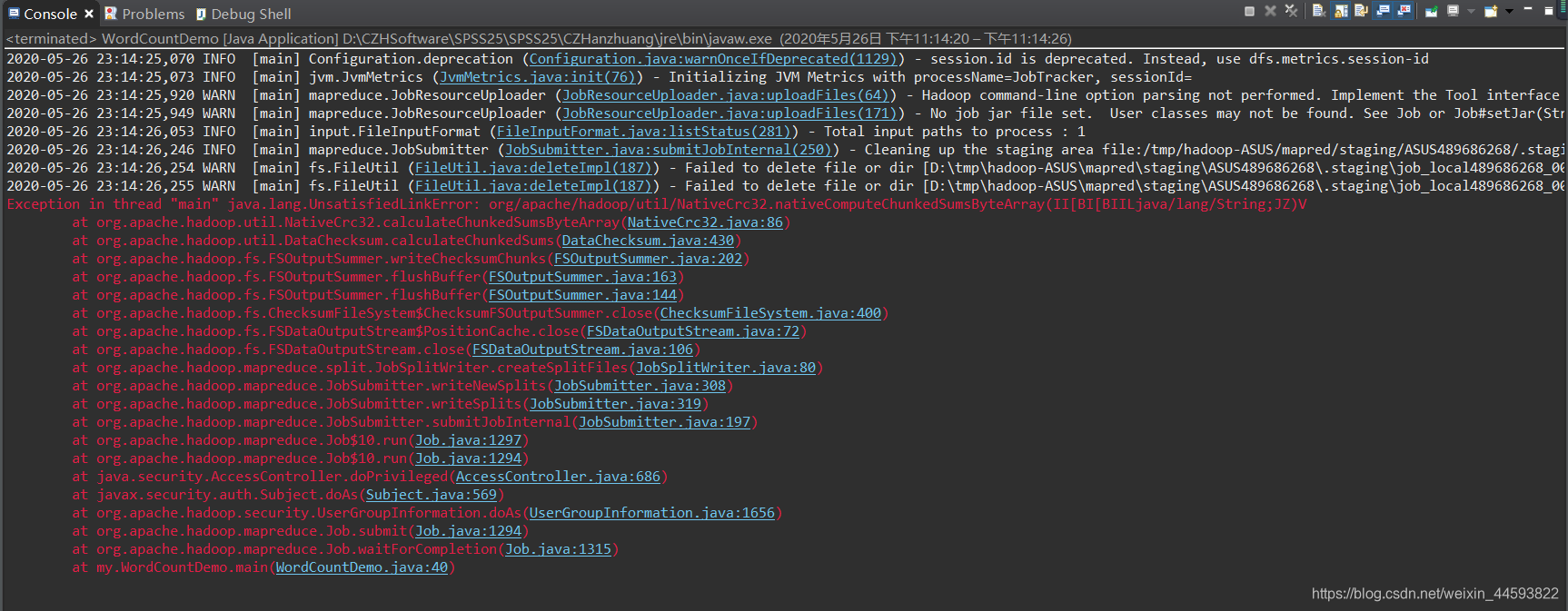
上面的错误是环境配置错误,可能与hadoop.dll和winutils.exe有关,我又重新复制了一遍,解决。
错误2
忘了截图了和下面一行一样,只不过我的没报错,
![]()
所以我运行之后发现计算量为0,也没有生成output文件,所以明白了上面那句话,没有写权限!
修改权限就好,hadoop fs -chmod 777 /
解决!