监督学习:
对已标记的训练样本进行学习,然后对样本的数据进行标记预测。
比如分类垃圾邮件,需对训练样本的邮件进行标记,所谓标定,就是每一封邮件都要人为去制定,然后通过学习,模型对新来的邮件判断是否是垃圾邮件。
非监督学习:
对没有标记的训练样本进行学习,发现其中的结构性知识。
比如把进店购买商品的顾客进行聚类,将他们划分成不同的细分市场。
强化学习:
可以理解为一个机器人不断依据环境做决策,然后环境根据决策进行奖励或惩罚,机器人就能根据环境给予的反馈学习的方式。
比如小时候,你放学回家没有做作业就出去玩,然后就被妈妈教训了,第二次又这样,又被教训了,第三次你就会根据前面的反馈知道应该先做作业,然后妈妈就奖励了你一个糖果,接着第四次你就会先做作业,这就是一个强化学习的过程举例。
线性模型:
一元线性模型非常简单,假设我们有变量xi和目标Yi,每个i对应于一个数据点,希望建立一个模型![]()
yi是我们预测的结果,希望通过yi来拟合目标Yi,通俗来讲就是找到这个函数拟合Yi使得误差最小,即最小化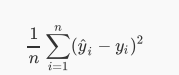
减小这个误差,需要用到梯度下降
梯度下降:
什么是梯度?梯度就是导数。如果是一个多元函数,那么梯度就是偏导数。比如一个函数是f(x,y),那么梯度就是:
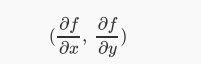


我们可以来看一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
类比我们的问题,就是沿着梯度的反方向,我们不断改变w和b的值,最终找到一组最好的w和b使得误差最小。
在更新的时候,我们需要决定每次更新的幅度,比如在下山的例子中,我们需要每次往下走的那一步的长度,这个长度称为学习率,用η表示,这个学习率非常重要,不同的学习率都会导致不同的结果,学习率太小会导致下降非常缓慢,学习率太大又会导致跳动非常明显。
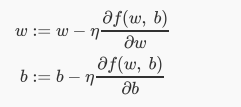
通过不断的迭代更新,找到最优的w和b
PyTorch实现线性模型和梯度下降
import torch
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(2020)
#读入数据x和y
x_train=np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.799],
[6.182],[7.59],[2.167],[7.042],[10.791],
[5.313],[7.997],[3.1]],dtype=np.float32)
y_train=np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],
[3.366],[2.596],[2.53],[1.221],[2.827],
[3.465],[1.65],[2.904],[1.3]],dtype=np.float32)
#画出图像
plt.plot(x_train,y_train,'bo')
plt.show() 
import torch
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(2020)
#读入数据x和y
x_train=np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.799],
[6.182],[7.59],[2.167],[7.042],[10.791],
[5.313],[7.997],[3.1]],dtype=np.float32)
y_train=np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],
[3.366],[2.596],[2.53],[1.221],[2.827],
[3.465],[1.65],[2.904],[1.3]],dtype=np.float32)
#画出图像
plt.plot(x_train,y_train,'bo')
plt.show()
#转化成Tensor
x_train=torch.from_numpy(x_train)
y_train=torch.from_numpy(y_train)
#定义参数w和b
w=Variable(torch.randn(1),requires_grad=True)#随机初始化
b=Variable(torch.zeros(1),requires_grad=True)#使用0进行初始化
#构建线性回归模型
x_train=Variable(x_train)
y_train=Variable(y_train)
def linear_model(x):
return x*w+b
y_=linear_model(x_train)
#模型输出结果:
plt.plot(x_train.data.numpy(),y_train.data.numpy(),'bo',label="real")
plt.plot(x_train.data.numpy(),y_.data.numpy(),'ro',label="estimated")
plt.legend()
plt.show()
红色的点表示预测值,似乎排列成一条直线,这时候我们需要计算误差函数:
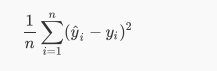
#计算误差
def get_loss(y_,y):
return torch.mean((y_-y_train)**2)
loss=get_loss(y_,y_train)
#打印一下看看loss的大小
print(loss)接下来计算w和b的梯度:
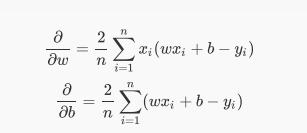
import torch
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(2020)
#读入数据x和y
x_train=np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.799],
[6.182],[7.59],[2.167],[7.042],[10.791],
[5.313],[7.997],[3.1]],dtype=np.float32)
y_train=np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],
[3.366],[2.596],[2.53],[1.221],[2.827],
[3.465],[1.65],[2.904],[1.3]],dtype=np.float32)
#画出图像
plt.plot(x_train,y_train,'bo')
plt.show()
#转化成Tensor
x_train=torch.from_numpy(x_train)
y_train=torch.from_numpy(y_train)
#定义参数w和b
w=Variable(torch.randn(1),requires_grad=True)#随机初始化
b=Variable(torch.zeros(1),requires_grad=True)#使用0进行初始化
#构建线性回归模型
x_train=Variable(x_train)
y_train=Variable(y_train)
def linear_model(x):
return x*w+b
y_=linear_model(x_train)
#计算误差
def get_loss(y_,y):
return torch.mean((y_-y_train)**2)
loss=get_loss(y_,y_train)
#打印一下看看loss的大小
print(loss)
#自动求导
loss.backward()
#查看w和b的梯度
print(w.grad)
print(b.grad)
#更新一次参数
w.data=w.data-1e-2*w.grad.data
b.data=b.data-1e-2*b.grad.data
#更新参数后,查看时输出模型
y_=linear_model(x_train)
plt.plot(x_train.data.numpy(),y_train.data.numpy(),'bo',label="real")
plt.plot(x_train.data.numpy(),y_.data.numpy(),'ro',label="estimated")
plt.legend()
plt.show()

从上面的例子可以看到,更新之后红色的线跑到了蓝色的线下面,没有特别好的拟合蓝色的真实值,所以需要在进行几次更新。
import torch
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(2020)
#读入数据x和y
x_train=np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.799],
[6.182],[7.59],[2.167],[7.042],[10.791],
[5.313],[7.997],[3.1]],dtype=np.float32)
y_train=np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],
[3.366],[2.596],[2.53],[1.221],[2.827],
[3.465],[1.65],[2.904],[1.3]],dtype=np.float32)
#转化成Tensor
x_train=torch.from_numpy(x_train)
y_train=torch.from_numpy(y_train)
#定义参数w和b
w=Variable(torch.randn(1),requires_grad=True)#随机初始化
b=Variable(torch.zeros(1),requires_grad=True)#使用0进行初始化
#构建线性回归模型
x_train=Variable(x_train)
y_train=Variable(y_train)
def linear_model(x):
return x*w+b
y_=linear_model(x_train)
#计算误差
def get_loss(y_,y):
return torch.mean((y_-y_train)**2)
loss=get_loss(y_,y_train)
#打印一下看看loss的大小
print(loss)
#自动求导
loss.backward()
for e in range(10):#进行10次更新
y_=linear_model(x_train)
loss=get_loss(y_,y_train)
w.grad.zero_()#记得归零梯度
b.grad.zero_()#记得归零梯度
loss.backward()
# 更新参数
w.data = w.data - 1e-2 * w.grad.data
b.data = b.data - 1e-2 * b.grad.data
print('epoch:{},loss:{}'.format(e,loss.data))
y_=linear_model(x_train)
plt.plot(x_train.data.numpy(),y_train.data.numpy(),'bo',label="real")
plt.plot(x_train.data.numpy(),y_.data.numpy(),'ro',label="estimated")
plt.legend()
plt.show()


经过10次更新,我们发现红色的预测结果已经比较好的拟合了蓝色的真实值。
多项式回归模型:
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.autograd import Variable
w_target=np.array([0.5,3,2.4])#定义参数
b_target=np.array([0.9])#定义参数
f_des='y={:.2f}+{:.2f}*x+{:.2f}*x^2+{:.2f}*x^3'.format(
b_target[0],w_target[0],w_target[1],w_target[2]
)
#打印出函数的式子
print(f_des)
#画出多项式图像
x_sample=np.arange(-3,3.1,0.1)
y_sample=b_target[0]+w_target[0]*x_sample+w_target[1]*x_sample**2+w_target[2]*x_sample**3
plt.plot(x_sample,y_sample,label="real curve")
plt.legend()
plt.show()
#构建数据阶,需要x和y,同时是一个三次多项式
x_train=np.stack([x_sample**i for i in range(1,4)],axis=1)
x_train=torch.from_numpy(x_train).float()#转化成float tensor
y_train=torch.from_numpy(y_sample).float().unsqueeze(1)
#定义参数和模型
w=Variable(torch.rand(3,1),requires_grad=True)
b=Variable(torch.rand(1),requires_grad=True)
#将x和y转化成Variable
x_train=Variable(x_train)
y_train=Variable(y_train)
def multi_linear(x):
return torch.mm(x,w)+b
#画出没有更新之前的模型
y_pred=multi_linear(x_train)
plt.plot(x_train.data.numpy()[:,0],y_pred.data.numpy(),label="fitting curve",color="r")
plt.plot(x_train.data.numpy()[:,0],y_sample,label="real curve",color="b")
plt.legend()
plt.show()
#计算误差
#计算误差
def get_loss(y_,y):
return torch.mean((y_-y_train)**2)
loss=get_loss(y_pred,y_train)
print(loss)
#自动求导
loss.backward()
#查看一下w和b的梯度
print(w.grad)
print(b.grad)
#更新一下参数
y_pred=multi_linear(x_train)
plt.plot(x_train.data.numpy()[:,0],y_pred.data.numpy(),label="fitting curve",color="r")
plt.plot(x_train.data.numpy()[:,0],y_sample,label="real curve",color="b")
plt.legend()
plt.show()
for e in range(100):#进行100次更新
y_pred=multi_linear(x_train)
loss=get_loss(y_pred,y_train)
w.grad.zero_()#记得归零梯度
b.grad.zero_()#记得归零梯度
loss.backward()
# 更新参数
w.data = w.data - 0.001 * w.grad.data
b.data = b.data - 0.001 * b.grad.data
if(e+1)%20==0:
print('epoch:{},loss:{}'.format(e,loss.data))
y_pred=multi_linear(x_train)
plt.plot(x_train.data.numpy()[:,0],y_pred.data.numpy(),label="fitting curve",color="r")
plt.plot(x_train.data.numpy()[:,0],y_sample,label="real curve",color="b")
plt.legend()
plt.show()
打印出函数的式子
![]()
画出多项式的图像

更新之前的模型

更新一次之后的模型

更新100次后,拟合的线和真实的线已经完全重和。
