简介
- IK Analyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包;
- 最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件;从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立亍 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化;
本篇就介绍如何给ES安装插件,以及使用ik中文分词器进行搜索,最后介绍一下如何热加载自定义词库。
ELK系列(一)、安装ElasticSearch+Logstash+Kibana+Filebeat-v7.7.0
ELK系列(二)、在Kibana中使用RESTful操作ES库
ELK系列(四)、Logstash读取nginx日志写入ES中
ELK系列(五)、Logstash修改@timestamp时间为日志的产生时间
ELK系列(六)、修改Nginx日志为Json格式并使用Logstash导入至ES
ELK系列(七)、Filebeat+Logstash采集多个日志文件并写入不同的ES索引中
ELK系列(八)、使用Filebeat+Redis+Logstash收集日志数据
---------------------------------------ES中文分词器ik-----------------------------------------
安装
下载
https://github.com/medcl/elasticsearch-analysis-ik
我使用的es7.7.0,所以我下载ik7.7.0,版本和es一一对应的。
安装
传到服务器上执行下面的命令解压:
mkdir ik
mv elasticsearch-analysis-ik-7.7.0.zip ik/
cd ik
unzip elasticsearch-analysis-ik-7.7.0.zip
rm -rf elasticsearch-analysis-ik-7.7.0.zip然后将该目录移动到$ES_HOME/plugins目录下,重启ES即可:
mv ik /opt/app/elasticsearch-7.7.0/plugins/
sudo -u elk nohup $ES_HOME/bin/elasticsearch >> $ES_HOME/output.log 2>&1 &
使用
建索引
在ES中建索引以及mapping:
#建索引
PUT /csdn
#建mapping
POST /csdn/_mapping
{
"properties": {
"content":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
#查看mapping
GET /csdn/_mapping
#建没有使用分词器的索引对比
PUT /wyk
造数据
例子:同时往csdn和wyk两个索引中插入同样的数据
POST /csdn/_doc/1
{
"content":"特朗普暴打川普"
}
POST /csdn/_doc/2
{
"content":"特朗普和本拉登的爱恨情仇"
}
POST /csdn/_doc/3
{
"content":"美国白宫里有头猪会说普通的english"
}
POST /csdn/_doc/4
{
"content":"川普!=川建国"
}
POST /wyk/_doc/1
{
"content":"特朗普暴打川普"
}
POST /wyk/_doc/2
{
"content":"特朗普和本拉登的爱恨情仇"
}
POST /wyk/_doc/3
{
"content":"美国白宫里有头猪会说普通的english"
}
POST /wyk/_doc/4
{
"content":"川普!=川建国"
}查询
使用命令查看分词的效果,三种模式:
如,查看"中华人民共和国" 在ik分词下的效果和默认情况的效果:
#ik分词 max模式 "细粒度"
GET /csdn/_analyze
{
"text":"普通的",
"tokenizer": "ik_max_word"
}
#ik分词 smart模式 "粗粒度"
GET /csdn/_analyze
{
"text":"普通的",
"tokenizer": "ik_smart"
}
#ES默认,中文每个字符一个词
GET /csdn/_analyze
{
"text":"普通的",
"tokenizer": "standard"
} 


然后我们查询上面造的数据中包含"普通的"关键字的数据,如下图所示,可以看到,因为wyk索引下没有使用ik分词,因此只要数据中有"普","通","的" 三个字符之一的结果都会展示出来,而在索引csdn因为用了ik分词,ik分词下"普通的"会被分为"普通"和"的",因此只有包含了"普通"或"的"的结果才会显示:
GET /csdn/_doc/_search
{
"query": {
"match": {
"content": "普通的"
}
}
}
GET /wyk/_doc/_search
{
"query": {
"match": {
"content": "普通的"
}
}
}


查询高亮
很多时候我们在百度,或者CSDN进行搜索的时候,返回给我们的结果会把我们的查询关键字高亮显示,很直观的就可以看到自己想要的信息,像下面这样的查询结果高亮显示,使用ik可以很方便的将匹配到的结果加上标签返回,对前端开发很友好,我们也可以根据标签的位置看出分词的效果:
GET /csdn/_doc/_search
{
"query": {
"match": {
"content": "普通的"
}
},
"highlight": {
"pre_tags" : ["<strong>", "<tag2>"],
"post_tags" : ["</strong>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}


自定义词库
业务词汇或者是人名或者是新出来的网络词汇,在分词器中都无法正确的识别,我们可以自己为IK分词器扩展词库,这里演示如何使用nginx上的远程静态文件来配置词汇:
准备工作
在nginx服务器上准备一个.txt文件,必须是utf-8编码: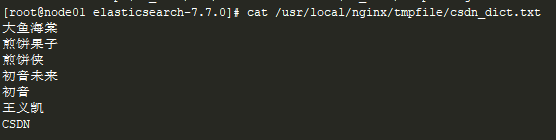
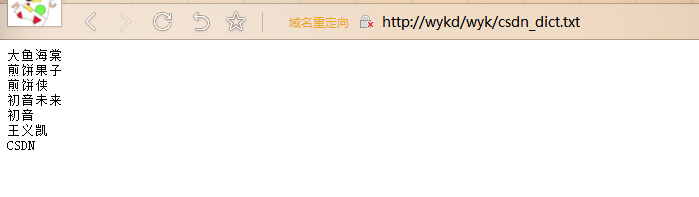
配置
修改ik分词库的配置文件:
vim /opt/app/elasticsearch-7.7.0/plugins/ik/config/IKAnalyzer.cfg.xml
<!--修改这一行即可,指向自己的远程静态文件-->
<entry key="remote_ext_dict">http://wykd/wyk/csdn_dict.txt</entry> 重启ES
修改了插件配置之后需要重启,如果之后对远程的词库.txt文件修改就不需要再重启ES了,该插件支持热更新分词。
#jps查看es进程杀掉ES
kill -9 xxxx
#启动
sudo -u elk nohup $ES_HOME/bin/elasticsearch >> $ES_HOME/output.log 2>&1 &验证
如上图,我在词库里加了一个"王义凯"的单词,在使用ik分词分析的时候会当成一个词,而默认的分词只会当做三个字去处理:


测试扩展词库的分词效果:
POST /csdn/_doc/1
{
"content":"正义不会缺席"
}
POST /csdn/_doc/2
{
"content":"国王的新衣"
}
POST /csdn/_doc/3
{
"content":"等待你们的凯旋而归"
}
POST /csdn/_doc/4
{
"content":"这是王义凯的博客"
}
POST /wyk/_doc/1
{
"content":"正义不会缺席"
}
POST /wyk/_doc/2
{
"content":"国王的新衣"
}
POST /wyk/_doc/3
{
"content":"等待你们的凯旋而归"
}
POST /wyk/_doc/4
{
"content":"这是王义凯的博客"
} 

----------------------
Q:ik_max_word 和 ik_smart 什么区别?
A:ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
希望本文对你有帮助,请点个赞鼓励一下作者吧~ 谢谢!