1.提出需求
这是群里面一位朋友提出来的一个问题。具体需求是怎么样的呢?有这样一个word文档,里面有一个hin长hin长的json字符串格式的数据。朋友想做的就是提取word文档里json数据中的content和option后面的内容。
2.原始数据预览
仔细观察下面的数据。一眼看过去是不是一团糟的样子?这只是其中一部分,如果让你一个个复制粘贴,你受得了吗?如果有更多个word,你是否也准备一个个复制、粘贴呢?

3.解决问题
我的思路是这样的:首先是读取word文档里面的内容,虽然这里只提供一个word文档,你可以直接复制出来,假如有多个这样的word文档呢?接着,利用json.loads()将json字符串转换为json字典格式数据。最后我们利用python字典的特性获取我们想要的信息。
from docx import Document
import re
import pandas as pd
import json
# 1.读取word文档,获取word文档里面的内容
x = ""
doc = Document(r"G:\1Pycharm_Project\3572(1).docx")
for paragraph in doc.paragraphs:
text = paragraph.text
# 读取word里面的内容有一个特点:每一页会返回一个字符串,共3页,一共返回了3个单独的字符串。
# 但是这是一个完整的json字符串,我们不能将他分开呀。因此,使用字符串拼接,将其合并起来。
x += text
# 2.使用json.loads()将json字符串 转换为 字典格式的数据。
r = json.loads(x)
# 3.对于字典,我们可以利用键,获取里面的值。
x = []
z = []
for i in r["data"]["ques"]:
x.append(i["content"])
y = ""
for j in i["options"]:
y += j["answer"] + " " + j["option"]
y += ";"
z.append(y)
# 4.将获取到的数据,保存成一个DataFrame格式的数据,并导出为excel表格。
data = {"content":x,"options":z}
df = pd.DataFrame(data)
display(df)
df.to_excel("text.xlsx")
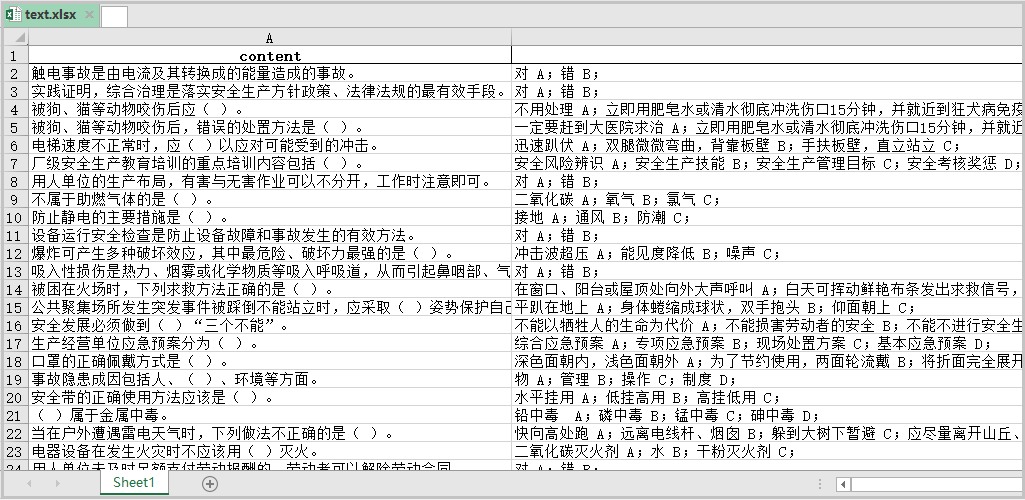
结果如下:
如果想学习文中设计的python办公自动化,我花了整整一周时间,给你准备了97页的学习资料,详细见下文:
https://mp.weixin.qq.com/s/W0Xp1nsJUpN7lTTcgSgtQQ
关注微信公众号『数据分析与统计学之美』,后台回复“高清图谱”自动获取8张高清知识图谱。
