**
32.正则表达式(爬虫必修)
**
使用re模块
***group()方法的使用
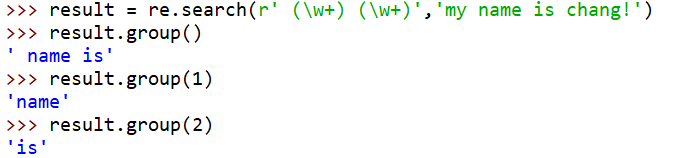
***编译标志


***模式对象
temp = re.compile(r’[a-z]’)
temp.findall(‘ha123ha’)
1—re.seach(r’规则’,”文本”)
r表示原始字符串
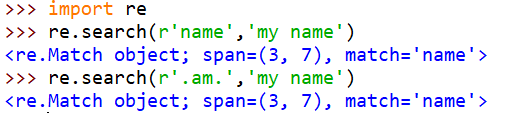
点号可用代表任何符号(除\)
. 表示( . )本身
\d表示任何数字
\数 表示重复;\三位数 表示八进制字符

$ 和 \Z 表示结尾
^ 和 \A 表示开头

[ ]表示内部都为字符,除一些特殊字符(- \ ^)
{ }表示前个字母重复次数(可为0),内部可用是个范围
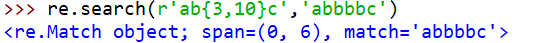
-表示范围

例:(查找0-255的数)

分析:000-199 或 200-249 或250-255
2---findall(r’规则’,”文本”)
找到符合条件的输出列表
例:

[ ] 内^放在最前表示取反,最后表是本身,例:

+表示匹配子表达式一次或多次

*表示匹配子表达式零次或多次

? 表示匹配子表达式零次或一次
默认在符合条件下尽可能多匹配,用?可限制一次

\s 表示空白字符(\t \n \r \f \v)
\w 表示单词字符(汉字、字母、数字、下划线)

其他 \字符 见表!