Softmax分类器
最常用的两个线性分类器,一个是SVM,另一个就是Softmax分类器。softmax分类器可以理解成逻辑回归分类器面对多个分类的一般化归纳。
评分函数(score function)
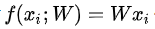
评分函数与SVM分类器相同,保持不变。
损失函数(loss function)
将SVM分类器中的折页损失(hinge loss)替换为交叉熵损失(cross-entropy loss),公式如下:
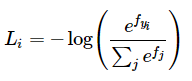
等价于:
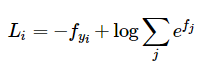
整个数据集的损失值是数据集中所有样本数据的损失值Li的均值与正则化损失R(W)之和。
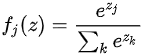
上式被称作softmax函数:其输入值是一个向量,向量中元素为任意实数的评分值(z中的),函数对其进行压缩,输出一个向量,其中元素值在0到1之间,且所有元素之和为1。
SVM和Softmax的比较
下图有助于区分Softmax和SVM这两种分类器:
 Softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。
Softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。
求解梯度dW来得到最优W
具体求解过程如下:
运用链式法则,考虑两种情况,分别对
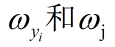
求偏导,最后得到dW。
具体实现过程:
1. 数据载入和数据预处理



2. 实现非完全矢量化的损失函数和梯度函数
(1)实现非完全矢量化损失函数和梯度函数代码

(2)随机取一个W来计算一下loss
- 对于使用Softmax分类器的CIFAR-10,我们期望初始损失为2.302,因为我们期望每个类的随机概率为0.1(因为有10个类),而Softmax损失是正确类的负对数概率,因此:-ln(0.1) = 2.302

(3)实现非完全矢量化的解析梯度表达式,并与数值梯度法进行检查,看分析梯度表达式求解的正确性

由运行结果可知,分析梯度表达式无误。
3. 实现完全矢量化的损失函数和梯度函数
(1)代码实现

(2)非完全矢量化的损失函数和梯度函数vs完全矢量化的损失函数和梯度函数(对比时间)

4. 训练和预测
(1)代码实现
训练部分就包括了使用SGD优化损失函数,得到使得损失函数最小的W,之后又使用了验证集来调整学习率和正则化强度

(2)运行结果如下图:

5. 采用目前最好的学习率、正则化强度和训练完成的W,对测试集进行预测
(1)预测正确率

结果如上,正确率为35.8%
(2)可视化最终学习的权重
