文章目录
Spark内核解析(三) Task级调度(源码解析)
前面有篇博文已经讲解了基本的任务调度机制,这篇博文的目的是剖析Task级调度,来更好的理解Driver和Executor之间任务的分发。Task级调度比Stage级调度要复杂很多,这也是为什么要专门写一篇文章的原由。
前篇博文地址:
https://blog.csdn.net/Sarahdsy/article/details/106650319
https://blog.csdn.net/Sarahdsy/article/details/106845348
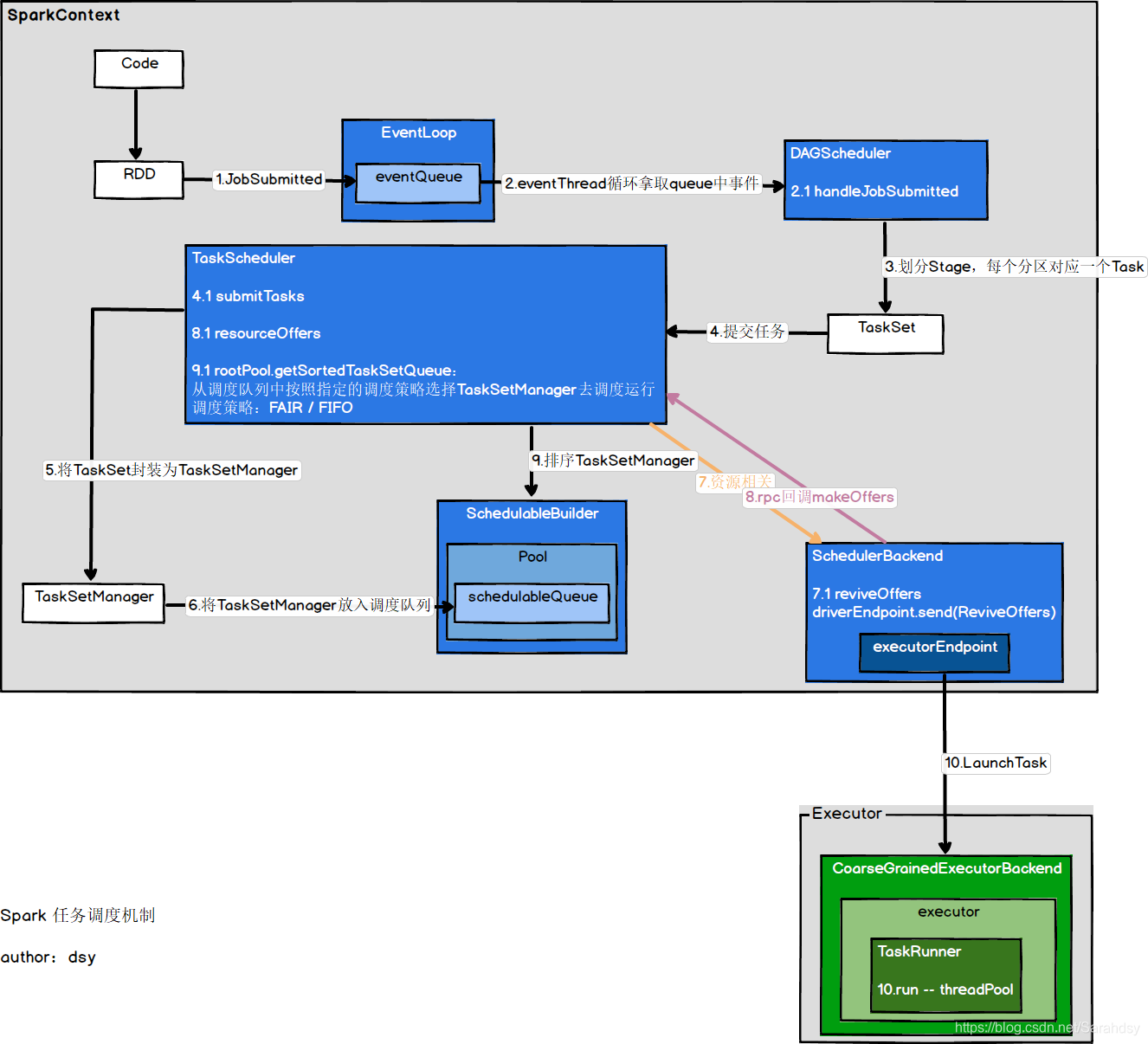
DAGScheduler -->TaskScheduler
- 接下来,我们从DAGScheduler和TaskScheduler的衔接处开始讲起
注意:文章贴出来的源码都只是部分,并非完整,为的是更好的理解
private def submitMissingTasks(stage: Stage, jobId: Int) {
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
}
if (tasks.size > 0) {
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
}
}
taskScheduler.submitTasks:DAGScheduler将Stage打包成TaskSet,交给TaskScheduler
TaskScheduler提交任务
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
}
backend.reviveOffers()
}
将TaskSetManager加入到调度队列
schedulableBuilder.addTaskSetManager(manager,
manager.taskSet.properties)
TaskScheduler会将TaskSet封装为TaskSetManager,并加入到调度队列中。
SchedulableBuilder是特质,有两个子类:FIFOSchedulableBuilder,FairSchedulableBuilder
- 默认使用的是FIFOSchedulableBuilder,所以我们进入到它的方法中可以看到,将taskSetManager加入到了调度队列中。
override def addTaskSetManager(manager: Schedulable, properties: Properties) {
rootPool.addSchedulable(manager)
}
- rootPool是在SchedulableBuilder构造的时候传入的,所以我们可以在TaskSchedulerImpl中搜索下,可以找到下面代码:
def initialize(backend: SchedulerBackend) {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
- 再去搜索rootPool的赋值,可以看到如下代码:
val rootPool: Pool = new Pool("", schedulingMode, 0, 0)
- 查看下Pool的结构,可以看到它的一个重要属性:调度队列
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable]
- 现在可以来看看addSchedulable了,可以确信将manager加入了调度队列中
override def addSchedulable(schedulable: Schedulable) {
require(schedulable != null)
schedulableQueue.add(schedulable)
schedulableNameToSchedulable.put(schedulable.name, schedulable)
schedulable.parent = this
}
RPC通知自身启动任务
backend.reviveOffers()
SchedulerBackend是特质,有两个子类:CoarseGrainedSchedulerBackend,LocalSchedulerBackend
- Yarn-Cluster模式使用的是CoarseGrainedSchedulerBackend,所以我们进入该类中看相应的方法
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}
driverEndpoint是RpcEndpointRef类型,也就是说给自己发送了消息。这里使用了RPC通信机制,Spark中使用的是Netty(AIO)框架,基于Actor模型,消息统一进行调度,所以当接收到消息后,最终会调用RpcEndpoint的receive方法。
- 所以我们在当前类中搜索ReviveOffers,可以看见在receive方法中进行了模式匹配,调用了makeOffers方法。
private def makeOffers() {
// Make sure no executor is killed while some task is launching on it
val taskDescs = withLock {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort))
}.toIndexedSeq
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
launchTasks(taskDescs)
}
}
资源提供相关
- 这里的scheduler指的是TaskScheduler,由构造方法传入。进入到该类的相应方法中,关注如下代码:
val sortedTaskSets: ArrayBuffer[TaskSetManager] = rootPool.getSortedTaskSetQueue
这行代码指的是:TaskScheduler从调度队列中按照指定的调度策略选择TaskSetManager去调度运行。
- rootPool之前已经看过了,就是个调度队列。主要看getSortedTaskSetQueue方法
override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
val sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
}
- 将调度队列按照特定的调度策略进行排序,关键是taskSetSchedulingAlgorithm
private val taskSetSchedulingAlgorithm: SchedulingAlgorithm = {
schedulingMode match {
case SchedulingMode.FAIR =>
new FairSchedulingAlgorithm()
case SchedulingMode.FIFO =>
new FIFOSchedulingAlgorithm()
case _ =>
val msg = s"Unsupported scheduling mode: $schedulingMode. Use FAIR or FIFO instead."
throw new IllegalArgumentException(msg)
}
}
- 模式匹配调度策略,来决定使用哪种排序算法。默认是FIFO,那我们就看看它的实现吧
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0) {
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
}
res < 0
}
}
可以看到,先比较的是优先级,再比较的是阶段id
- FAIR跟两个参数有关系:share,weight
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0)
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0)
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
var compare = 0
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
s1.name < s2.name
}
}
}
运行任务
- 调用launchTasks运行任务
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
向executorEndpoint发送LaunchTask消息,通过RPC在Executor上运行Task。
到这里,在Driver上的Task调度已经完成,接下来就是看Executor接收到LunchTask消息的处理了。
Executor执行任务
- 因为是Yarn-Cluster模式,我们就看CoarseGrainedExecutorBackend类
- 还是老方法,使用RPC通信的,只需要看终端类的receive方法,然后匹配相应的消息,就可以了
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskDesc)
}
- 最终调用了计算对象的launchTask方法
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
}
- 将任务封装成了TaskRunner,并放进线程池中运行,那么我们就去看TaskRunner类的run方法。关键看这行代码:
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
- 进入Task类的run方法,查看模板方法runTask。Task是抽象类,有两个子类:ShuffleMapTask,ResultTask
嗯,是的。接下来就是调用我们相应任务类的runTask方法。
上文提到过的ShuffleMapStage和ResultStage对应的就是ShuffleMapTask和ResultTask。
要讲它们会涉及到Shuffle解析,所以打算另外再写一篇博客来具体说明。
总结
此篇博文讲的仅仅是Task级调度,要想了解具体的任务调度机制,可以查看我另一篇博文。
还是以图形化的方式来做个小结吧。