爱死这个小破站了。。。。。
主要参考大佬的文章,脑补链接,,也不用像这个这么复杂,咱就简简单单的挺好,,,,hhhhh
import requests,threading,re,json,os,time
from lxml import etree
from queue import Queue
headers = {
'Connection': 'keep-alive',
'Referer': 'https://www.bilibili.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
video_queue = Queue(100)
def single_data(url):
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
title = html.xpath('//div[@id="viewbox_report"]/h1/@title')[0]
print('下载:',title)
data = re.search(r'__playinfo__=(.*?)</script><script>',resp.text).group(1)
data = json.loads(data)
try:
time = data['data']['dash']['duration']
minute = int(time)//60
second = int(time) % 60
video_url = data['data']['dash']['video'][0]['baseUrl']
audio_url = data['data']['dash']['audio'][0]['baseUrl']
video_queue.put([video_url,audio_url,title])
except KeyError:
time = data['data']['timelength'] // 1000 # 我发现其实有些小视频的格式是不一样的,,,
minute = int(time) // 60 # 这种就是一个视频,不用合并音频,,视频啥的了。。
second = int(time) % 60
video_url = data['data']['durl'][0]['url']
video_queue.put([video_url,title])
print('视频时长{}分{}秒'.format(minute, second))
def download():
while not video_queue.empty():
data = video_queue.get()
if len(data)==3:
print('%s 开始下载' % data[2])
data[2]=re.sub(r'[\\/:\*\?<>\|"]', '', data[2])
with open('%s_video.mp4' % data[2],'wb') as f:
resp = requests.get(data[0],headers=headers)
f.write(resp.content)
with open('%s_audio.mp4'% data[2],'wb') as f:
resp = requests.get(data[1],headers=headers)
f.write(resp.content)
video_audio_merge(data[2])
else:
data[1]=re.sub(r'[\\/:\*\?<>\|"]', '', data[1])
with open('%s_video.mp4' % data[1],'wb') as f:
resp = requests.get(data[0],headers=headers)
f.write(resp.content)
print('%s下载完成' % data[1])
def video_audio_merge(video_name):
print("视频合成开始:%s" % video_name)
import subprocess
command = 'ffmpeg -i "%s_video.mp4" -i "%s_audio.mp4" -c copy "%s.mp4" -y -loglevel quiet' % (
video_name, video_name, video_name)
subprocess.Popen(command, shell=True)
print("视频合成结束:%s" % video_name)
def main():
url = input('输入下载链接(例如:https://www.bilibili.com/video/av91748877?p=1,https://www.bilibili.com/video/av91748877?p=2)多视频请用英文逗号分隔:\n')
urls = url.split(',')
for each in urls:
single_data(each)
time.sleep(1)
for x in range(3):
th = threading.Thread(target=download)
th.start()
if __name__ == '__main__':
main()
额。。。。下面这个就是删除下载下来的分离文件,保留最后合并的就行,,,但是这个合不进去啊,,,老是报错 这个有其他进程操作啥的。。。。。。按理说加上锁应该没问题啊,但是就是不行,,,,,,果然是我太菜了,,,如果有大佬指点一下就好了,,,,,,,
import os
file_list = os.listdir()
for file in file_list:
if file.endswith('_video.mp4') or file.endswith('_audio.mp4'):
os.remove(file)
pyinstaller
我们写的程序只能我们自己用太不爽了,,,,,打包成exe文件,让你的朋友佩服一下,,嘿嘿嘿,,,
感谢大佬啊!!!脑部链接
下载
额,安装不上百度一下吧,,,
pip install pipinstaller
两种打包模式
可以打包成一个文件夹,或者就是一个文件
- 文件夹模式
# hi.py
import os
name = input('你的名字是:')
print('hi!'+name)
os.system('pause') # 暂停程序
然后再命令行中输入pyinstaller 路径 hi.py
或者再那个文件夹下 shift + 右键,选择,输入pyinstall hi.py
然后我们我们的文件夹中就多出来三个文件夹,bulid dist hi.spec。可执行的文件就在dist文件夹中,这里面东西还不少,,,
- 单文件模式
只要pyinstaller -F hi.py 打包成功后,再dist文件夹中就只有 hi.exe文件啦,,,
但是这种模式通常遇到的问题和麻烦比较多
总之,打包结束后,pyinstaller会在build 文件夹中生成一些日志文件以及工作文件,再dist文件中是已经打包好的文件,spec文件中存储着打包时所用的命令以及打包的相关文件,它的作用就是高数pyinstaller如何来进行处理。。
所以当你要装逼时:
-用文件夹模式打包,要把整个hi文件夹发过去,然后点击hi.exe来运行
- 单文件,吧那个hi.exe发过去就好
build文件夹和spec文件跟程序运行没有关系,可以删掉。
最后来简简单单的打包一下
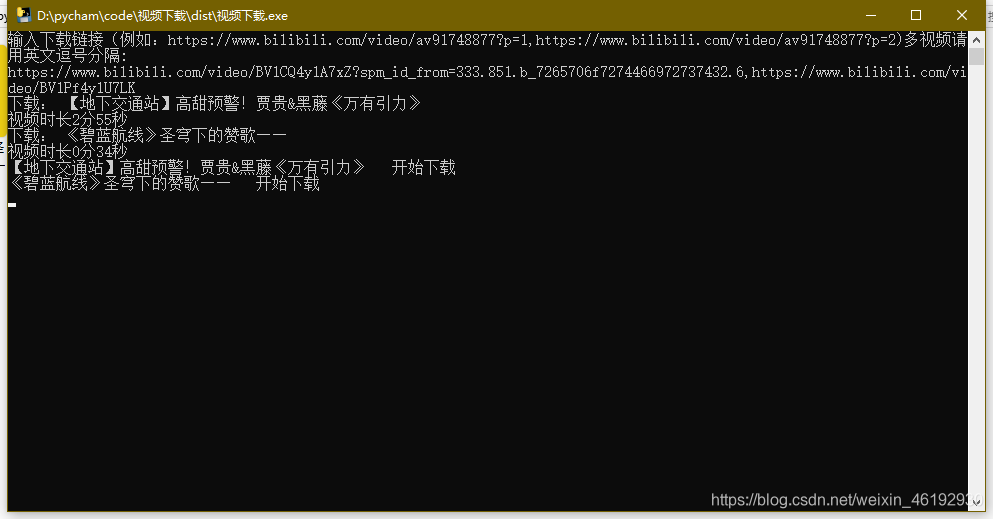
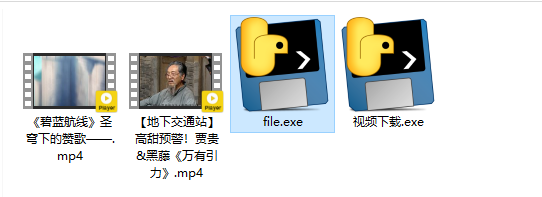
嗯。。。我才刚刚接触 tkinter 等以后一定写个漂亮的GUI。。。。。。
最后祝愿我今天下午碧蓝航线的活动-----十连毕业啊!!!!!!!!!!!!!!!