先上源码:
/** RDD.scala
* Return an RDD of grouped items. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
* 返回分组项的RDD,每个分组包含一个key和这个key对应的元素的一个序列,不保证序列的顺序。
*
* @note This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using `PairRDDFunctions.aggregateByKey`
* or `PairRDDFunctions.reduceByKey` will provide much better performance.
* 注意:This operation may be very expensive.
* 如果要在每一个key上做聚合操作(比如sum/average),建议用reduceByKey/aggregateByKey来获得更好的性能。
*/
def groupBy[K](f: T => K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null)
: RDD[(K, Iterable[T])] = withScope {
val cleanF = sc.clean(f)
this.map(t => (cleanF(t), t)).groupByKey(p)
}
/************************* groupByKey *****************************/
/**
* PairRDDFunctions.scala
*/
def groupByKey(): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(defaultPartitioner(self))
}
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(new HashPartitioner(numPartitions))
}
/**
* @note As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an `OutOfMemoryError`.
*/
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
@Experimental
def combineByKeyWithClassTag[C](
createCombiner: V => C, // 默认操作是改变VALUE的类型为C
mergeValue: (C, V) => C, // 按C归并V,预聚合操作
mergeCombiners: (C, C) => C, // reduce
partitioner: Partitioner, // 分区对象
mapSideCombine: Boolean = true, // 是否开启map端聚合,默认开启
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
/************************* reduceByKey *****************************/
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = self.withScope {
reduceByKey(new HashPartitioner(numPartitions), func)
}
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce.
*/
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}reduceByKey 和 groupByKey 都是通过combineByKeyWithClassTag函数实现的。
但是它们调用combineByKeyWithClassTag的参数不同,返回值不同。
- 先看返回值,groupByKey()返回值是RDD[(K, Iterable[V])],包含了每个key的分组数据。reduceByKey()的返回值是RDD[(K, C)],只是一个普通的RDD。
- 再看调用参数,groupByKey调用时的泛型参数是CompactBuffer[V]:
combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
注意,groupByKey 把mapSideCombine设置成了false!关闭了map端预聚合。
- reduceByKey调用时的泛型参数是V:
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
reduceByKey的createCombiner对象参数是(v: V) => v ;mergeValue 和 mergeCombiners 都是 func,
partitioner不变,mapSideCombine使用默认值 true.
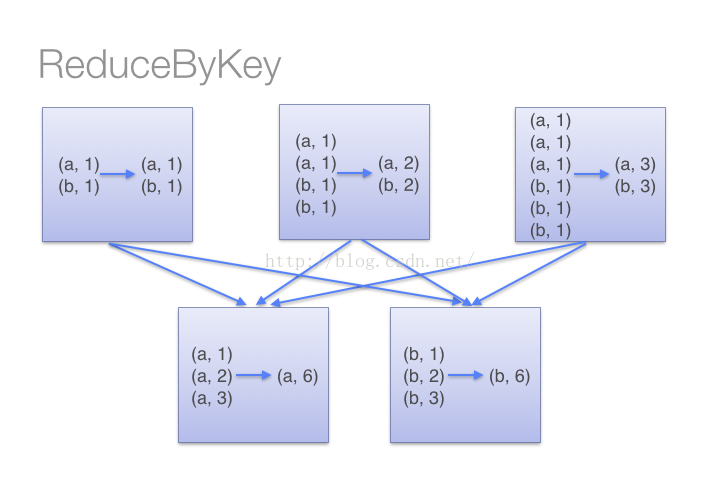
reduceByKey 和 groupByKey最大不同是mapSideCombine 参数,它决定是是否会先在节点上进行一次 Combine 操作。
从二者的实现可见,reduceByKey对每个key对应的多个value进行merge操作,最重要的是它能够在本地进行merge操作,并且merge操作可以通过函数自定义。
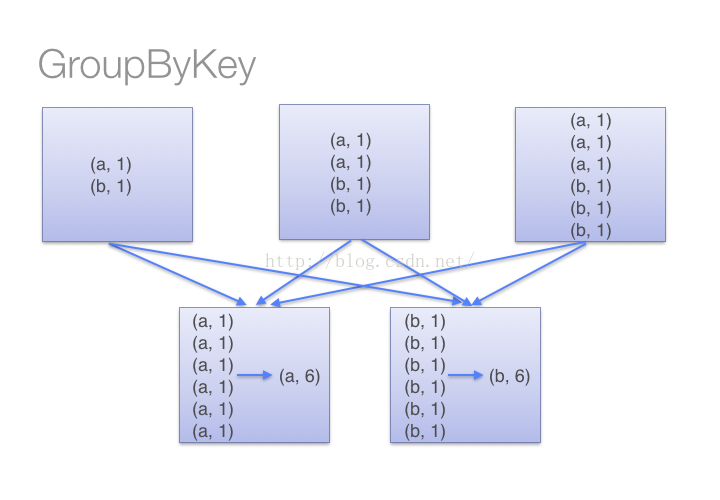
而groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
例如,通常这样使用这两个算子:
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))reduceByKey使用“ _ + _ ”这样的自定义函数来预聚合,groupByKey没有这种参数,
当调用groupByKey时,所有的 key-value pair 都会被移动,发送本机所有的map,在一个机器上suffle,集群节点之间传输的开销很大。
如图:
That's all.
Ref:
https://blog.csdn.net/zongzhiyuan/article/details/49965021