上一篇文章讲了超参数调节的一些理论基础,相信你已经对超参数有了一定的认识,对于手动调整超参数的方法,文章里也算是提供了一些启发式的方法:
从入土到入门学习超参数的调整
这篇文章,我们重点来探讨一下自动调参的方法,我们先从网格搜索开始,并结合手写数字识别作为案例,框架用的是paddlepaddle,完整项目我已经在AI Studio公开:
https://aistudio.baidu.com/aistudio/projectdetail/511378
下面是具体步骤:
1. 导入相关库
导入库这块就不用多说了吧,这不是本篇文章的重点:
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
import os
2. 定义超参数
这里我选择了5种超参数,其实准确说应该更多:
# 定义超参数
BUF_SIZEs = np.arange(64,640,64,dtype=int) #512
BATCH_SIZEs = np.arange(64,640,64,dtype=int) #128
ActivationFunctions = ['relu', 'softmax' ,'tanh'] #[ 'elu', 'relu6', 'pow', 'stanh', 'hard_sigmoid', 'swish', 'prelu', 'brelu', 'leaky_relu', 'soft_relu', 'thresholded_relu', 'maxout', 'logsigmoid', 'hard_shrink', 'softsign', 'softplus', 'tanh_shrink', 'softshrink', 'exp']
LearningRates = np.arange(0.01,0.12,0.04,dtype=float) #0.01
EPOCH_NUMs = np.arange(1,2,1,dtype=int)
先来讲讲每个超参数的含义
BUF_SIZEs
BUF_SIZEs表示每次缓存BUF_SIZEs个数据项,并进行打乱
这里我给定的范围是64-640,间隔64,也就是说,区间大小是9
当然,这里可以把范围设置成1-1000,间隔为1,那么区间就是1000
BATCH_SIZEs
BATCH_SIZEs表示每BATCH_SIZEs组成一个batch
这里可以理解为一个批次读取的数据大小
我这里把BATCH_SIZE的范围设置成跟BUF_SIZE一样,当然你也可以选择把区间扩大
ActivationFunctions
PaddlePaddle Fluid 对大部分的激活函数进行了支持,一共有22种:
relu, tanh, sigmoid, elu, relu6, pow, stanh, hard_sigmoid, swish, prelu, brelu, leaky_relu, soft_relu, thresholded_relu, maxout, logsigmoid, hard_shrink, softsign, softplus, tanh_shrink, softshrink, exp。
我把这22个激活函数都放在了一个列表里,但是我实际训练时只用3个,具体原因我将在下面详细说明
LearningRates
代码里使用Adam算法对学习率进行了优化,这里给的学习率是初始学习率
Adam 的优化器是一种自适应调整学习率的方法,能自动的调整初始学习率,让学习率随着训练的进行逐渐降低
学习率我也给定了一个范围,要想精度更高的话,可以把区间设置得密一些
EPOCH_NUMs
EPOCH_NUMs是迭代的次数,这个超参数应该是大家最熟悉的超参数吧
因为我们现在只是寻找最优的超参数,迭代次数可以不用设的太高,当然也要根据你做的模型选择合适的迭代次数,不过一般在前几轮就能发现某些超参数到底好不好,所以其实也没有必要设置得太高
3. 配置网格搜索
这里我写成了一个类,方便我读取超参数,也便于大家理解:
class GridSearch(object):
def __init__(self, BUF_SIZE, BATCH_SIZE, HiddenActivationFunction, PredictionActivationFunction, LearningRate, EPOCH_NUM):
self.BUF_SIZE = BUF_SIZE
self.BATCH_SIZE = BATCH_SIZE
self.HiddenActivationFunction = HiddenActivationFunction
self.PredictionActivationFunction = PredictionActivationFunction
self.LearningRate = LearningRate
self.EPOCH_NUM = EPOCH_NUM
self.best_accs = 0
self.best_costs = 10
# 定义多层感知器
def multilayer_perceptron(self, input):
# 第一个全连接层,激活函数为ReLU
hidden1 = fluid.layers.fc(input=input, size=100, act=self.HiddenActivationFunction)
# 第二个全连接层,激活函数为ReLU
hidden2 = fluid.layers.fc(input=hidden1, size=100, act=self.HiddenActivationFunction)
# 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
prediction = fluid.layers.fc(input=hidden2, size=10, act=self.PredictionActivationFunction)
return prediction
def toString(self):
parameter = self.model_train()
self.best_accs = parameter[1]
self.best_costs = parameter[0]
OptimalHyperparameter = ["BUF_SIZE:", BUF_SIZE, " BATCH_SIZE:", BATCH_SIZE, " HiddenActivationFunction:", HiddenActivationFunction, " PredictionActivationFunction:", PredictionActivationFunction, " LearningRate:", LearningRate, " EPOCH_NUM:", EPOCH_NUM, " test_costs:", self.best_costs, " test_acc:", self.best_accs]
return OptimalHyperparameter
def model_train(self):
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.train(),
buf_size=self.BUF_SIZE),
batch_size=self.BATCH_SIZE)
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
test_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.test(),
buf_size=self.BUF_SIZE),
batch_size=self.BATCH_SIZE)
# 输入的原始图像数据,大小为1*28*28
image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32')#单通道,28*28像素值
# 标签,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64') #图片标签
# 获取分类器
predict = self.multilayer_perceptron(image)
#使用交叉熵损失函数,描述真实样本标签和预测概率之间的差值
cost = fluid.layers.cross_entropy(input=predict, label=label)
# 使用类交叉熵函数计算predict和label之间的损失函数
avg_cost = fluid.layers.mean(cost)
# 计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=label)
#使用Adam算法进行优化, learning_rate 是学习率(它的大小与网络的训练收敛速度有关系)
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=self.LearningRate)
opts = optimizer.minimize(avg_cost)
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
use_cuda = True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 获取测试程序
test_program = fluid.default_main_program().clone(for_test=True)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
# 模型训练
model_save_dir = "/home/aistudio/work/hand_inference.model"
for pass_id in range(self.EPOCH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()): #遍历train_reader
train_cost, train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #给模型喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
# 每200个batch打印一次信息 误差、准确率
if batch_id % 200 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_accs = []
test_costs = []
#每训练一轮 进行一次测试
for batch_id, data in enumerate(test_reader()): #遍历test_reader
test_cost, test_acc = exe.run(program=test_program, #执行训练程序
feed=feeder.feed(data), #喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
test_accs.append(test_acc[0]) #每个batch的准确率
test_costs.append(test_cost[0]) #每个batch的误差
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs)) #每轮的平均误差
test_acc = (sum(test_accs) / len(test_accs)) #每轮的平均准确率
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print ('save models to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir, #保存推理model的路径
['image'], #推理(inference)需要 feed 的数据
[predict], #保存推理(inference)结果的 Variables
exe) #executor 保存 inference model
print('训练模型保存完成!')
return test_cost,test_acc
我把数据读取,定义优化器,训练代码等写到了这个名为model_train得方法里,更换新的超参数时,我们直接调用这一个方法即可,目的就是为了简洁明了
toString方法是用来保存超参数的配置的,找到超参数以后还需要做个记录,这也是我们的目的
4. 寻找最优超参数
下面是最关键的核心部分:
Hyperparameters = []
OptimalHyperparameter = []
best_acc = 0
best_cost = 10
for BUF_SIZE in BUF_SIZEs:
# print(BUF_SIZE)
for BATCH_SIZE in BATCH_SIZEs:
for HiddenActivationFunction in ActivationFunctions:
for PredictionActivationFunction in ActivationFunctions:
for LearningRate in LearningRates:
for EPOCH_NUM in EPOCH_NUMs:
print("BUF_SIZE:", BUF_SIZE, " BATCH_SIZE:", BATCH_SIZE, " HiddenActivationFunction:", HiddenActivationFunction, " PredictionActivationFunction:", PredictionActivationFunction, " LearningRate:", LearningRate, " EPOCH_NUM:", EPOCH_NUM)
grid = GridSearch(BUF_SIZE, BATCH_SIZE, HiddenActivationFunction, PredictionActivationFunction, LearningRate, EPOCH_NUM)
# grid.model_train()
Hyperparameters.append(grid.toString())
if (grid.best_accs > best_acc and grid.best_costs < best_cost and grid.best_costs >= 0):
OptimalHyperparameter = grid.toString()
best_acc = grid.best_accs
best_cost = grid.best_costs
print(OptimalHyperparameter)
for Hyperparameter in Hyperparameters:
print(Hyperparameter)
print(OptimalHyperparameter)
我定义了两个列表,分别用来存储所有超参数的组合和最优的超参数组合
另外,怎么确定最优超参数组合呢?
自然是看测试时的cost和accuracy了,这里我先把cost和accuracy分别设置为10和0,即最低标准
然后来6个for循环,组合出所有的超参数组合
到这里,你应该明白我为什么没有把超参数的范围设置太大的原因了吧?
如果范围设置的过大,且精度高的话,这计算量是非常大的
比如我们有6个超参数,每个范围都是1-100且精度是1的话,那么我们所需的搜索次数是100 * 100 * 100 * 100 = 100^4
如果再增加一个超参数,那么所需的搜索次数是100^5,搜索时间指数级上升,如果模型再复杂一点,这计算量是非常大的,我运行手写数字识别的时候用的是GPU v100,每一次搜索的时间都要在1分钟左右。
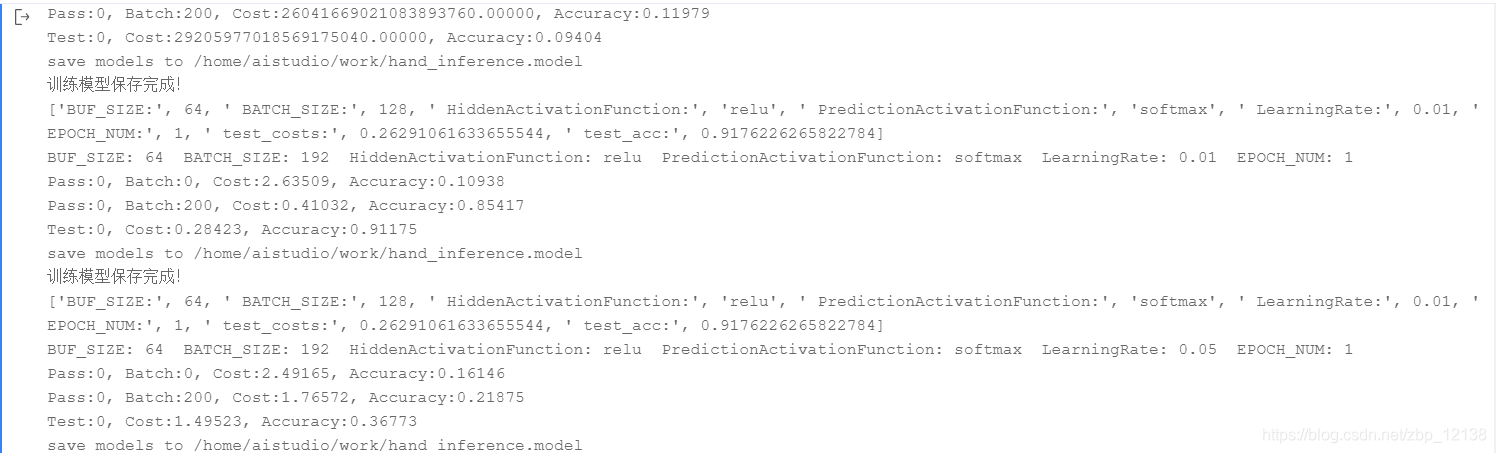
我没有完全地运行完,不过我找到了一组还算可以的超参数,因为它好几个回合都没有被刷下来:
[‘BUF_SIZE:’, 64, ’ BATCH_SIZE:’, 128, ’ HiddenActivationFunction:’,
‘relu’, ’ PredictionActivationFunction:’, ‘softmax’, ’ LearningRate:’,
0.01, ’ EPOCH_NUM:’, 1, ’ test_costs:’, 0.26291061633655544, ’ test_acc:’, 0.9176226265822784]
有图为证:
当然大家也可以fork我的项目自己去体验一下效果:
手写数字识别(超参数调节之网格搜索)
不过要真正应用在模型调优上的话,我不建议使用网格搜索法,毕竟太耗资源了,时间也是个问题