1. Kafka是什么?
Kafka是一款开源的消息引擎系统,也是一个分布式的流处理平台,官网对其定位为a distributed streaming platform。
作为消息引擎,同时支持两种消息引擎模型:
- 消息队列模型(点对点模型):消息只能被一个系统使用,即每个消息只能被处理一次。
- 发布/订阅模型:存在多个发布者和多个订阅者,消息被广播给所有订阅者。
消息引擎的主要作用在于:削峰填谷、系统解耦。
作为流处理平台:
- 提供Streams API用以对数据流进行实时计算
因此,Kafka主要用于两类应用:
- 构建数据管道,在系统之间传递数据,需要提供高吞吐量和动态吞吐量已经高可用性。
- 构建流式计算应用,对数据流进行实时处理
PS:
Kafka生态:Kafka、Kafka Streams、Kafka Connect
推荐版本:0.11,已经具备了副本机制、新版本客户端、幂等性生产者API、事务、streams等重要特性,1.0和2.0版本主要是streams方面的改进,在消息引擎方面并未有太多重大功能。
2. Kafka核心概念
Kafka的基本架构
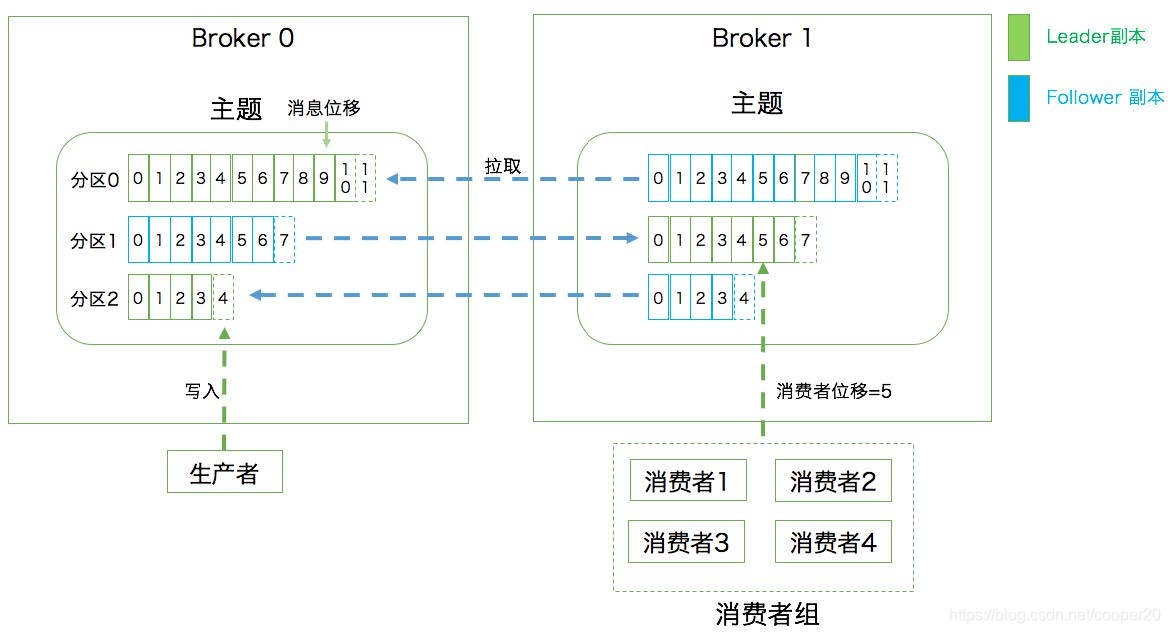
主题->分区->副本->消息
主题(Topic)
主题是发布、订阅的对象,是承载数据的逻辑容器。
生产者(Producer)
向主题发送消息的客户端,生产者可向一个或多个主题发送消息。
消费者(Consumer)
从主题拉取消息的客户端,消费者能够同时订阅多个主题的消息。
Broker
Kafka服务端,负责处理客户端请求,并对消息进行持久化。
分区
分区是Kafka Broker实现伸缩性、提供负载均衡能力的解决方案,也提高了主题生产、消费的并行度。Kafka将主题划分多个分区,每个分区是一个有序的消息日志。分区只能被群组中的一个消费者实例消费。
利用分区还可以实现一些业务级别的需求,例如实现业务消息的顺序问题。
消费者群组
为了同时实现两种消息引擎模式:点对点的消息队列模式,和发布/订阅模式,实现横向伸缩消费能力,构建高可用的消费者,Kafka引入了消费者群组概念。群组内的消费者订阅同一个主题,每个分区的所有权只能被一个消费者持有,多余的消费者会处于idle状态。
再均衡(Reblance)
在群组内重新分配分区所有权的过程称为再均衡,其为消费者群组提供了高可用性和伸缩性。当群组内的消费者发生故障或者主题分区数量发生改变是,均会触发再均衡。再均衡会导致群组处于短暂的不可用状态。
副本(Replica)
复制和分区多副本机制是Kafka Broker的高可用实现方案,Kafka将一个分区的数据拷贝到多个Broker上。副本分为两类:领导者副本(Leader Replica)和跟随者副本(Follower Replica)。每个分区都仅有一个领导者副本,所在broker称为分区首领,负载处理着所有生产者和消费者的请求;跟随者副本只是被动得与领导者副本进行同步,并在领导者故障时参与首领选举。
在一些数据存储系统中,例如MySQL、Redis做读写分离,从库是可以处理读操作的。Kafka为什么不这么设计?
答
- 使用场景:Kafka常用作消息引擎而不是数据存储,其使用场景并不属于读多写少的。
- Kafka的多分区机制,分区(副本、领导者副本)一般均匀地分布在不同的Broker上,已经起到了负载均衡的作用。
- 更容易保证数据一致性,实现单调读。不会出现从多个副本读取消息而出现不一致的现象。
3. 对比
3.1 与其他消息引擎对比
Rocket擅长于金融领域场景,Kafka则发家于大数据领域。
3.1 与其他流式计算框架对比
Kafka以消息引擎起家,在大数据领域被广泛应用于数据管道的实现,与其把数据传递到下一个系统中去做处理,为何不直接在Kafka中处理呢?这就是Kafka从0.10版本推出Streams组件的原因。
- Kafka更容易实现端到端的正确性,由于所有数据流转和计算都在Kafka内部完成,故可以实现端到端的仅一次语义。
PS:Flink目前也可以实现,借助Kafka的事务。 - 仅提供流式计算客户端组件,没有提供集群调度等功能,更加适用于中小型企业。
附:Kafka知识点思维导图
参考
《Kafka权威指南》
《Kafka核心技术与实战》
官网:http://kafka.apache.org/