自然语言处理简介
什么是自然语言
自然语言是人类社会发展过程中自然产生的语言,是最能体现人类智慧和文明的产物。
它是一种人与人交流的载体,我们使用语言传递知识。这个星球上许多生物都拥有超过人类的视觉系统,但只有人类才拥有这么高级的语言。
自然语言是人类间交流传播信息知识的工具语言是思维的载体,是人类交流思想、表达情感最自然、最直接、最方便的工具,人类历史上以语言文字形式记载和流传的知识占知识总量的80%以上。
什么是自然语言处理
自然语言处理( Natural Language Processing,NLP )是一门]计算机科学、人工智能、认知科学、信息论、数学及语言学的交叉学科。
自然语言处理是人工智能的一个分支。人工智能的第三个阶段:认知智能,通俗讲是“能理解会思考”。人类有语言,才有概念,才有推理,所以概念、意识、观念等都是人类认知智能的表现。
因此, NLP被誉为“人工智能皇冠.上的明珠”
自然语言处理的研究
开始于图灵测试,经历了以规则为基础的研究方法,流行于现在基于统计学的模型和方法。
- 早期的传统机器学习方法基于高维稀疏特征的训练方式
- 现在主流的深度学习方法–使用基于神经网络的低维稠密向量特征训练模型。

自然语言处理研究内容
- 序列标注:分词/词性标注/命名实体识别/语义标注
这是最典型的NLP任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求型根据上下文都要给出一一个分类类别。 - 分类任务 :文本分类/情感分类/关系抽取
比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。 - 句子关系判断: 蕴涵/问答/自然语言推理/文本语义相似性
比如蕴涵,问答,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系。
4 .生成式任务:机器翻译/文本摘要;
比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。 它的特点是输入文本内容后,需要自主生成另外- -段文字。
基于统计的NLP方法
发展历史
- 理性主义方法: 1957~ 1980s
词法分析,句法方法,语义分析
词典、 规则-基于规则的方法(符号逻辑) - 经验主义方法: ~1950s , 1980s ~
大规模训练样本
数据驱动的统计模型-基于统计的方法(统计学习)

现在一般将理性主义与经验主义相结合
符号智能+计算智能,建立融合方法
传统的统计学习方法
传统的统计学习方法是通过经验提高性能
基本框架

常用的统计模型和开源工具
- 统计模型(生成式+区分式)
- 语言模型(language model)
- 隐马尔可夫模型(hidden Markov model, HMM)
- k-近邻法(k-nearest neighbor, k-NN) :多类分类问题
- 朴素贝叶斯法(naive Bayes) :多类分类问题
- 决策树(decision tree) :多类分类问题
- 最大熵(maximum entropy) :多类分类问题
- 感知机(perceptron) :二类分类
- 支持向量机(support vector machine, SVM) :二类分类
- 条件随机场(conditional random field, CRF) :序列标注
基于深度学习的NLP方法
概述
深度学习(Deep Learning, DL)
深度学习是一种基于特征学习的机器学习方法。把原始数据通过简单但非线性的模块转变成更高层次、更加抽象的特征表示,通过足够多的转换组合,非常复杂的函数也能被学习。
深度学习in NLP
- 2003年Bengio等提出的NPLM ,但效果并不显著,深度学习用于NLP的研究一直处在探索的阶段。
- 2011年 , Collobert等用一个简单的深度学习模型在命名实体识别NER、语义角色标注SRL、词性标注POS-tagging等NLP任务取得SOTA成绩。
- 2013年 ,以Word2vec、Glove为代表的词向量大火,更多的研究从词向量的角度探索如何提高语言模型的能力,研究关注词内语义和上下文语义。
- 此外,基于深度学习的研究经历了CNN、RNN、 Transormer等特征提取器,研究者尝试用各种机制优化语言模型的能力, 包括预训练结合下游任务微调的方法( ELMO , BERT… …)
神经语言模型
语言模型
基于马尔可夫假设, N-gram语言模型认为一-个词出现的概率只与它前面的n-1个词相关
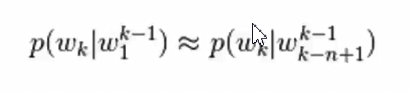
根据条件概率公式与大数定律,当语料的规模足够大时,有

■N-gram语言模型
- n的选择
一般是小于等于5. - OOV问题
即Out Of Vocabulary , 未登录词。( 设定阈值,特殊符号代替) - 平滑处理TODO
Laplace、ADD K、插值法…
神经概率语言模型
神经概率语言模型依然是一个概率语言模型 ,它通过神经网络来计算概率语言模型中每个参数
N-gram神经语言模型
经典的神经概率语言模型,它沿用了N-gram模型中的思路,将w的前n-1个词作为w的上下文context(w), 而V_ context由这n-1 个词的词向拼接而成,即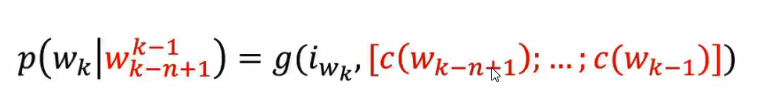
Word2vec
分布式表示——词向量表示

基于文本的词向量学习

V是数据集中的词向量个数,D是维度
■词表规模V的确定:
1 )训练数据中所有词;
2 )频率高于某个阈值的所有词;
3 )前V个频率最高的词,e.g. V= 50000, V=80000
■Mikolov2013年提出了两种模型- – CBOW和Skip-gram
与Bengio的NPL M模型相比
- 去除NPLM中的单隐层
- 不考虑词序的影响(词序并不一定影响阅读,人的阅读习惯也并非总是线性扫描的) , 各个词向量求均值向量(而非拼接)作为输入
- 不只是考虑的词的历史信息,同时考虑其下文信息
视频里还有好多,不想写了,想要的私聊我下吧,视频加ppt都给你。