《Python机器学习基础教程》第二章笔记:random_state的作用
一、random_state的作用:固定系数与截距
random_state的作用在于固定lr.coef_、lr.intercept_,保证每次模型的系数、截距一致
不加random_state时,系数与截距不停的变化:
from sklearn.linear_model import LinearRegression
import mglearn
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_wave(n_samples=60)
X_train, X_test, y_train, y_test = train_test_split(X, y)
lr = LinearRegression().fit(X_train, y_train)
print("lr.coef_:", lr.coef_)
print("lr.intercept_:", lr.intercept_)
第一次:
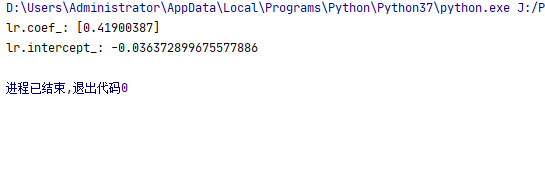
第二次:

循环一下会发现每次系数和截距均不一样:

增加random_state后:
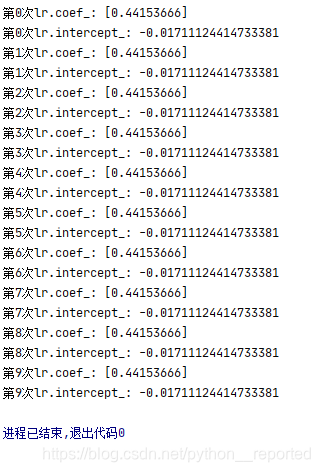
二、random_state的取值是对系数排序的结果,random_state值越小,系数越大
第一次取值
系数与截距:
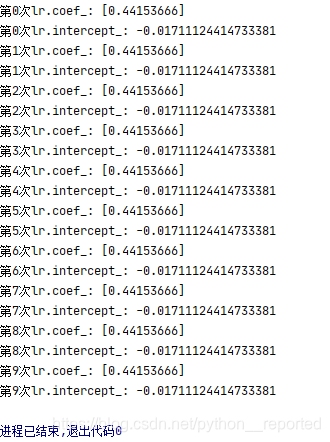
第二次取值

系数与截距:
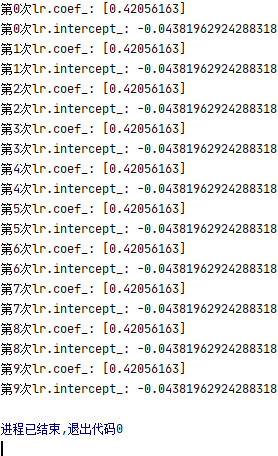
第三次取值:

系数与截距:
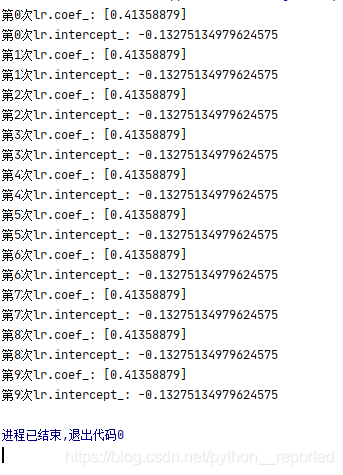
第四次取值:

系数与截距:
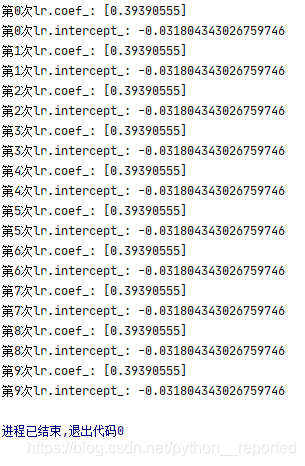
现象:系数越来越小,截距看不出来规律!!!
结论:random_state取值越小,系数越大;random_state取值越大,系数越小;两者呈现反比关系