最近复习到了线程这里,就不得不提起线程池方面的知识,由于在网上没有找到一章很全面的讲解,就准备写一篇关于线程池的知识。
先说一下讲解的知识流程吧。
1.相关类和接口的关系
2.创建的方式
3.ThreadPoolExecutor详解
4.线程池的运行流程
5.等待队列
6.拒绝策略
7.Executors的五种线程池以及内部实现原理
8.如何设置相对较优的线程数量和总结
(内容较多,不过我可以负责任的告诉大家,线程池是必问题,而且会问的很深,所以还是请大家耐心阅读完,并且理解它,死死的掌握住它!因为有些苦迟早要吃的,逃不掉的。)
1.相关类和接口的关系

图片这里是从网上找的,我在这里详细说一下经常使用的和必须要知道的(标黄的是经常使用的)
Executor // 最顶层接口,仅提供execute方法
ExecutorService // 扩展自Executor,提供了对任务的管理能力
AbstractExecutorService // ExecutorService的默认抽象实现
ThreadPoolExecutor // 继承自AbstractExecutorService,是真正的线程池类!!!!
2.创建的方式
ExecutorService executorService = Executors.newFixedThreadPool(10); //创建固定线程数的线程池
executorService.submit(); // 提交任务
executorService.shutdownNow(); // 结束线程池
线程池的创建方式有很多,下面会详细讲解到全部创建方式。
3.ThreadPoolExecutor详解
我们以最后一个构造方法(参数最多的那个),对其参数进行解释:
public ThreadPoolExecutor(int corePoolSize, // 1
int maximumPoolSize, // 2
long keepAliveTime, // 3
TimeUnit unit, // 4
BlockingQueue<Runnable> workQueue, // 5
ThreadFactory threadFactory, // 6
RejectedExecutionHandler handler ) { //7
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
| 序号 | 名称 | 类型 | 含义 |
|---|---|---|---|
| 1 | corePoolSize | int | 核心线程池大小 |
| 2 | maximumPoolSize | int | 最大线程池大小 |
| 3 | keepAliveTime | long | 线程最大空闲时间 |
| 4 | unit | TimeUnit | 空闲时间单位 |
| 5 | workQueue | BlockingQueue | 线程等待队列 |
| 6 | threadFactory | ThreadFactory | 线程创建工厂 |
| 7 | handler | RejectedExecutionHandler | 拒绝策略 |
其中等待队列和拒绝策略需要详细在下面讲解一下,其他的参数顾名思义,相信大家都理解,即便不理解我讲一下线程池的运行流程就明白了。
4.线程池的运行流程
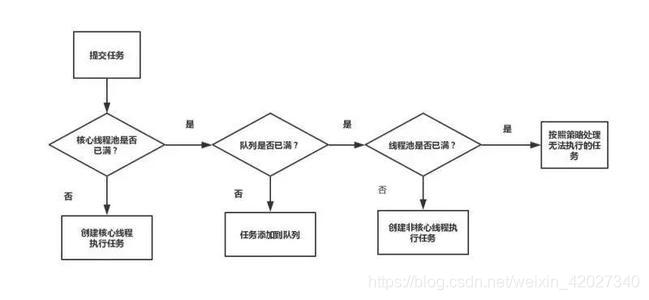
此图是网上随便找的一张,简单易懂。
1.首先会判断线程池的线程是否已经达到参数里设置的核心线程数,如果没有达到则创建线程立即执行任务
2.如果达到核心线程数量了则判断等待队列是否已经满了,如果没满则放入等待队列
3.如果等待队列满了,则判断当前线程是否超过了最大线程数量,如果没有则创建线程立刻执行任务
4.如果已经到达了最大线程数量则根据设置的拒绝策略直接作出相应的拒绝方式。
5.等待队列
等待队列有多种,只要是实现了BlockingQueue的都可以,我讲一下几种常见的:
1.ArrayBlockingQueue; //基于数组的先进先出队列,有界.
2.LinkedBlockingQueue; //基于链表的先进先出队列,无界.(数据无限存入的话有撑爆内存的风险)
3.SynchronousQueue; //无缓冲的等待队列,无界.(容量为0,不存数据)
6.拒绝策略
1.ThreadPoolExecutor.AbortPolicy();//默认,队列满了丢任务 抛出异常
2.ThreadPoolExecutor.DiscardPolicy();//队列满了丢任务 不抛异常
3.ThreadPoolExecutor.DiscardOldestPolicy();//将最早进入队列的任务删除(也就说即将要执行的任务),尝试加入等待队列
4.ThreadPoolExecutor.CallerRunsPolicy();//如果添加到线程池失败,则会让提交任务的线程去执行此任务
5.如果以上四种无法满足你的需求,可以自定义拒绝策略。
在java线程池中实现自定义拒绝策略,只需要实现RejectedExecutionHandler接口就可以了
public class MyRejected implements RejectedExecutionHandler{
public MyRejected(){
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("自定义处理..");
System.out.println("当前被拒绝任务为:" + r.toString());
}
}
7.Executors的五种线程池以及内部实现原理
1.FixedThreadPool(固定大小的线程池)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- corePoolSize与maximumPoolSize相等,即其线程全为核心线程,是一个固定大小的线程池,是其优势;
- keepAliveTime = 0 该参数默认对核心线程无效,而FixedThreadPool全部为核心线程;
- workQueue 为LinkedBlockingQueue(无界阻塞队列),队列最大值为Integer.MAX_VALUE。如果任务提交速度持续大余任务处理速度,会造成队列大量阻塞。因为队列很大,很有可能在拒绝策略前,内存溢出。是其劣势;
- FixedThreadPool的任务执行是无序的;
- 适用场景:可用于Web服务瞬时削峰,但需注意长时间持续高峰情况造成的队列阻塞。
2.CachedThreadPool(缓存线程池)
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- corePoolSize = 0,maximumPoolSize = Integer.MAX_VALUE,即线程数量几乎无限制;
- keepAliveTime = 60s,线程空闲60s后自动结束。
- workQueue 为 SynchronousQueue 同步队列,这个队列类似于一个接力棒,入队出队必须同时传递,因为CachedThreadPool线程创建无限制,不会有队列等待,所以使用SynchronousQueue;
- 适用场景:快速处理大量耗时较短的任务,如Netty的NIO接受请求时
3.SingleThreadExecutor(只有一个线程的线程池)
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- SingleThreadExecutor就是退化了的FixedThreadPool,只是线程数为1而已;
4.ScheduledThreadPool(可以执行定时任务的线程池)
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
- newScheduledThreadPool调用的是ScheduledThreadPoolExecutor的构造方法,而ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,构造是还是调用了其父类的构造方法。
对于ScheduledThreadPool本文不做描述;
5.newWorkStealingPool(JDK1.8新推出的线程池)
newWorkStealingPool,这个是 JDK1.8 版本加入的一种线程池,stealing 翻译为抢断、窃取的意思,它实现的一个线程池和上面4种都不一样,用的是 ForkJoinPool 类,构造函数代码如下:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
从上面代码的介绍,最明显的用意就是它是一个并行的线程池,参数中传入的是一个线程并发的数量,这里和之前就有很明显的区别,前面4种线程池都有核心线程数、最大线程数等等,而这就使用了一个并发线程数解决问题。从介绍中,还说明这个线程池不会保证任务的顺序执行,也就是 WorkStealing 的意思,抢占式的工作。
8.如何设置相对较优的线程数量和总结
- 用ThreadPoolExecutor自定义线程池,看线程的用途,如果任务量不大,可以用无界队列,如果任务量非常大,要用有界队列,防止OOM
- 如果任务量很大,还要求每个任务都处理成功,要对提交的任务进行阻塞提交,重写拒绝机制,改为阻塞提交。保证不抛弃一个任务
- 最优的线程数量设置,要分析你的任务是CPU密集型还是IO密集型或者是否需要等待其他程序响应比如数据库,如果是CPU密集型最好设置最大线程数=N+1最好,N是CPU核数。如果是IO密集型最好设置最大线程数=2N+1最好,因为IO操作的时候是不占CPU的,咱们是目的是尽量不要让CPU闲下来。
- 核心线程数,看应用,如果是任务,一天跑一次,设置为0,合适,因为跑完就停掉了,如果是常用线程池,看任务量,是保留一个核心还是几个核心线程数
- 如果要获取任务执行结果,用CompletionService,但是注意,获取任务的结果的要重新开一个线程获取,如果在主线程获取,就要等任务都提交后才获取,就会阻塞大量任务结果,队列过大OOM,所以最好异步开个线程获取结果
- 根据阿里规范,我们一般开发的时候都是用ThreadPoolExecutor创建线程池,好阅读,操作自由。
