前言
这是我听老师讲课做的笔记,考试要看的。
作者:RodmaChen
关注我的csdn博客,更多数据结构与算法知识还在更新
一. 概念
基本思想
根据问题中的关键字构造一个合适的函数,利用这个函数求得各记录的存储位置,然后存储;在查找时用相同的函数找其元素。
即:Addr(ai)=H(Ki)
其中:
Addr(ai)为ai的存储地址,H为散列函数,Ki为ai的关键字
散列表(哈希表):按散列存储方式构造的存储结构为散列表。
散列函数(哈希函数):H(ki),关键字与表之间的对应关系。
散列地址(哈希地址):散列函数的值。
散列:将结点按关键字的散列地址存储到散列表中的过程,又称哈希造表。
同义词 :k₁ ≠k₂,但H(k₁)=H(k₂),即映射到同一哈希地址上的关键码k1 和k2为同义词。
冲 突:k₁ ≠k₂,但H(k₁)=H(k₂),将不同的关键码映射到同一个哈希地址上,即同义词之间发生地址争夺的现象。
二.构造哈希表
1.直接定址法
取关键字的某个线性函数值为哈希地址。
H(key)=key 或H(key)=a*key+b
例:H(key)=学号-2009100100
2 .数字分析法
把字符型关键词量化,对其中的数字进行分析,谁最均匀就取谁。
3 .除留求余法
H(key)=key%p
p<=m
m 为哈希表的表长
p为不超过m的最大素数
三.处理冲突的方法
1.开放定址法(open Addressing )
所谓开放定址法,即是由关键字得到的哈希地址一旦产生了冲突,也就是说,该地址已经存放了数据元素,就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能找到,并将数据元素存入。
$H_i$=(Hash(key)+$d_i$) mod m i=1,2,…k (k<=m-1)
其中:
H(key)为哈希函数
m为哈希表长度
为增量序列,可有下列3种取法:
- 线性探测再散列
=1,2,3,…,m-1
- 二次探测再散列
= 1²,-1²,2² ,-2²,3²,…,±k², k≤ m/2)
- 伪随机探测再散列
=伪随机数序列
2.链地址法(拉链法 )
设哈希函数得到的哈希地址在区间[0,m-1]上,以每个哈希地址作为一个指针,指向一个链。
每个链表中的结点都是同义词。
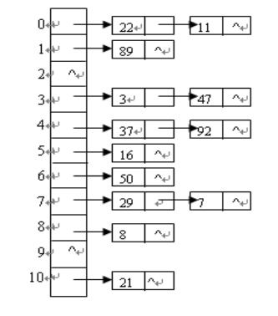
列:关键码序列为47,7,29,11,16,92,22,8,3,50,37,89,94,21
哈希函数为:
Hash(key)=key mod 11
用拉链法处理冲突,如下表所示
四.边学边练
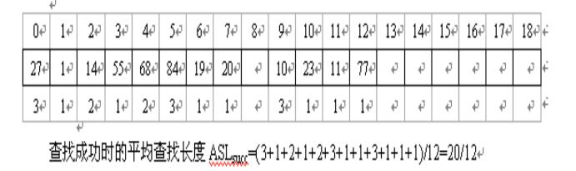
已知查找表为{19,01,23,14,55,20,84,27,68,11,10,77},设定哈希函数为:H(key)=key % 13,采用开放地址法的二次探测法解决冲突,试在0~18的散列地址空间中对该关键字构造哈希表,并求出查找成功时的平均查找长度。
H(19)=19%13=6
H(01)=01%13=1
H(23)=23%13=10
H(14)=14%13=1(冲突) H(14)=(1+1)%13=2
H(55)=55%13=3
H(20)=20%13=7
H(84)=84%13=6(冲突) H(84)=(6+1)%13=7(仍冲突)
H(84)=(6-1)%13=5
H(27)=27%13=1(冲突) H(27)=(1+1)%13=2(仍冲突)
H(27)=(1-1)%13=0
H(68)=68%13=3(冲突) H(63)=(3+1)%13=4
H(11)=11%13=11
H(10)=10%13=10(冲突) H(10)=(10+1)%13=11(仍冲突)
H(10)=(10-1)%13=9
H(77)=77%13=12
因此哈希表如下:

本人博客:https://blog.csdn.net/weixin_46654114
本人b站求关注:https://space.bilibili.com/391105864
转载说明:跟我说明,务必注明来源,附带本人博客连接。
请给我点个赞鼓励我吧
